kafka集群+filebeat+logstash日志平台搭建
1. 项目需求
搭建一个kafka集群,用filebat收集linux主机日志输出到kafka集群,并通过logstash消费kafka中的数据
2. 环境准备
| 服务器系统 | IP | 角色 |
|---|---|---|
| centos7 | 192.168.149.129 | zookeeper集群、kafka集群 |
| centos7 | 192.168.149.128 | filebeat、logstash |
| 软件 | 版本 |
|---|---|
| zookeeper | zookeeper-3.4.14.tar.gz |
| kafka | kafka_2.12-2.3.0.tgz |
| filebeat | filebeat-7.2.0-linux-x86_64.tar.gz |
| logstash | logstash-7.2.0.tar.gz |
| jdk | jdk1.8 |
3.软件部署
3.1 zookeeper集群搭建
Kakfa集群需要依赖ZooKeeper存储Broker、Topic等信息,这里我们在同一台机器上部署三台ZK,安装位置位于129机器 /data/zookeeper/ 下面的server1、server3、server3
3.1.1 获取 zookeeper-3.4.14.tar.gz 安装包,上传至129机器的/data目录下
3.1.2 分别解压到 server1、server3、server3 中
tar zxvf /data/zookeeper-3.4.14.tar.gz -C /data/zookeeper/
mv /data/zookeeper/zookeeper-3.4.14.tar.gz /data/zookeeper/server1
cp -r /data/zookeeper/server1 /data/zookeeper/server2
cp -r /data/zookeeper/server1 /data/zookeeper/server3
3.1.3 创建数据文件路径
mkdir /data/zookeeper/server1/data /data/zookeeper/server1/logs
mkdir /data/zookeeper/server2/data /data/zookeeper/server2/logs
mkdir /data/zookeeper/server3/data /data/zookeeper/server3/logs
echo "1" >> /data/zookeeper/server1/data/myid
echo "2" >> /data/zookeeper/server2/data/myid
echo "3" >> /data/zookeeper/server3/data/myid
3.1.4 修改配置文件
vim /data/zookeeper/server1/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/data/zookeeper/server1/data
dataLogDir=/data/zookeeper/server1/logs
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
vim /data/zookeeper/server2/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2182
dataDir=/data/zookeeper/server2/data
dataLogDir=/data/zookeeper/server2/logs
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
vim /data/zookeeper/server3/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2183
dataDir=/data/zookeeper/server3/data
dataLogDir=/data/zookeeper/server3/logs
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
zookeeper的三种端口号:
2181:客户端连接Zookeeper集群使用的监听端口号
3888:选举leader使用
2888:集群内机器通讯使用(Leader和Follower之间数据同步使用的端口号,Leader监听此端口)
3.1.5 启动
sh /data/zookeeper/server1/bin/zkServer.sh start
sh /data/zookeeper/server2/bin/zkServer.sh start
sh /data/zookeeper/server3/bin/zkServer.sh start
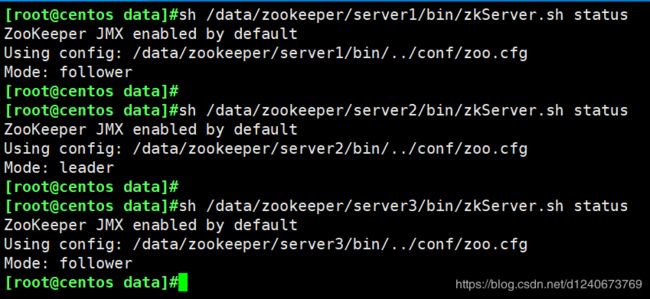
3.1.6 查看启动结果
sh /data/zookeeper/server1/bin/zkServer.sh status
sh /data/zookeeper/server2/bin/zkServer.sh status
sh /data/zookeeper/server3/bin/zkServer.sh status
3.1.7 安装脚本
zk_setup.sh
#!/bin/bash
zkfile="zookeeper-3.4.14.tar.gz"
target_path="/data/zookeeper"
if [ ! -d $target_path ];then
mkdir -p $target_path
fi
#unzip zkfile
tar zxvf $zkfile -C $target_path
#rename
mv $target_path/zookeeper-3.4.14 $target_path/server$1
target_path2=$target_path/server$1
mkdir $target_path2/data
mkdir $target_path2/logs
echo $1 >> $target_path2/data/myid
#config
