论文解析 | Google如何用CNN检查乳腺癌?

图片来源:New Scientist
翻译 | ziqi zhang
编辑 | Donna
【AI科技大本营导读】前两周,我们分别为大家放送了Luke Oakden-Rayner的《人类医学的终结 - 医学AI研究最前沿》系列文章中关于糖尿病筛查和皮肤癌检测的两篇论文解读。今天我们要推送的是这个系列的最后一篇,涉及了用多视点深度卷积神经网络进行高分辨率乳腺癌筛查,以及在千兆像素级别的图像上检测癌细胞的转移两个方向。
首先,我先来告知之前提到的两个医疗项目的最新进展。目前,Google视网膜病研究小组实际上已经完成了最初的临床试验,并正在印度推广他们的系统。他们正在寻求更多眼科医生的帮助来寻找因为糖尿病而造成不断增长的眼部疾病的患者。对于另外一个研究斯坦福大学的皮肤病研究小组正在开发一款智能手机应用程序来检测皮肤癌。
不得不承认,这些进展比我预期的快得多。但是,虽然成果转换的速度很快,扩散的速度却一直很慢。这两篇大论文是在2016年12月和2017年1月份之间的一个月内发布的。我预计今年会看到另外3-5篇相似的论文,但到目前为止没有进一步的突破。
免责声明:本文主要针对大众化的群体,包括机器学习领域的专家、医生等。相关专家们可能会觉得,我对一些概念的理解很肤浅,可是我还是希望他们能在自己研究领域之外找到更多有趣的新想法。还有一点要强调的是,如果这篇文章里有任何说错的地方,请读者告诉我,我会及时改正。
Wally在哪?
今天,我们将要探讨一种“合适的”医学图像——即病理学和放射学图像。 我对今年所有发表的医学论文进行整理,对其中涉及如何处理医学图像从而提取有用的信息的内容进行了提炼。
我们之前几乎查看了所有的医疗图像数据集。但是我们并没有真正考虑图像本身所存在的问题。医疗图像是真的存在问题的。这些照片相对来说太大了,我们所关心的事情,其实特别小特别的微妙。这就是我们所说的“Wally在哪”问题。Wally越小,长得像Wally的就越多,也就越难找到他。

首先,由于医学所研究的问题,大多都是非常微妙的问题。很多疾病,即便看起来是正常的组织,只是有一点不同。就像在难度最大的“Wally在哪”照片中,每个人都是红白相间的。正确答案与错误答案之间往往就是一些最细微的变化。你当然不会想要丢弃图像中10个像素中的9个,因为那样的话,Wally独一无二的特征就会消失。
论文一:用多视角深度卷积神经网络进行高分辨率乳腺癌筛查
原文链接:https://arxiv.org/abs/1703.07047
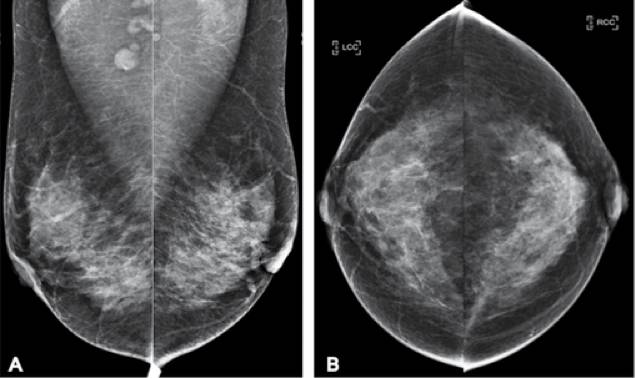
用多视点深度卷积神经网络进行高分辨率乳腺癌筛查
图二 筛查乳房X线照相的例子。这是一个病人的从不同角度拍摄的四张照片。她有一个肿瘤,但是它不是A顶部的圆形位置,它在左乳房中的灰色部分,看起来就像其余的灰色部分。通过观察乳房X线照是很难发现这种细微的差距
这篇文章十分有趣,论文的标题类型说明了我们想要知道的一切——他们使用深度学习的方法,用高分辨率的方式在每个病例中以多个不同的图像视角来查看乳房X线照片,并将其应用于乳腺癌的筛查。
下面是我列出的几条在我以前的报告中经常会提到的一些可能出现的问题:
1.论中分析了一些单个图像,但是大部分的医疗任务中都会使用很多图像进行分析。
2. 文中提到的方法丢弃了图像中的大部分像素,而只是希望真正有用的信息不会被丢失。
3. 文中提到的方法是对临床人群的训练模型进行的训练。但是对于筛查人群中,疾病的流行率却非常得低(通常低于1%),这样的话分类算法就不能有效的进行。
在我们探讨这些问题之前,我们来看看这篇文章的全部内容。
任务
他们训练了一个人工智能系统来对乳腺癌进行筛查。这个系统能够将乳房X线照片分为临床类别BI-RADS 0,1或2型。BI-RADS评分系统是一种十分常见和有效的评估乳房X线照片恶性肿瘤风险的结构化方法。
