Spark权威指南(中文版)----第14章 分布式共享变量
Spark The Definitive Guide(Spark权威指南) 中文版。本书详细介绍了Spark2.x版本的各个模块,目前市面上最好的Spark2.x学习书籍!!!
扫码关注公众号:登峰大数据,阅读中文Spark权威指南(完整版),系统学习Spark大数据框架!
如果您觉得作者翻译的内容有帮助,请分享给更多人。您的分享,是作者翻译的动力

除了弹性分布式数据集(RDD)接口之外,Spark中的第二类底层API是两种类型的“分布式共享变量”:广播变量和累加器。这些变量可以在用户定义的函数中使用(例如,在RDD或DataFrame上的map函数中),这些函数在集群上运行时具有特殊属性。具体来说,accumulators让将所有task中的数据相加到一个共享结果中(例如,实现一个计数器,统计job中计算失败的输入数据),而广播变量让你保存一个较大的值在所有worker节点,并在多个spark action之间重用,而不需要重新发送到集群各个节点。本章讨论了这些变量类型的一些动机以及如何使用它们。
14.1. 广播变量
广播变量是一种可以在集群中有效地共享不可变值的方法,而无需将该变量封装在函数闭包中。在任务内的驱动程序节点中使用变量的通常方法是在函数闭包中引用它(例如,在map操作中),但是这可能是低效的,特别是对于大型变量,例如查找表或机器学习模型。这样做的原因是,当您在闭包中使用一个变量时,它必须在工作节点上多次反序列化(每个任务一个)。此外,如果您在多个Spark操作和作业中使用相同的变量,它将与每个作业一起重新发送给worker,而不是只发送一次。
这就是广播变量发挥作用的地方。广播变量是共享的、不可变的变量,缓存在集群中的每台机器上,而不是与每个任务一起序列化。规范用例是传递一个大的查找表,这个查找表适合Executor上的内存,并在函数中使用它,如图14-1所示。
例如,假设您有一个单词或值列表:

您希望用您所拥有的其他信息来补充您的单词列表,这些信息的大小可能是许多kb、mb,甚至可能是gb。如果我们从SQL的角度来考虑,这在技术上是一个正确的连接:
我们可以广播这个结构,并使用suppBroadcast引用它。这个值是不可变的,当我们触发一个action时,它会被延迟地复制到集群中的所有节点:

我们通过value方法引用这个变量,它返回我们之前得到的确切值。此方法可在序列化函数中访问,而无需序列化数据。这可以为您节省大量的序列化和反序列化成本,因为Spark使用广播在集群中更有效地传输数据:
现在我们可以使用这个值转换RDD。在本例中,我们将根据map中可能有的值创建一个键-值对。如果我们缺少这个值,我们将简单地用0替换它:

