hadoop完全分布式搭建HA
配置,格式化nn启动,同步,启动所有zk,用ZKFC格式化zk,全部启动
第二次以后启动只需要:启动zk,再start-dfs.sh
1,system:jdk,ssh
2,Hadoop:jdk
2,ha:
hdfs:
1,nameservice。。。。
2,jn
3,failover
4,auto 》 true
core
fs:nameservice
zk:
zookeeper start
3,jn
4,format,start,另一台:同步
5,formatZK
6,start-dfs.sh
在这里我还是要推荐下我自己建的大数据学习交流qq裙:522189307 , 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴。上述资料加群可以领取
HA高可用集群结构
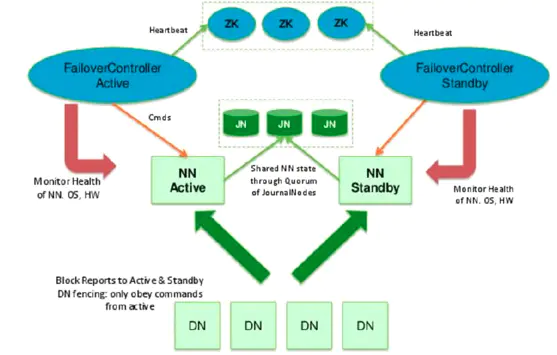
HA集群结构
| 主机名 | 机器ip | NN | NN2 | DN | ZK | ZKFC | JNN |
|---|---|---|---|---|---|---|---|
| node001 | 192.168.118.101/24 | * | * | * | |||
| node002 | 192.168.118.102/24 | * | * | * | * | * | |
| node003 | 192.168.118.103/24 | * | * | * | |||
| node004 | 192.168.118.104/24 | * | * |
HA模型SNN没有意义了,功能由NN2实现了
ZKFC不是规划的,2个NN必然会启动;
2只手,2台NN相互之间要免密钥,各自也要免密钥
都有第3只手控制对方
SSH免密钥需求场景
① 管理脚本远程管理其他节点
② 控自己:ZKFC各自控制节点(把自己up)
③ 控对方:ZKFC控制节点之间(把对方down)
[root@node002 opt]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
[root@node002 opt]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[root@node002 opt]# scp ~/.ssh/id_dsa.pub node001:~/.ssh/node002.pub
[root@node001 .ssh]# cat node002.pub >> authorized_keys
HA高可用集群环境配置
备份全分布式环境:[root@node001 etc]# cp -r hadoop hadoop-full
删除SecondNameNode配置
(1)hdfs-site.xml:逻辑到物理的映射
一个入口找到2个主机位置
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
node001:8020
dfs.namenode.rpc-address.mycluster.nn2
node002:8020
dfs.namenode.http-address.mycluster.nn1
node001:50070
dfs.namenode.http-address.mycluster.nn2
node002:50070
(2)hdfs-site.xml:JN位置信息配置
同步edits.log
2个NN要知道JN在那里,和它通信
管理节点知道到那启动JN,以及把数据放到那个目录下
可以为多个集群提供服务!
dfs.namenode.shared.edits.dir
qjournal://node001:8485;node002:8485;node003:8485/mycluster
dfs.journalnode.edits.dir
/var/hadoop/ha/jn
(3)hdfs-site.xml:发生故障切换时,代理实现方法,免密钥实现方法
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
(4)hdfs-site.xml:自动故障转移
在NN上自动启动ZKFC
dfs.ha.automatic-failover.enabled
true
(5)core-site.xml
告诉集群zk在哪里
注意:hadoop.tmp.dir的配置要变更:/var/hadoop/ha
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/var/hadoop/ha
ha.zookeeper.quorum
node002:2181,node003:2181,node004:2181
客户端开发,保证core-site.xml,hdfs-site.xml都被客户端加载
修改过的配置文件分发:
[root@node001 hadoop]# scp hdfs-site.xml core-site.xml node002:`pwd`
[root@node001 hadoop]# scp hdfs-site.xml core-site.xml node003:`pwd`
[root@node001 hadoop]# scp hdfs-site.xml core-site.xml node004:`pwd`
配置文件:hdfs-site.xml、core-site.xml
2个NN如何格式化?
1、先把JN启动集群:
2、随便找1个NN格式化,启动
3、启动另1NN再同步,去同步集群的描叙信息,不用格式化了,ID一致
4、先启动ZK,再让ZKFC格式化它(不格式化zk,ZKFC启动就有问题)
5、启动所有服务
# (1)先启动所有的JN
[root@node003 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-journalnode-node003.out
[root@node003 ~]# jps
2023 QuorumPeerMain
2206 Jps
2160 JournalNode
# (2)格式化node002,再启动
[root@node002 ~]# hdfs namenode -format
[root@node002 ~]# hadoop-daemon.sh start namenode
[root@node002 ~]# jps
4537 NameNode
4607 Jps
4163 QuorumPeerMain
4340 JournalNode
# (3)同步集群信息
[root@node001 ~]# hdfs namenode -bootstrapStandby
[root@node001 ~]# jps
2975 JournalNode
3412 Jps
# (4)已经启动zk,让ZKFC格式化;随便在那个NN
[root@node002 ~]# hdfs zkfc -formatZK
# (5)启动所有服务
[root@node001 ~]# hadoop-daemon.sh start namenode
[root@node001 ~]# start-dfs.sh
切换状态实现方式!
[root@node002 ~]# jps
4537 NameNode
4960 DataNode
5132 DFSZKFailoverController
4163 QuorumPeerMain
4340 JournalNode
5233 Jps
# (1)杀死进程,NameNode 或 DFSZKFailoverController
[root@node002 ~]# kill -9 4537
# (2)后台启动服务
[root@node002 ~]# hadoop-daemon.sh start namenode
[root@node002 ~]# hadoop-daemon.sh start zkfc
# (3)查看状态切换
node001:50070
node002:50070
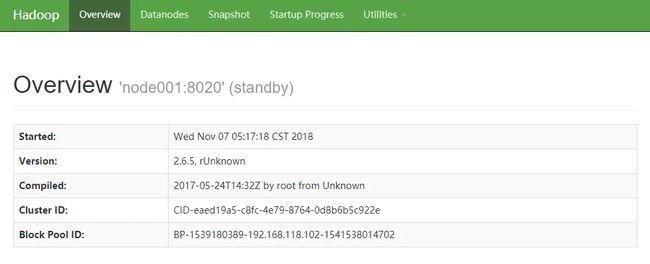
standby
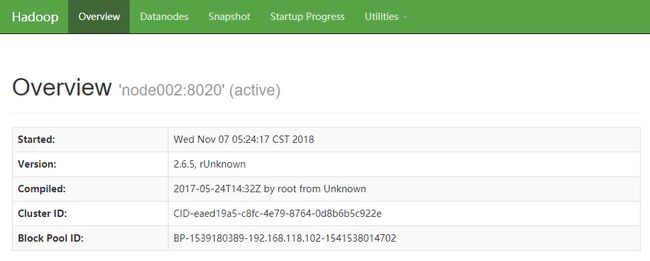
active

作者:geekAppke
链接:https://www.jianshu.com/p/d79dc75b2928
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。