cat>$target_path2/conf/zoo.cfg<<EOF
tickTime=2000
initLimit=10
syncLimit=5
clientPort=218$1
dataDir=$target_path2/data
dataLogDir=$target_path2/logs
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
EOF
#start
#sh $target_path2/bin/zkServer.sh start
执行安装脚本进行安装:
sh zk_setup.sh 1
sh zk_setup.sh 2
sh zk_setup.sh 3
3.2 kafka集群搭建
3.2.1 将kafka_2.12-2.3.0.tgz安装包上传到服务器/data目录下,并解压,重命名为 /data/kafka
3.2.2 将kafka/config/server.properties复制多份(一个server.properties就是一个broker)
cp /data/kafka/config/server.properties /data/kafka/config/server1.properties
cp /data/kafka/config/server.properties /data/kafka/config/server2.properties
cp /data/kafka/config/server.properties /data/kafka/config/server3.properties
分别修改配置文件:
vim /data/kafka/config/server1.properties
broker.id=0
port=9092
log.dirs=/tmp/kafka1-logs
zookeeper.connect=192.168.149.129:2181,192.168.149.129:2182,192.168.149.129:2183
vim /data/kafka/config/server2.properties
broker.id=1
port=9093
log.dirs=/tmp/kafka2-logs
zookeeper.connect=192.168.149.129:2181,192.168.149.129:2182,192.168.149.129:2183
vim /data/kafka/config/server3.properties
broker.id=2
port=9094
log.dirs=/tmp/kafka3-logs
zookeeper.connect=192.168.149.129:2181,192.168.149.129:2182,192.168.149.129:2183
配置文件参数:
| 配置项 | 默认值/示例值 | 说明 |
|---|---|---|
| broker.id | 0 | Broker唯一标识 |
| listeners | PLAINTEXT://192.168.149.129:9092 | 监听信息,PLAINTEXT表示明文传输 |
| log.dirs | kafka/logs | kafka数据存放地址,可以填写多个。用","间隔 |
| message.max.bytes | message.max.bytes | 单个消息长度限制,单位是字节 |
| num.partitions | 1 | 默认分区数 |
| log.flush.interval.messages | Long.MaxValue | 在数据被写入到硬盘和消费者可用前最大累积的消息的数量 |
| log.flush.interval.ms | Long.MaxValue | 在数据被写入到硬盘前的最大时间 |
| log.flush.scheduler.interval.ms | Long.MaxValue | 检查数据是否要写入到硬盘的时间间隔。 |
| log.retention.hours | 24 | 控制一个log保留时间,单位:小时 |
| zookeeper.connect | 192.168.149.129:2181 | ZooKeeper服务器地址,多台用","间隔 |
3.2.3 启动kafka集群
/data/kafka/bin/kafka-server-start.sh -daemon /data/kafka/config/server1.properties
/data/kafka/bin/kafka-server-start.sh -daemon /data/kafka/config/server2.properties
/data/kafka/bin/kafka-server-start.sh -daemon /data/kafka/config/server3.properties
3.2.4 集群测试
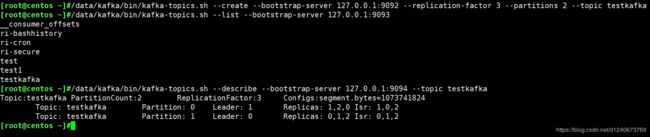
创建topic:
在kafka0(Broker)上创建测试Tpoic:test,这里我们指定了3个副本、2个分区(副本个数不能超过集群个数)
/data/kafka/bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 3 --partitions 2 --topic testkafka
注意:kafka版本大于等于2.2使用 --bootstrap-server 替代 --zookeeper (2.2以上也兼容 --zookeeper)
Topic在kafka0上创建后也会同步到集群中另外两个Broker:kafka1、kafka2
查看topic:
我们可以通过命令列出指定Broker的topic
/data/kafka/bin/kafka-topics.sh --list --bootstrap-server 127.0.0.1:9093
查看指定的topic详情:
/data/kafka/bin/kafka-topics.sh --describe --bootstrap-server 127.0.0.1:9094 --topic testkafka
发送消息:
这里我们向Broker(id=0)的topic=testkafka 发送消息
/data/kafka/bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic testkafka

