MMIT冠军方案 | 用于行为识别的时间交错网络,商汤公开视频理解代码库


作者 | 商汤
出品 | AI科技大本营(ID:rgznai100)
本文主要介绍三个部分:
一个高效的SOTA视频特征提取网络TIN,发表于AAAI2020
ICCV19 MMIT多标签视频理解竞赛冠军方案,基于TIN和SlowFast
一个基于PyTorch,包含大量视频理解SOTA模型的代码库X-Temporal

本文将介绍一种用于行为识别的时间交错网络(TIN temporal interlacing network)。该网络想较当前SOTA的基础上,在实现6倍加速的同时,还多个评测数据集上获得了4%的提升。同时该方法作为主力方法,在2019年的ICCV Multi Moments In Time challenge中取得了冠军(Leaderboard)。我们还release了一个基于PyTorch的开源动作识别代码库X-Temporal,希望可以进一步推动动作识别社区的发展。
本文工作由港中文MMLab、清华大学与商汤研究院X-Lab联合出品。

简介
行为识别,是计算机视觉领域长期关注的问题,在视频理解、行为检测、手势识别等领域都有着广泛的应用。领域内之前的的工作主要集中在使用卷积神经网络和各种时序模型(例如光流法,循环神经网络和3D卷积)相结合的方式学习时空特征。然而由于这些框架需要交替地学习时间和空间特征,使得它们需要消耗大量的计算资源和时间成本。能稳定提高模型性能的光流法需要用到的光流信息抽取非常耗时,几乎不可能用于实时计算。由此,我们自然而然的产生了一个疑问:那就是我们能否将时间信息嵌入到空间信息中,以便可以一次同时联合学习两个域中的信息。
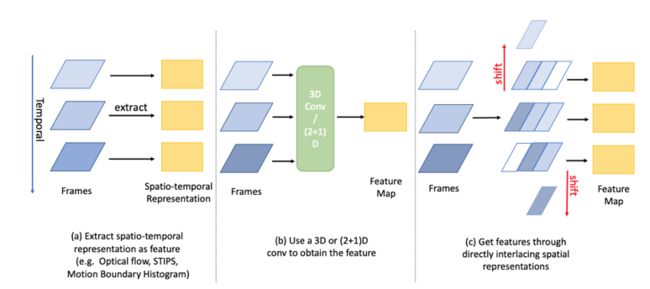
本文提出了一个简单而强大的模块-时序交错网络(Temporal Interlace Network)来尝试解决这个问题。TIN不学习时间特征,而是通过交错过去到未来以及未来到过去的空间特征来融合时-空信息。一个可微分的子模块可以计算出交错时的特征在时序维度上的偏移量,同时可以依据偏移量来将特征重新进行交错排列,使每组特征在时间维度上位移不同的距离。从而用便捷快速的特征位移操作替代了3D卷积来实现相邻帧的信息交换。这使网络的参数量和计算量远低于普通3D卷积网络,使网络整体变得相当轻量化。在文中我们也从理论上证明了可学习的时序交错模块本质上等同于受约束的时序卷积网络。

