一文掌握Redis的哨兵Sentinel原理到实战
编程界的小学生
- 一、为什么要有Sentinel
- 二、什么是Sentinel
- 三、该升级谁为M
- 三、什么是脑裂
- 四、实操
- 五、总结
- 六、个人公众号
一、为什么要有Sentinel
是因为我们上篇主从复制中也发现了Master挂了后需要人工去升级Slave为Master,然后让其他Slave作为新升级Master的S,这整个过程都是人为操作的。所以并不是真正意义的高可用,因为机器过多你可能切换半小时,Sentinel就是为了解放人类的,全自动升级Master等一系列操作,这才是真正意义的高可用!
对主从复制以及我说的人工切换的描述不清晰的,请看
一文掌握Redis的主从复制原理到实战
二、什么是Sentinel
sentinel可以认为是一个负责监控的和自动故障转移的一个哨兵,也就是门卫,我时刻守护着大门,出问题我就及时发现,然后自动故障修复(S升级为M)。所以启动脚本里会指定–sentinel参数来告诉Redis此进程不再是一个存储kv的存储引擎,而是一个哨兵。
三、该升级谁为M
问题:Master挂了,该升级哪个Slave为新的Master呢?
一般规定,也建议设置为Redis主从个数的一半以上(也就是2/n + 1),比如1主2从,那就设置为2,1主3从就设置为3,一主4从就设置为3(5 / 2 + 1 = 3)。
疑问:为什么是2/n+1?
因为如果
1.全部哨兵同意才能升级的话,也就是比如3个Redis、3个Redis哨兵必须保证3个哨兵都同意A节点升级为Master才行的话,那很可能第一台哨兵由于自身网络问题导致连接失败,而其他两个都是正常的,那就不升级了?不公平也不合适,因为那个哨兵明明是自身网络问题。
2.一个哨兵同意就升级的话,也就是比如3个Redis、3个Redis哨兵只要保证又1个哨兵都同意A节点升级为Master就可以的话,那也不靠谱,很可能那节点已经挂了,但是哨兵A可能缓存或者其他问题返回正常,但是其他两个哨兵明显发现问题连接不上了等,少数服从多数是最保险最靠谱的。最主要的是一个哨兵同意就可以的话会产生脑裂问题。
三、什么是脑裂
脑子裂开了,一分为二。也就是形容一个Master由于脑裂变成了2个Master的情况。具体如下:
如果1个Master3个Slave组成的哨兵模式(哨兵独立部署到其他机器上的),恰巧这时候Master与3个Slave和其中某1个哨兵之间的网络发生故障,但是Slave和哨兵之间通讯正常。那么如果设置1个哨兵同意就升级的话恰巧这个Master无法通信的哨兵同意了一个Slave升级,然后就升级了,那么这时候就会存在两个Master,因为之前的Master并没有挂掉,只是和你这个哨兵通信不了,和其他的照常。这时候就会造成客户端请求写的话会落到升级之前的Master上,但这个M又没法给Slave同步数据,导致问题。但并不是2/n+1个同意就没脑裂了,只是不易出现了。根治的办法需要这两个参数
# 表示连接到master的最少slave数量
min-replicas-to-write 3
# 表示slave连接到master的最大延迟时间
min-replicas-max-lag 10
按照上面的配置,要求至少3个slave节点,且数据复制和同步的延迟不能超过10秒,否则的话master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。
四、实操
官网很权威:http://redis.cn/topics/sentinel.html
(1)先启动三台Redis,1M2S
这块不懂的转到一文掌握Redis的主从复制原理到实战
redis-server /etc/redis/6379.conf
redis-server /etc/redis/6380.conf --replicaof localhost 6379
redis-server /etc/redis/6381.conf --replicaof localhost 6379
(2)创建三个哨兵
创建哨兵的方法:sentinel <选项的名字> <主服务器的名字> <选项的值>
# 新建26379.config
# 当前哨兵的端口号
port 26379
# 监听Master,最后的2代表上面的:该升级谁为M中的2/n+1,因为3个机器,所以这里是2
sentinel monitor mymaster 127.0.0.1 6379 2
# 新建26380.config
# 当前哨兵的端口号
port 26380
sentinel monitor mymaster 127.0.0.1 6379 2
# 新建26381.config
# 当前哨兵的端口号
port 26381
sentinel monitor mymaster 127.0.0.1 6379 2
(3)启动哨兵
# --sentinel 告诉他你不是一个存储kv的存储引擎了,而是一个哨兵负责监控的
redis-server /etc/redis/26379.conf --sentinel