这将在Python中返回以下值,在Scala中返回数组类型中的相同值:
这与将其传递到闭包之间的惟一区别是,我们以一种更有效的方式完成了这一操作(当然,这取决于数据量和执行器的数量)。对于小集群上的非常小的数据(低KBs),它可能不是)。虽然这个小字典的开销可能不是太大,但是如果您有一个大得多的值,那么为每个任务序列化数据的开销可能相当大。
需要注意的一点是,我们在RDD上下文中使用了它;我们也可以在UDF或Dataset中使用它,并获得相同的结果。
14.2. 累加器
Accumulators(图14-2)是Spark的第二种类型的共享变量,它可以在各种转换中更新一个值,并以高效和容错的方式将该值传播到驱动程序节点。
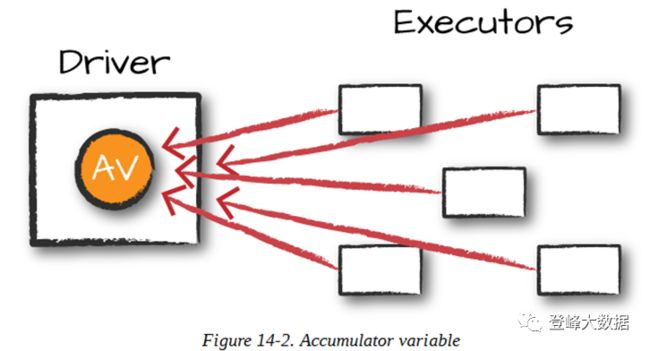
累加器提供了一个可变变量,Spark集群可以安全地按行更新该变量。您可以将其用于调试目的(例如,跟踪每个分区的某个变量的值,以便随着时间的推移使用它),或者创建低级聚合。累加器是仅通过交换律和结合律操作“add”到其中的变量,因此可以有效地并行支持。您可以使用它们来实现计数器(如在MapReduce中)或求和。Spark天生支持数值类型的累加器,程序员可以添加对新类型的累加器。
对于仅在action内部执行的累加器更新,Spark保证每个任务对累加器的更新只应用一次,这意味着重新启动的任务不会更新值。在transformations中,您应该知道,如果重新执行任务或作业阶段,每个任务的更新可以应用不止一次。
Accumulators不会改变Spark的惰性评估模型。如果累加器在RDD上的操作中被更新,那么它的值只在实际计算该RDD时更新一次(例如,当您对该RDD或依赖于它的RDD调用操作时)。因此,不能保证在map()这样的延迟转换中执行累加器更新。
累加器可以命名也可以不命名。命名的累加器将在Spark UI中显示它们的运行结果,而未命名的则不会。
14.2.1. 基本例子
让我们通过对我们在本书前面创建的Flight数据集执行自定义聚合来进行实验。在这个例子中,我们将使用Dataset API而不是RDD API,但是扩展非常类似:
现在让我们创建一个累加器来计算往返中国的航班数量。尽管我们可以在SQL中以一种相当直接的方式来实现这一点,但是很多事情可能没有这么简单。累加器提供了一种编程方式,允许我们执行这些计数。下面演示如何创建一个未命名的累加器:
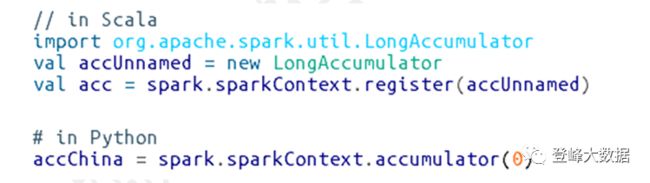
我们的用例更适合命名累加器。有两种方法可以做到这一点:一种是简写方法,另一种是普通方法。最简单的方法是使用SparkContext。或者,我们可以实例化累加器,并注册它的名称:
我们在传递给函数的字符串值中指定累加器的名称,或者作为传递给register函数的第二个参数。命名的累加器将显示在Spark UI中,而未命名的则不会。
下一步是定义添加到累加器的方式。这是一个相当简单的函数:

现在,让我们通过foreach方法遍历flights数据集中的每一行。原因是foreach是一个Action,Spark可以提供仅在动作内部执行的保证。
foreach方法将对输入DataFrame中的每一行运行一次(假设我们没有过滤它),并对每一行运行函数,相应地增加累加器:
这将很快完成,但是如果导航到Spark UI,甚至在以编程方式查询它之前,您就可以在每个执行器级别上看到相关的值,如图14-3所示

当然,我们也可以通过编程来查询它。为此,我们使用value属性:
14.2.2. 自定义累加器
虽然Spark提供了一些默认的累加器类型,但有时您可能希望构建自己的自定义累加器。为了做到这一点,您需要继承AccumulatorV2类。您需要实现几个抽象方法,如下面的示例所示。在本例中,我们将只向累加器添加值。虽然这又是一个简单的例子,但它应该向您展示构建自己的累加器是多么容易:
如果您主要是Python用户,还可以创建自己的自定义累加器,方法是子类化AccumulatorParam并使用它,就像我们在前面的示例中看到的那样。
14.3. 结束语
在本章中,我们讨论了分布式变量。这些工具对于优化或调试非常有用。在第15章中,我们将定义Spark如何在集群上运行,以便更好地理解这些操作何时有用。