Python机器学习库sklearn网格搜索与交叉验证
网格搜索一般是针对参数进行寻优,交叉验证是为了验证训练模型拟合程度。sklearn中的相关API如下:
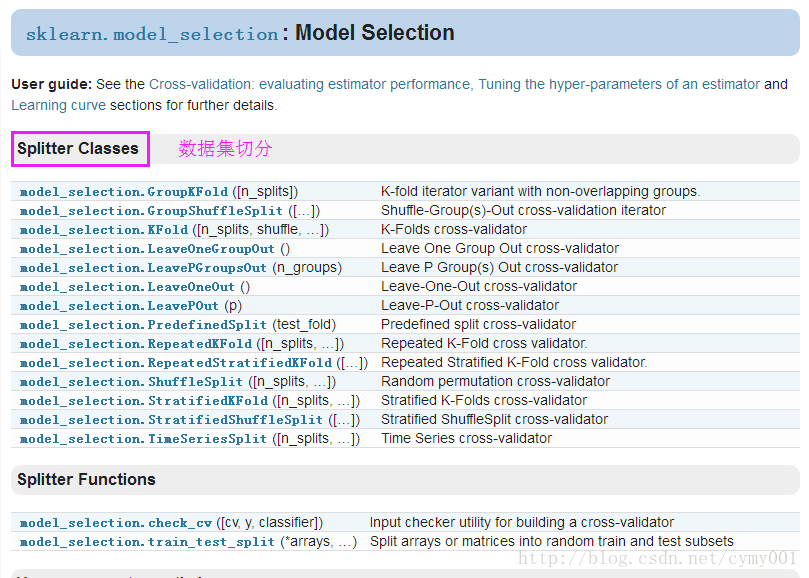

(1)交叉验证的首要工作:切分数据集train/validation/test
A.)没指定数据切分方式,直接选用cross_val_score按默认切分方式进行交叉验证评估得分,如下图

from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
logreg = LogisticRegression()
scores = cross_val_score(logreg, iris.data, iris.target, cv=5)
#默认cv=3,没指定默认在训练集和测试集上进行交叉验证
scores
#Output:
#array([ 1. , 0.96666667, 0.93333333, 0.9 , 1. ])B.)K折交叉验证KFold
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
iris = load_iris()
kfold = KFold(n_splits=5)
cross_val_score(logreg, iris.data, iris.target, cv=kfold)
#Output:
#array([ 1. , 0.93333333, 0.43333333, 0.96666667, 0.43333333])from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
kfold = KFold(n_splits=3, shuffle=True, random_state=0)
#shuffle添加了随机扰动,打乱样本顺序,再进行k折切分样本
cross_val_score(logreg, iris.data, iris.target, cv=kfold)
#Output:
#array([ 0.9 , 0.96, 0.96])C.)留一交叉验证LeaveOneOut(工业实践很少用)
from sklearn.datasets import load_iris
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
scores = cross_val_score(logreg, iris.data, iris.target, cv=loo)
#cv参数Determines the cross-validation splitting strategy,An object to be used as a cross-validation generator.
print("number of cv iterations: ", len(scores))
print("mean accuracy: ", scores.mean())
#Output:
#number of cv iterations: 150
#mean accuracy: 0.953333333333D.)乱序分割交叉验证ShuffleSplit
from sklearn.datasets import load_iris
from sklearn.model_selection import ShuffleSplit
#random splits do not guarantee that all folds will be different, although this is still very likely for sizeable datasets.
shuffle_split = ShuffleSplit(test_size=.5, train_size=.5, n_splits=10,random_state=0)
cross_val_score(logreg, iris.data, iris.target, cv=shuffle_split)
#Output:
#array([ 0.84 , 0.93333333, 0.90666667, 1. , 0.90666667,
# 0.93333333, 0.94666667, 1. , 0.90666667, 0.88 ])E.)数据与分组交叉验证GroupKFold
The same group will not appear in two different folds (the number of distinct groups has to be at least equal to the number of folds).