消费消息:
消费Broker1的消息
/data/kafka/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9093 --topic testkafka --from-beginning

消费Broker2的消息
/data/kafka/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9094 --topic testkafka --from-beginning

均能收到消息,这是因为这两个消费消息的命令是建立了两个不同的Consumer,如果我们启动Consumer指定Consumer Group Id就可以作为一个消费组协同工,1个消息同时只会被一个Consumer消费到,如下:
/data/kafka/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9093 --topic testkafka --from-beginning --group testgroup

/data/kafka/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9094 --topic testkafka --from-beginning --group testgroup

3.3 filebeat配置
vim filebeat/filebeat.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
enabled: true
paths:
- /.cmdlog/cmdlog.*
multiline.pattern: '^20\d\d-\d\d-\d\d\s+\d\d:\d\d:\d\d\s+'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
tags: ["bashhistory"]
fields_under_root: true
fields:
appname: bashhistory
ignore_older: 72h
tail_files: true
close_inactive: 1m
close_timeout: 3h
clean_inactive: 75h
- type: log
enabled: true
paths:
- /var/log/secure
multiline.pattern: '[A-Z][a-z]{2}\s+?\d+?\s+?\d\d:\d\d:\d\d\s+'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
tags: ["secure"]
fields_under_root: true
fields:
appname: secure
ignore_older: 72h
tail_files: true
close_inactive: 1m
close_timeout: 3h
clean_inactive: 75h
- type: log
enabled: true
paths:
- /var/log/cron
multiline.pattern: '[A-Z][a-z]{2}\s+?\d+?\s+?\d\d:\d\d:\d\d\s+'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
tags: ["cron"]
fields_under_root: true
fields:
appname: cron
ignore_older: 72h
tail_files: true
close_inactive: 1m
close_timeout: 3h
clean_inactive: 75h
#----------------------------- kafka output --------------------------------
output.kafka:
hosts: ["192.168.149.129:9092","192.168.149.129:9093","192.168.149.129:9094"]
topic: 'ri-%{[appname]}'
required_acks: 1
#================================ Processors =====================================
# Configure processors to enhance or manipulate events generated by the beat.
processors:
- add_host_metadata:
netinfo.enabled: true
- add_cloud_metadata: ~
- extract_array:
field: host.ip
mappings:
hostipv4: 0
- extract_array:
field: host.ip
mappings:
hostipv6: 1
3.4 logstash配置
vim logstash/logstash.conf
input {
kafka{
codec => "json"
topics => ["ri-bashhistory","ri-cron","ri-secure"]
bootstrap_servers => "192.168.149.129:9092,192.168.149.129:9093,192.168.149.129:9094"
group_id => "ri_linux"
auto_offset_reset => "earliest"
consumer_threads => 3
decorate_events => false
}
}
output {
stdout{} #输出到控制台
file {
path => "/data/logs/%{+YYYY-MM-dd}%{+HH}-%{appname}.log" #输出到文件
codec => line { format => "%{message}" }
}
}
注意:启动logstash,如果报错,可能需要在logstash这台机器上配置kafka服务器的hosts
vim /etc/hosts