但是事实上,BI-RADS是一个从0到5的评分系统。有关恶性肿瘤的病变评分为3+。 所以他们根本没有评估恶性肿瘤,他们检查扫描的照片是否正常(1)代表正常(2)代表有“良性”病变(0)代表尚不能确诊。不用你说,我知道这不是一个很有趣的临床任务,从机器学习的方面去考虑这些样本甚至都没有确切的标注。
数据
他们有二万三千张乳房X线照片,是我们前两篇文章的提到的数据集大小的六分之一。 请注意,他们将其数据集描述为超过100,000个图像,但由于每个对象都有4个或者更多的图像,所以这不是一个有效的测量方法。
实际上他们只有1.8万名患者(有些患者有一个以上的乳房X线照片),但只要确保同一个患者的照片不会在训练和测试中同时出现,那就没有问题。因此在训练数据集中严禁出现已测试数据。
然而,他们所面临的一个最重要的挑战是疾病的发生率。
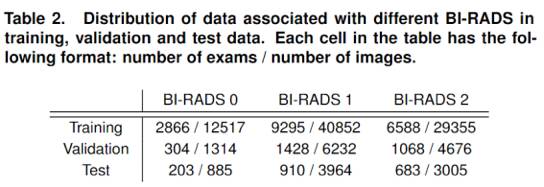
在前两个训练小组(BI-RADS 1,BI-RADS 2)中他们总共有3.9和6.5万的训练图像。虽然这样有点不平衡,但是也不算特别糟糕。但是在这之后的三个训练小组中,各个类别的患病率迅速下降。BI-RADS 3的恶性肿瘤发生率约为5-10%,BI-RADS 4低于2%,BI-RADS 5低于1%。 因此,如果他们想得到“可疑的恶性肿瘤”病例,在二万三千个乳房X光检查中,他们只有两千个例子,其中还有大约二百个是高度可疑的。
更糟糕的是,这种筛查通常是敏感的,但并不具体。 这意味着我们倾向于假阳性的患者(对没有癌症的患者进行活检)超过假阴性的患者(完全忽略癌症)。在筛查人群中,实际癌症的患病率大约是0.3%,因此他们的数据中可能只有60例确诊的乳腺癌样例。
我之前曾经说过一个非常重要的经验法则就是:你需要至少1000个训练样本,才能使深度学习很好地发挥它的作用。即便如此,如果你的数据越多那么效果就会越好。最近的研究实际上表明,你可以通过对数的方式获得更多的数据,从而使深度学习更好地工作。
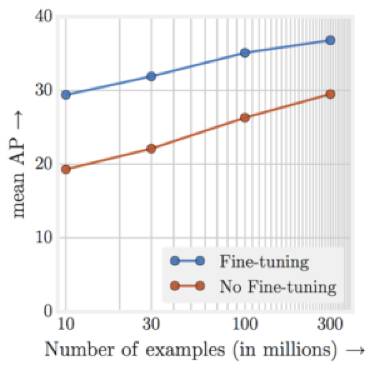
图三 性能随着样本的数量不断地上升
这也就意味着,即使你有一个涵盖2万多个病例的大型临床数据集,也远远不够满足训练任务,无法构建高质量的预测系统来解决医疗问题。在临床数据集中,将所有情况都考虑在内的话,0.3%的疾病流行率实际上也算是相当高的了。
由于数据的极度缺乏,本文并没有达到很好的效果。但是,我们还是能从这篇文章中学到一些东西。
图像大小
这篇论文有一个很有意思的地方是,他们使用了全尺寸的乳房X线照片,甚至他们同时还测试了缩小图像的效果。
正如你所看到的那样,随着图像分辨率的提高,不断上升的正确率趋势是相同的。
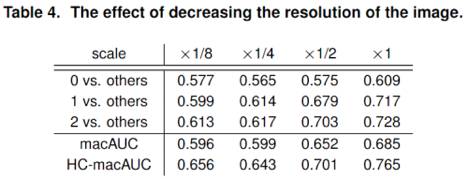
就上下文而言,他们的乳房X线照片是2000 x 2000像素,即4百万像素。 它们的缩放适用于两个方向(即水平方向和竖直方向),所以它们的1/8缩放倍率大概是我们在过去两周讨论的图像的大小(250 x 250像素)。因此,你可以看到性能差异十分明显。
这是这篇文章带给我最有用的信息。对于这种特殊的医疗任务,至少对于通过乳腺X线照片来筛查乳腺癌这个任务,使用全分辨率图像比使用经过下采样处理后的图像效果会更好。
下面是我列举出的两个主要的问题,这两个问题有可能是对于放射学和药物学上的问题具有普遍性:
使用预先训练过数百万只猫和狗图片的系统,它的好处并不像我们想象的那么明显,因为这样做会迫使我们丢弃图像中95%或者更多的像素。
我们需要弄清楚用什么样的方法才能有效地对这样大尺寸的图像进行处理。
第二个问题尤其值得重视。因为训练一个医学深度学习系统往往受到显卡上内存大小的限制。如果你使用小尺寸的图像作为样本对一个较大的模型进行训练,你一次能够在一张顶配的显卡上部署几百张照片。
但是,当图像是4百万像素的时候,常用的图像小批量集合再随机梯度下降的方法会受到很大的挑战,你无法想象每个三维扫描图像具有20兆像素会有多糟,甚至更糟的是四维扫描图像...