算法详情
时序交错网络的框架如图二所示,该框架主要由偏移预测网络,权重预测网络和可微时序移动模块组成。其整体将作为一个模块插入到Resnet的卷积层之前。对于整个输入的Feature Map,我们先将其3/4的channel对应的特征固定住,再将余下1/4的特征沿着channel维度分为4组,每组会应用不同的偏移量。
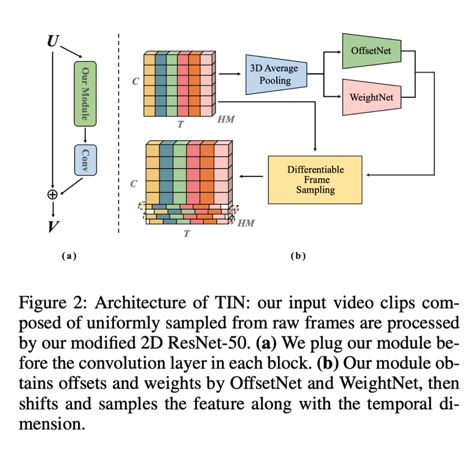
其中偏移预测网络主要负责预测出其中两组沿着T维度的偏移量,然后剩下两组的偏移量是前两组的相反值。这样我们可以保证信息在时序维度上的流动是对称的,更有利于后续特征的融合。权重网络主要负责预测融合后时序维度上特征的权重。如果原始输入是8帧,该网络便会为每组输出8个值分别代表每一帧的权重然后会直接用此值来加权融合过后每一帧的feature。我们也同时发现位于两端的帧所预测的权重大多会比较低,这里我们的猜想是两端的帧的特征在沿着时序移动时由于一边没有其他帧会损失掉一部分,因此导致了网络给他们一个较低的权重来弥补信息损失带来的影响。
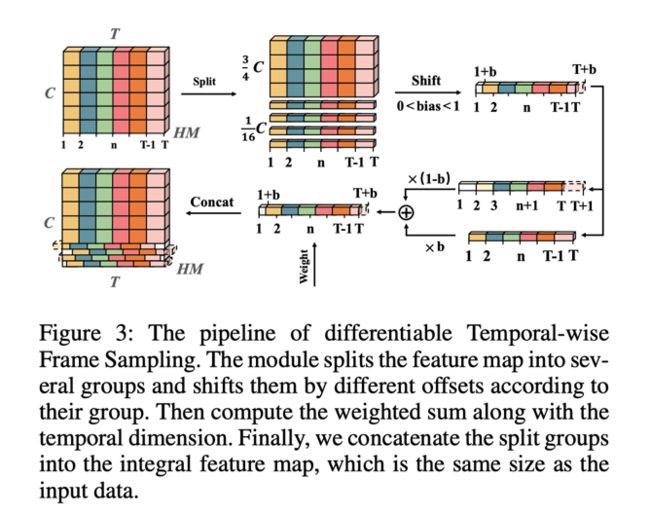
可微时序移动模块的框架如图三所示,它可以将各组按channel维度切分出来的特征沿着时间维度移动任意个单位。其实现方式主要是通过一维线性差值实现的。其中我们还采用了时序扩展技术,以保证偏移之后位于视频之外的特征不为空。举个例子,原本位于T=0的特征在向前偏移0.5个单位后便位于T=-0.5的位置,该位置理论上是不存在特征的,但我们通过假设T=-1位置的特征全为0使位于-0.5的位置取到了特征,也即Feature(T=-0.5) = ½(Feature(T=-1) + Feature(T=0))。

