一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称:爬取人口数据及数据可视化
2.主题式网络爬虫爬取的内容与数据特征分析:爬取国家统计局人口数据
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点):首先找到爬取页面的源代码,找到所需要爬取的数据在源代码中的位置,接下来进行数据爬取,并将数据持久化,接下来对数据进行清洗处理,并进行数据分析和可视化
首先是页面如下
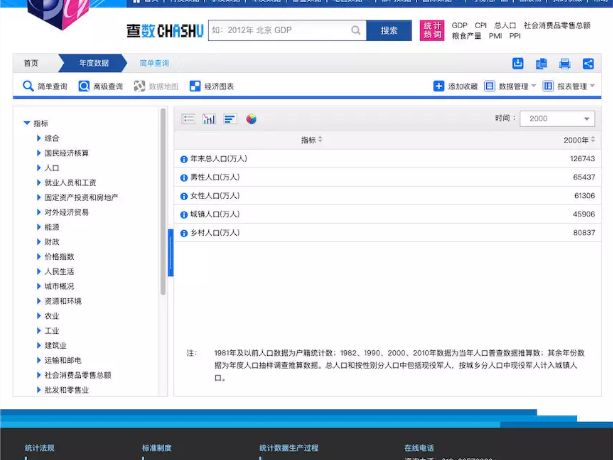
按f12
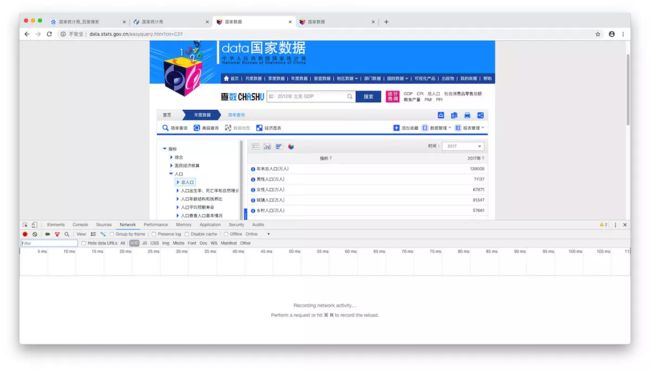
找到人口数据
1.数据爬取与采集(20)
import requests
import time
import json
import matplotlib.pyplot as plt
import pandas as pd
#用来获得 时间戳
def gettime():
return int(round(time.time()*1000))
if __name__=='__main__':
"一,请求数据"
#用来定义头部
headers={}
#用来传递参数
keyvalue={}
#目标网址
url='http://data.stats.gov.cn/easyquery.htm'
#头部填充
headers['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) '\
'AppleWebKit/537.36 (KHTML, like Gecko)'\
'Chrome/70.0.3538.102 Safari/537.36'
#参数填充
keyvalue['m'] = 'QueryData'
keyvalue['dbcode'] = 'hgnd'
keyvalue['rowcode'] = 'zb'
keyvalue['colcode'] = 'sj'
keyvalue['wds'] = '[]'
keyvalue['dfwds'] = '[{"wdcode":"zb","valuecode":"A0301"}]'
keyvalue['k1'] = str(gettime())
# 发出请求,使用get方法,这里使用我们自定义的头部和参数
r = requests.get(url, headers=headers, params=keyvalue)
"二,解析数据"
year=[]
population=[]
data=json.loads(r.text)
data_one = data['returndata']['datanodes']
for value in data_one:
if('A030101_sj' in value['code']):
year.append(value['code'][-4:])
population.append(int(value['data']['strdata']))
print(year)
print(population)
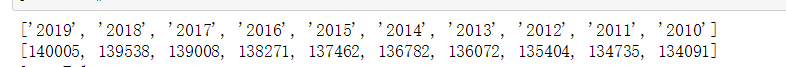
2.对数据进行清洗和处理(10)
#检查重复
print(df.duplicated())

4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)(15分)
plt.figure()
plt.plot()
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.bar(year,population)
plt.xlabel('年份')
plt.ylabel('万人')
plt.title('年末总人口')
plt.show()

5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)(10分)。
6.数据持久化(5分)
将爬取的数据保存在111.csv中
df = pd.DataFrame({'year' : year, 'population' : population})
df.to_csv("C:/Users/lenovo/111.csv", index=False, sep=',')

7.将以上各部分的代码汇总,附上完整程序代码
import requests
import time
import json
import matplotlib.pyplot as plt
import pandas as pd
#用来获得 时间戳
def gettime():
return int(round(time.time()*1000))
if __name__=='__main__':
"一,请求数据"
#用来定义头部
headers={}
#用来传递参数
keyvalue={}
#目标网址
url='http://data.stats.gov.cn/easyquery.htm'
#头部填充
headers['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) '\
'AppleWebKit/537.36 (KHTML, like Gecko)'\
'Chrome/70.0.3538.102 Safari/537.36'
#参数填充
keyvalue['m'] = 'QueryData'
keyvalue['dbcode'] = 'hgnd'
keyvalue['rowcode'] = 'zb'
keyvalue['colcode'] = 'sj'
keyvalue['wds'] = '[]'
keyvalue['dfwds'] = '[{"wdcode":"zb","valuecode":"A0301"}]'
keyvalue['k1'] = str(gettime())
# 发出请求,使用get方法,这里使用我们自定义的头部和参数
r = requests.get(url, headers=headers, params=keyvalue)
"二,解析数据"
year=[]
population=[]
data=json.loads(r.text)
data_one = data['returndata']['datanodes']
for value in data_one:
if('A030101_sj' in value['code']):
year.append(value['code'][-4:])
population.append(int(value['data']['strdata']))
print(year)
print(population)
#检查重复
print(df.duplicated())
df = pd.DataFrame({'year' : year, 'population' : population})
df.to_csv("C:/Users/lenovo/111.csv", index=False, sep=',')
"三,绘制数据"
plt.figure()
plt.plot()
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.bar(year,population)
plt.xlabel('年份')
plt.ylabel('万人')
plt.title('年末总人口')
plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过对主题数据的分析与可视化,可以得到中国人口数据增长情况
逐年在上涨
2.对本次程序设计任务完成的情况做一个简单的小结。
经过这次的学习与作业实践,学到了很多爬虫的知识,不过还是远远不够的。
自己还有很多不懂的地方,还需要继续学习