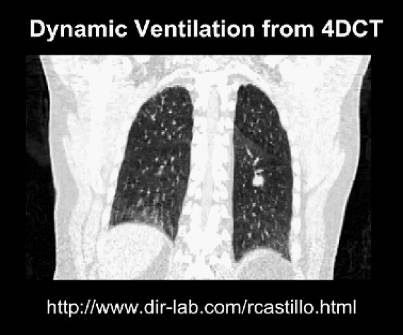
图四 四维成像是三维扫描的时间序列。这可能会导致相比三维研究多出数百或数千倍的数据
有的医学图像可以做的非常之大,有的可能达到千兆像素级别,有的甚至包含像素(二维)、体素(三维)和时素(四维)在同一个样本当中。在我们自己的工作中,当我们对一个平均大小的模型进行训练的时候,通常每个GPU同时只能容纳下一到两个样本。
为此,有的人使用更厉害的方法改进算法,从而减少显卡内存的占用,有的直接使用现金购买大量的GPU组成集群(你通常能够见到那种需要十几块GPU训练网络的例子)。不过,对于大多数非医疗机构的深度学习公司和研究机构,这不是问题,因为他们的图像样本达不到那么大的尺寸。
所以,对于寻找特别细微的Willy,保持高分辨率是值得的,但是这仍然存在自身的问题,因为当分辨率足够高的时候,Willy就有可能变成图像中细小的一部分。反正,当我们看见通过显微镜图像去寻找乳腺癌细胞的文章出现得到时候,再考虑这个问题也不迟。
论文二:用Gigapixel病理图像检测癌症转移
原文链接:https://arxiv.org/abs/1703.02442
在千兆像素级别的图像上检测癌细胞转移
如果说乳房X射线检查是在寻找一张图像中细小的Wallies,那么组织病理学诊断是在一个巨大的人群中找到一个微小的Wally。
我可以用很多论文来讨论组织检测自动化,但是这个论文提出了一个目前最先进的也是最优的方法,并且涵盖了一些我们之前讨论的相关问题。在这篇论文中,他们尝试通过从乳腺癌手术中取出的淋巴结组织的显微镜照片,来鉴别癌细胞簇。其他团队也已经使用相同的基础数据集,在Camelyon16挑战中把癌细胞检查出来。
另外,这是来自于Google的另一篇文章。 他们现在在医学图像分析领域处于绝对的领先地位。 实际上,甚至还有一位作者与之前提到的检测视网膜病变的文章内容非常类似的——Lily Peng,一直在与谷歌团队一起合作做一件超级酷的工作。

图六 我想知道是否可以拉上Hinton,然后把博客引用到同行评审的论文中去?