# --sentinel 告诉他你不是一个存储kv的存储引擎了,而是一个哨兵负责监控的
redis-server /etc/redis/26380.conf --sentinel

这里会多出来一个26379的哨兵,因为上面在【该升级谁为M】中说了,三个哨兵,两个同意A升级 ,那就A升级为M,所以这三个哨兵之间是需要通信的。 这时候再去看刚启动的26379的哨兵的log,也会多出一个26380的哨兵来。

# --sentinel 告诉他你不是一个存储kv的存储引擎了,而是一个哨兵负责监控的
redis-server /etc/redis/26381.conf --sentinel

会发现多出来2个哨兵,分别是26379/26380,同理,回过去看26379和26380的log也会多出26381这个哨兵。
(4)Redis和哨兵都启动完了,进行测试
干掉6379的Redis,让他停止进程。看是否会从6380/6381中选举出来一个作为Master,然后另一个是否会自动作为当前选出来的这个Master的Slave。
出现的结果是6380和6381会报错,因为找不到Master了,大概10s左右会自动选择一个Slave作为新的Master
为什么不立马选举要等10s左右?因为这10S内可能M又恢复了,这时候继续M作为M。网络延迟或者异常重启也可能,所以不立马切换。
如果Slave自动升级成Master后(3个哨兵2个同意6380升级,那就6380。),另外一个Slave会作为新Master的从,刚挂了的主启动后也会自动作为新Master的Slave。
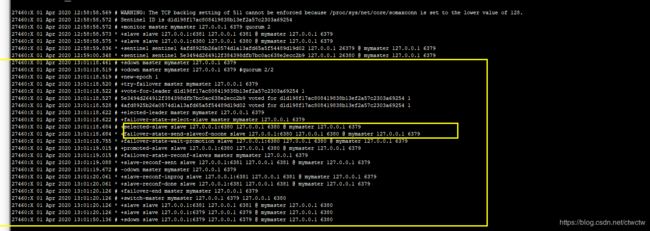
从log中可以发现6380升级为新M,且执行slaveof noone,这个命令就代表是升级为M的。6380是两个哨兵选举出来的。
疑问:哨兵的配置文件写死的6379是Master,还需要手动一个一个的改?
答案:不需要,自动升级和切换完成后,哨兵配置文件会自动被修改。完全解放人力。
(5)补充:哨兵之间是怎么彼此发现的?
上面启动哨兵的时候从log中能发现彼此是感知的,怎么做的?
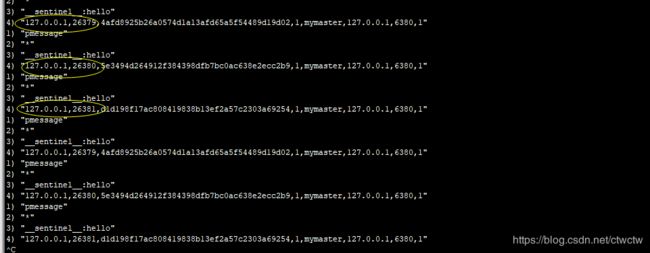
是通过PSUBSCRIBE这个Redis内置的发布订阅来实现的。我们可以开个客户端简单看下
redis-cli
# 这里就*,便于测试
PSUBSCRIBE *
可以发现结果都是26379/26380/26381三者再交互,就是这么实现哨兵之间彼此发现的
五、总结
其实哨兵就是实现HA高可用的,自动故障修复。而不是人力。
六、个人公众号
微信公众号【Java码农社区】