from sklearn.model_selection import GroupKFold
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])
groups = np.array([0, 0, 2, 2])
gkf=GroupKFold(n_splits=2)
for train_index, test_index in gkf.split(X, y, groups):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print('X_train:',X_train)
print('X_test:',X_test)
print('y_train:',y_train)
print('y_test:',y_test)
#Output:
#TRAIN: [0 1] TEST: [2 3]
#X_train: [[1 2]
# [3 4]]
#X_test: [[5 6]
# [7 8]]
#y_train: [1 2]
#y_test: [3 4]
#TRAIN: [2 3] TEST: [0 1]
#X_train: [[5 6]
# [7 8]]
#X_test: [[1 2]
# [3 4]]
#y_train: [3 4]
#y_test: [1 2]F.)按样本的标签分层切分StratifiedKFold
(2.)有关模型的参数调优过程,即网格搜索/交叉验证
a.)最简单的网格搜索:两层for循环
# naive grid search implementation
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
print("Size of training set: %d size of test set: %d" % (X_train.shape[0], X_test.shape[0]))
best_score = 0
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
# for each combination of parameters
# train an SVC
svm = SVC(gamma=gamma, C=C)
svm.fit(X_train, y_train)
# evaluate the SVC on the test set
score = svm.score(X_test, y_test)
# if we got a better score, store the score and parameters
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}
print("best score: ", best_score)
print("best parameters: ", best_parameters)
#Output:
#Size of training set: 112 size of test set: 38
#best score: 0.973684210526
#best parameters: {'gamma': 0.001, 'C': 100}在训练集上再切出来一部分作为验证集,用于评估模型,防止过拟合

from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
print("Size of training set: %d size of test set: %d" % (X_train.shape[0], X_test.shape[0]))
best_score = 0
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
# for each combination of parameters
# train an SVC
svm = SVC(gamma=gamma, C=C)
svm.fit(X_train, y_train)
# evaluate the SVC on the test set
score = svm.score(X_test, y_test)
# if we got a better score, store the score and parameters
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}
print("best score: ", best_score)
print("best parameters: ", best_parameters)
#Output:
#Size of training set: 112 size of test set: 38
#best score: 0.973684210526
#best parameters: {'gamma': 0.001, 'C': 100}b.)网格搜索内部嵌套了交叉验证
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
iris = load_iris()
X_trainval, X_test, y_trainval, y_test = train_test_split(iris.data, iris.target, random_state=0) #总集——>训练验证集+测试集
X_train, X_valid, y_train, y_valid = train_test_split(X_trainval, y_trainval, random_state=1) #训练验证集——>训练集+验证集
best_score = 0
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
svm = SVC(gamma=gamma, C=C)
scores = cross_val_score(svm, X_trainval, y_trainval, cv=5) #在训练集和验证集上进行交叉验证
score = np.mean(scores) # compute mean cross-validation accuracy
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}
# rebuild a model on the combined training and validation set
print('网格搜索for循环<有cross_val_score交叉验证>获得的最好参数组合:',best_parameters)
print(' ')
svmf = SVC(**best_parameters)
svmf.fit(X_trainval, y_trainval)
print('网格搜索<有交叉验证>获得的最好估计器,在训练验证集上没做交叉验证的得分:',svmf.score(X_trainval,y_trainval))#####
print(' ')
scores = cross_val_score(svmf, X_trainval, y_trainval, cv=5) #在训练集和验证集上进行交叉验证
print('网格搜索<有交叉验证>获得的最好估计器,在训练验证集上做交叉验证的平均得分:',np.mean(scores)) #交叉验证的平均accuracy
print(' ')
print('网格搜索<有交叉验证>获得的最好估计器,在测试集上的得分:',svmf.score(X_test,y_test))#####
# print(' ')
# print(' ')
# scoreall = cross_val_score(svmf, iris.data, iris.target, cv=5)
# print(scoreall ,np.mean(scoreall)) Output:
网格搜索for循环<有cross_val_score交叉验证>获得的最好参数组合: {'gamma': 0.01, 'C': 100}
网格搜索<有交叉验证>获得的最好估计器,在训练验证集上没做交叉验证的得分: 0.982142857143
网格搜索<有交叉验证>获得的最好估计器,在训练验证集上做交叉验证的平均得分: 0.972689629211
网格搜索<有交叉验证>获得的最好估计器,在测试集上的得分: 0.973684210526c.)构造参数字典,代替双层for循环进行网格搜索
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
X_trainvalid, X_test, y_trainvalid, y_test = train_test_split(iris.data, iris.target, random_state=0) #default=0.25
grid_search = GridSearchCV(SVC(), param_grid, cv=5) #网格搜索+交叉验证
grid_search.fit(X_trainvalid, y_trainvalid)
print('GridSearchCV交叉验证网格搜索字典获得的最好参数组合',grid_search.best_params_)
print(' ')
print('GridSearchCV交叉验证网格搜索获得的最好估计器,在训练验证集上没做交叉验证的得分',grid_search.score(X_trainvalid,y_trainvalid))#####
print(' ')
print('GridSearchCV交叉验证网格搜索获得的最好估计器,在**集上做交叉验证的平均得分',grid_search.best_score_)#?????