组织学检测提出了一个这样的问题,在一个大型的图片中找到细微的结果,这些大型的图像有时候甚至可以达到十亿数量级像素(根据标题得出),而这么大的图像中却只有非常少量的恶性肿瘤细胞,比方说十一个。
即使是最理想的情况,我们期望在数百万张片子中找到一个单个的恶性肿瘤细胞,相当于在十亿像素的图像中希望找到数十个。
在这篇论文中,他们量化了他们任务的难度,在其他论文中这是一种并不总是包含的信息,但是我十分欣赏这种做法。他们认为,在每张片子含恶性肿瘤细胞的百分比范围从0.01%到70%,中位数为2%。 不仅如此,这些肿瘤细胞并不全是连续的,而是由许多小的细胞群组成。这就好像是站在远处从一个人群中挑出特定的面孔。

图七 即使是对于人类来说,识别微小的面孔也相当困难。 如果ImageNet就像左边的照片那样,那么组织学分析就像右边的照片。
让我们来看看他们如何处理这个特别困难的任务。 考虑到每个细胞只有几十个像素尺寸的大小,它们当然不能丢弃非常多的像素来训练这些千兆像素的图像。他们的解决方案是将图像分割成适合GPU进行训练的小块尺寸图像,并且可以以全分辨率进行分析处理。
但是,这里有一个很大的限制——只有经过像素级别的数据标注以后才能这样做。 每个癌症集群都必须被精确地标识它们的位置信息。 通常是通过一种边界框,就像上图所示的绿色和黄色的框。 如果没有这个级别的细节标注信息,你不能确定在一个正类的样本图像中究竟包含的癌细胞是哪些。
因此我们自然而然地就会想到这种方法所带来的问题。 做边界框标注比单独确定阳性病例所需要的时间会更长,双倍,三倍,一百倍甚至更长。较早以前我曾经经历过一个项目,我整整花费了一个小时才标注了一个解剖标签。 这就是为什么大多数医疗数据集是如此之小的原因,你很难找到愿意把数周或者数月的时间都花在繁琐的标签任务上的医生。
像往常一样,我们先来看看数据。
数据
这个研究之所以不能称得上是医疗人工智能的突破,一个重要的原因就在于它没有足够多的数据。
他们总共使用了400个公共数据集,其中270个具有可以直接拿来进行训练的边界框。 这就剩下了130个用来做测试的测试数据集。 他们还获得了当地的临床数据,用来构建了第二套包含110个病例的测试数据集,这在医学研究中也是非常好的实践(从不同的病人组中抽取真实数据对于任何可信度水平来说都是非常有必要的)。
值得注意的是,虽然他们总共只有510个样本,但是这仅仅代表整个图像级别的数据。 事实上,由于他们的系统接受分割的图像作为训练数据,在分割图像级别,他们总共拥有100,000多个样本,共采集到88例患者的样本数据用来训练,最终分割后的图像数据能达到87万个包含肿瘤细胞的图像数据。
这对于组织学起着至关重要的作用,因为癌细胞的位置是不变的,在每个分割图像中都有相同的潜在癌细胞的可能。
如果我们的任务是在腹部CT照片上寻找阑尾炎,那么没有必要分割肝脏上的样本图像来增加数据集的大小。 因为阑尾是局部的,它几乎不可能转移到肝脏上来。
这意味着基于样本图像分割的训练只在有限的情况下才有用,但是一旦这种方法适用的话,这是一种扩大数据集的好方法。
结果
虽然这个研究没有称得上是医疗人工智能的突破,但是它也有一些值得我们关注的有趣的点。

让我们来看一下结果中病理学家的正确率的曲线。
这些可能不应该和FROC和@ 8FP分数一样,因为这是两回事。此外报告还说明,病理学家通过对130个病例进行的30个小时的分析,才检测到所有癌症集群的73%。
不过,根据目测,人工智能系统可以在短短几秒钟内检测到93%左右的肿瘤细胞。 这似乎是人工智能系统战胜人类的一个典型的例子,不是吗?