实验
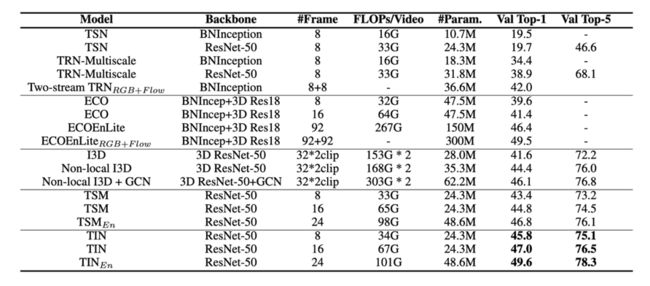
表一对比了在Something-Something v1 数据集上TIN与其他主流模型的性能。在测试性能时每个视频均只采用1 Crop进行测试,且分辨率和训练时保持一致。
可视化结果
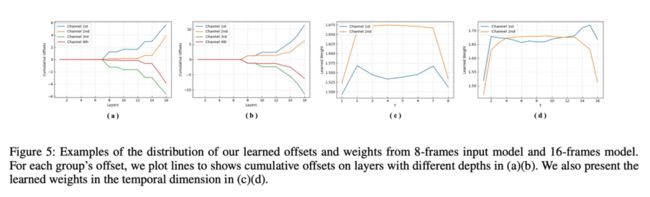
图五将网络学习得到offset和weight进行了可视化分析
。从offset的可视化结果我们可以发现在浅层网络中的偏移量非常小,在网络逐渐变深的过程中学习到的偏移量才逐渐变大。我们认为浅层的神经网络主要学习2D空间特征,在较深的网络中才开始逐渐学习时序维度特征,这和之前3D卷积网络中得到的结论是类似的。
基于TIN的ICCV MMIT比赛方案
在ICCV19 MMIT多标签视频理解竞赛中,我们将TIN与SlowFast算法进行融合,取得了ICCV multi-moments in time challenge竞赛的冠军成绩。ICCV MMIT多标签视频理解比赛旨在对3s短视频中内的动作进行理解。其包含超过100万段视频,并标记了超过200万个动作标签,是目前最大规模的视频理解挑战。巨大的数量与类别,对计算机算法提出了严苛的要求。
我们对2D与3D方法均进行了广泛的尝试。3D方法以SlowFast网络及其变种为主,包括单纯的slow分支,时域密集的fast分支,以及原版的SlowFast。结果下表所示,时域密集的fast分支(32*2)取得了最高的单模型成绩。我们还发现,测试阶段的多尺度以及密集采样可以大幅提高算法性能。
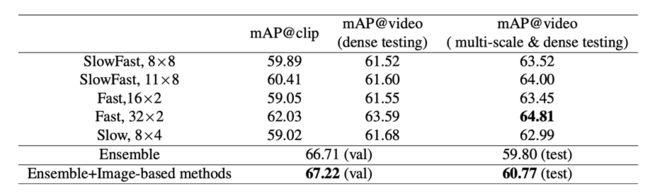
2D方法以我们的方法TIN,我们也尝试了TSN, TSM等方法,结果如下表所示,TIN大幅的提高了动作识别的准确度,在将TIN与3D方法进行融合后,我们在验证集上取得了67.22mAP的成绩,在测试集上取得了60.77mAP的成绩,名列第一(Leaderboard)。

X-Temporal代码库介绍
在上述算法和竞赛的准备过程中,遇到的一个困难是缺乏一个基于PyTorch并广泛支持众多SOTA方案且具有高效训练能力的视频理解代码库。为此,我们开发了X-Temporal repo。其具有以下特征:
1. 支持数据集广泛,并可处理多分类数据集。包括UCF101, Hmdb51, Jester, Kinetics-600, Kinetics-700, Moments in Time , Multi Moments in Time, Something v1, Something v2等。
2. 同时支持处理原视频在线抽帧和抽帧后的图片作为输入,支持多种解码方案。
3. 提供了最新最全的通用视频分类主流方法的实现,包括2D方法 ( TSN, TSM, TIN ) 和3D方法( SlowFast, ResNet-3D, R(2+1)D ), 并在多个数据集取得了SOTA的性能(包含我们在ICCV19 MMIT竞赛第一名的所有model)。
4. 模块化设计使易于添加新的2D或者3D模型。
5. 对部分模型编写了CUDA Operator,大幅提高了其性能。
6. 我们后续会提供基于该库的Model Zoo,方便用户进行Pretrain等操作。
相关链接:
AAAI: https://arxiv.org/abs/2001.06499
Solution: https://arxiv.org/abs/2003.05837
Github: https://github.com/Sense-X/X-Temporal

欢迎所有开发者扫描下方二维码填写《开发者与AI大调研》,只需2分钟,便可收获价值299元的「AI开发者万人大会」在线直播门票!

推荐阅读
前百度主任架构师创业,两年融资千万美元,他说AI新药研发将迎来黄金十年
8比特数值也能训练模型?商汤提训练加速新算法丨CVPR 2020
400 多行代码!超详细中文聊天机器人开发指南 | 原力计划
知识图谱够火,但底层技术环节还差点火候 | 技术生态论
机器学习项目模板:ML项目的6个基本步骤
BM、微软、苹果、谷歌、三星……这些区块链中的科技巨头原来已经做了这么多事!

你点的每个“在看”,我都认真当成了AI