# print(' ')
# print('BEST_ESTIMATOR:',grid_search.best_estimator_) #对应分数最高的估计器
print(' ')
print('GridSearchCV交叉验证网格搜索获得的最好估计器,在测试集上的得分',grid_search.score(X_test, y_test))#####Output:
GridSearchCV交叉验证网格搜索字典获得的最好参数组合 {'gamma': 0.01, 'C': 100}
GridSearchCV交叉验证网格搜索获得的最好估计器,在训练验证集上没做交叉验证的得分 0.982142857143
GridSearchCV交叉验证网格搜索获得的最好估计器,在**集上做交叉验证的平均得分 0.973214285714
GridSearchCV交叉验证网格搜索获得的最好估计器,在测试集上的得分 0.973684210526d.)嵌套交叉验证:字典参数+cross_val_score
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
scores = cross_val_score(GridSearchCV(SVC(), param_grid, cv=5), iris.data, iris.target, cv=5)
#选定网格搜索的每一组超参数,对训练集与测试集的交叉验证(cross_val_score没指定数据集合分割的默认情况)
print("Cross-validation scores: ", scores)
print("Mean cross-validation score: ", scores.mean())
#Output:
#Cross-validation scores: [ 0.96666667 1. 0.96666667 0.96666667 1. ]
#Mean cross-validation score: 0.98def nested_cv(X, y, inner_cv, outer_cv, Classifier, parameter_grid):
outer_scores = []
# for each split of the data in the outer cross-validation
# (split method returns indices)
for training_samples, test_samples in outer_cv.split(X, y):
# find best parameter using inner cross-validation:网格搜索外层cv
best_parms = {}
best_score = -np.inf
# iterate over parameters
for parameters in parameter_grid:
# accumulate score over inner splits
cv_scores = []
# iterate over inner cross-validation
for inner_train, inner_test in inner_cv.split(X[training_samples], y[training_samples]):
# build classifier given parameters and training data交叉验证内层cv
clf = Classifier(**parameters)
clf.fit(X[inner_train], y[inner_train])
# evaluate on inner test set
score = clf.score(X[inner_test], y[inner_test])
cv_scores.append(score)
# compute mean score over inner folds
mean_score = np.mean(cv_scores)
if mean_score > best_score:
# if better than so far, remember parameters
best_score = mean_score
best_params = parameters
# build classifier on best parameters using outer training set
clf = Classifier(**best_params)
clf.fit(X[training_samples], y[training_samples])
# evaluate
outer_scores.append(clf.score(X[test_samples], y[test_samples]))
return outer_scores
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import ParameterGrid, StratifiedKFold
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
#http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.ParameterGrid.html#sklearn.model_selection.ParameterGrid
#http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html#sklearn.model_selection.StratifiedKFold
#ParameterGrid是按给定参数字典分配训练集与测试集,StratifiedKFold是分层分配训练集与测试集
nested_cv(iris.data, iris.target, StratifiedKFold(5), StratifiedKFold(5), SVC, ParameterGrid(param_grid))
#Output:
#[0.96666666666666667, 1.0, 0.96666666666666667, 0.96666666666666667, 1.0]