但是,这里面其实是有一个权衡问题。深度学习系统不是病理学家,他们从未检测过健康正常的癌症片子。所以,深度学习系统每检测一个片子就会有八个假阳性病例出现。
这就是Willy在哪问题的另一个分析角度,它涉及到流行性问题。简而言之,疾病的流行性问题,也就决定着你频繁地患病。即使你能够正确识别所有阳性病例,并且每100例阴性病例中仅仅误诊一个阴性病例,每100例阴性病例中存在1例阳性病例,那么你的疾病诊断的正确率仅为50%。
查看数据集,我们知道这个结论是正确的,即使每个图像都有相似的效果。在这项研究中,他们对每张片子都会做出10,000次预测,尽管假阳性率很低。
如果真的有的话,病理学家零失误的诊断这一的事实也是不可思议的,同时它也表明存在0.9999这样的特殊性。
现在,我们可以从Camelyon16的挑战赛中得知,对于相同的数据,Google团队已经达到了最佳的结果。

图上是哈佛大学和麻省理工学院组成的队伍赢得挑战的结果。他们用图像分割的手段在FROC评估方面要比Google论文提出的方法得分低。但即使如此,你也可以看到他们的灵敏度@ 0.25FPs远低于以零阳性误诊率著称的病理学家的结果。
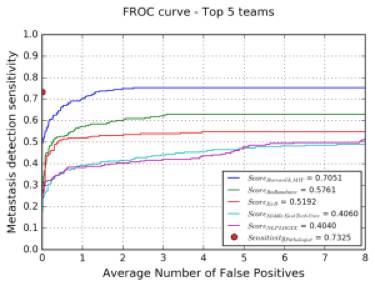
蓝线是哈佛/麻省理工学院的团队的结果,当错误阳性样本的数量接近零时,可以看到灵敏度迅速下降。事实上,在假阳性病例接近0的时候,他们只能检测到约50%的癌症病例。谷歌的结果会比这更好,不过还是会比病理学家的判断结果差一点儿。
影响
这个系统不完美,但并不意味着它一点用处都没有。
这是因为电脑模型比人们更灵活:我们可以选择一个操作点,然后让系统更好地实现诊断任务。
这个系统能在一秒钟之内判断出癌症,并且有了更多的数据,癌症检出率可以提高到99%以上,即使其中不排除有过度诊断的问题。这是远远快于人类的速度。
我觉得可以发明一个筛选工具,将可疑区域突出以供病理学家做进一步诊断。
我曾经向一个病理学的同事请教过这项技术能否用于临床。他说,虽然他们也尝试过这样做,但是一些疾病专家更倾向于用第二种染色方法(细胞角蛋白抗体)。因为,当人类专家使用H + E染色的片子进行诊断时,他们所用时间更少(少于10-20分钟),表现更优。
而本文介绍的人工智能系统在识别2mm以上恶性肿瘤细胞的转移时具有100%的FROC率,在临床上,这是一个接近完美的精度。

后续
今天,我们可以看到的论文中介绍的方法没有达到人类的水平。 在第一个例子中,他们甚至没有尝试将其应用到一个实际的临床任务上。 在第二个例子中,他们创造了一个也许在未来会变得有用(甚至可能取代一些病理学家的工作)的系统,但就目前而言它还不能代替人类专家的工作。
我们目前的困境在于,第一疾病的流行率低,第二我们目前还不能完全掌握如何使用大尺寸图像对系统进行有效的训练。
可惜的是,迄今为止还没有任何一个人在临床任务上发表一个具有人类表现的系统,它可以使用全尺寸的医疗图像,而且该系统可以发现图像中一些细微的差距。
当然,很多团体正在为之努力。也许不久的将来,人工智能在医疗方面会有一个突破性的进展。
一分钟总结
医疗图像处理问题,通常会带来其他图像人工智能领域所不必考虑的一些具体的问题,其中之一就是“Willy去哪”问题。医疗图像往往是尺寸巨大的,而疾病通常发生在特别细微的地方。
在医疗任务中,通过丢弃像素来缩小图像的方法会损害系统的表现,这意味着预训练不再适用。
尺寸巨大的图像在技术上带来了巨大的挑战,但是深度学习的硬件正在努力应对这个挑战。
解决这些挑战的一种方法是通过基于图像分割的训练,但是这会增加数据集收集的时间和成本。
临床人群疾病发病率低意味着我们经常需要大量的数据集才能找到足够的阳性病例样例。但是如果数据集真的存在,这也会大大增加成本。
医疗人工智能系统在某些特定方面比人类专家更灵活,即使他们现在还不能完全达到人类的水平,但还是有可取之处的。
作者 | Luke Oakden-Rayner
原文 | https://lukeoakdenrayner.wordpress.com/2017/10/09/the-end-of-human-doctors-the-bleeding-edge-of-medical-ai-research-part-3/
热文精选
这三个普通程序员,几个月就成功转型AI,他们的经验是...
干货 | AI 工程师必读,从实践的角度解析一名合格的AI工程师是怎样炼成的
谈深度学习必谈计算力!如何成为一名异构并行计算工程师?
干货 | 成为一名推荐系统工程师永远都不晚
AI校招程序员最高薪酬曝光!腾讯80万年薪领跑,还送北京户口
谷歌AI正式来中国了,机器学习三大职位正在招聘...如果你想跟李飞飞一起工作的话
算法还是算力?周志华微博引爆深度学习的“鸡生蛋,蛋生鸡”问题
详解 | 如何用Python实现机器学习算法
经验 | 如何高效学Python?
如何成为一名全栈语音识别工程师?
Twitter大牛写给你的机器学习进阶手册
