LTM(Lifelong Topic Modeling)介绍
LTM(Lifelong Topic Modeling)介绍
论文题目是《Topic Modeling using Topics from Many Domains, Lifelong Learning and Big Data》(Chen and Liu, 2014)
摘要:Topic modeling has been commonly used to discover topics from document collections. However, unsupervised models can generate many incoherent topics. To address this problem, several knowledge-based topic models have been proposed to incorporate prior domain knowledge from the user. This work advances this research much further and shows that without any user input, we can mine the prior knowledge automatically and dynamically from topics already found from a large number of domains. This paper first proposes a novel method to mine such prior knowledge dynamically in the modeling process, and then a new topic model to use the knowledge to guide the model inference. What is also interesting is that this approach offers a novel lifelong learning algorithm for topic discovery, which exploits the big (past) data and knowledge gained from such data for subsequent modeling. Our experimental results using product reviews from 50 domains demonstrate the effectiveness of the proposed approach.
传统的主题模型不用多讲,大家应该了解,不了解的可以阅读《LDA数学八卦》。但传统的主题模型是一个完全无监督的模型,会产生许多不合逻辑的topic,就这个问题,许多引入来自用户的领域先验知识的主题模型被提出。而本文所提到的加入Lifelong Learning思想的主题模型则不需要任何用户输入,就能从大量领域已挖掘的主题中自动地和动态地挖掘先验知识。
这篇文章首先提出了一个在建模过程中动态地挖掘先验知识的新方法,随后利用一个新的主题模型来指导model inference。
主要思想是:利用大数据和从这些数据中获取的知识来帮助随后的建模。
基于Lifelong思想的问题设定
Question: how to find good past knowledge and use it to help new topic modeling tasks?
Data: product reviews in the sentiment analysis context
数据是产品评论数据。

什么知识
- Should be in the same aspect/topic
=> Must-Links
e.g., {picture, photo}- Should not be in the same aspect/topic
=> Cannot-Links
e.g., {battery, picture}
后面会通过例子说明。
算法流程
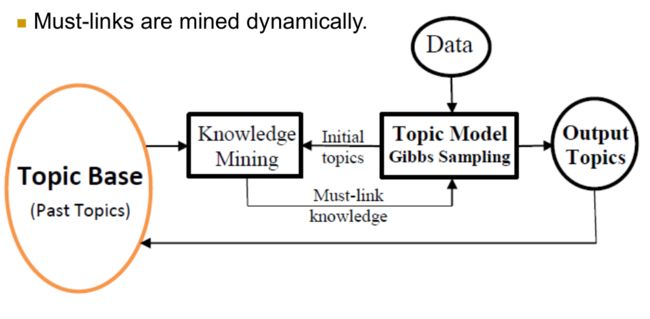
主要分两步:
1. Step 1(先验topic的生成,后称p-topic):
给定来自n个领域的一个文档集合 D={D1,…,Dn} ,使用Algorithm 1 PriorTopicsGeneration对每个领域的文档 Di∈D 运行LDA来生成一系列topic Si (lines 2 and 4)。然后把这些n个领域的topic并起来生成所有topic的集合 S 。我们称这个 S 为prior topic(或p-topic)集合。这些p-topic集合随后会被用在LTM来生成先验知识。(LTM在下一节详解)
接着就进行Iterative Improvement :S中的p-topic可以通过迭代来改善。也就是说,上一轮迭代中的S可以通过下一轮的LTM过程帮助从D中生成更好的topic。lines 1,5-7和10反映了这个过程。LTM从第二轮开始使用。


2. Step 2(testing)
给定一个测试文档集合 Dt 和一个p-topic集合,利用LTM(Algorithm 2)来生成topics。为了区分这些topic和p-topic,我们把它们称为current topics(c-topics)。注意 Dt 可以是来自于 D 或新领域的一个文档集合。这里可以被看做两种方式:(1)来自 Dt 的topics可以是在LTM利用了Knowledge Mining的S中的p-topics集合的一部分 (2)不是S中p-topics的一部分。
Lifelong learning:以上过程可以很自然地应用上lifelong learning思想。 S 是系统生成的一个知识库(knowledge base,如p-topic set),而LTM是学习算法。给定一个新的学习任务 G (如主题建模)和它的数据(如 Dt ),lifelong learning可以分为两个主要阶段:
1. Phase 1:Learning with prior knowledge:这对Step 2至关重要,它需要解决两个子问题(Step 1是初始化):
a) 为任务G识别共享知识(shared knowledge)。在S中识别出可以为G所用的部分知识。在我们的例子中,$K^t$就是shared knowledge(在Algorithm 2中)
b) 基于知识的学习。在$K^t$的帮助下利用一个学习算法来为任务G学习。在我们的例子中,他就是GibbsSampling方法。
2. Phase 2:知识的保留和合并。在我们的例子中,如果G是一个新任务,我们就简单地把G的topic加进S中。如果G是一个旧任务,我们在S中替换它的topics。
LTM模型
像其他许多主题模型一样,LTM也是用Gibbs Sampling来推断,但是LTM有一个很不同的采样器,它可以引入先验知识和处理知识错误。
LTM的工作流程:首先它对数据集 Dt 在没有知识的帮助下跑Gibbs Sampler的N次迭代来生成初始topic集 At (line 1, Algorithm 2)。由于它没有用到先验知识,所以它等效于LDA。然后它执行另外N次Gibbs Sampling(line 2-5)。但是在每次迭代中,他首先对 At 中的所有topics使用KnowledgeMining方法(Algorithm 3)来挖掘pk-sets Kt ,然后利用这些 Kt 来从 Dt 中生成新的topic集。

Knowledge Mining算法
对于每个p-topic sk∈S ,找到在 At 中与它最匹配的c-topic aj∗ 。 Mtj∗ 用来给c-topic aj∗ 挖掘pk-sets(line 7)。我们给每个c-topic aj∗ 找最匹配的p-topics,是因为我们需要 aj∗ 特定的p-topis来更准确的knowledge set mining。下面,我们叙述topic match和knowledge set mining算法。
Topic match(line 2-5, Algorithm 3):为了找到c-topic aj∗ 在 sk 中最匹配的topic,我们使用KL散度来计算两个分布的差异(line 2,3)。在这篇文章中,我们使用对称KL散度来计算所有散度,即 (KL(P,Q)+KL(Q,P))/2 。取KL散度最小且超过阈值 π 的 sk 加入到 Mtj∗ 中。
Mine Knowledge sets using frequent itemset mining(FIM):这个比较简答,就是平时所说的频繁项集。从 Mtj∗ 中找出出现次数查过频数阈值(也称minimum support)的词项集(长度不定)。这些频繁项集就作为后来的must-links知识。
例子:

我们这里选用的词项集长度为2,minimum support为2。
Gibbs Sampler
这个Gibbs Sampler跟LDA的不同,它需要加入利用先验知识的机制,以及在采样过程中处理错误知识的能力。
1. 加入先验知识和处理错误知识
这部分比较复杂,讲述了两种urn model,一种是simple polya model(SPU, LDA遵从),一种是generalized Polya urn model(GPU模型,Mahmoud,2008,本文使用的)。后者可以在Gibbs Sampling中利用像词对这样的先验知识(Mimno, et al.,2008)。
(这里我尝试着描述一下这两种模型,有误请指出)
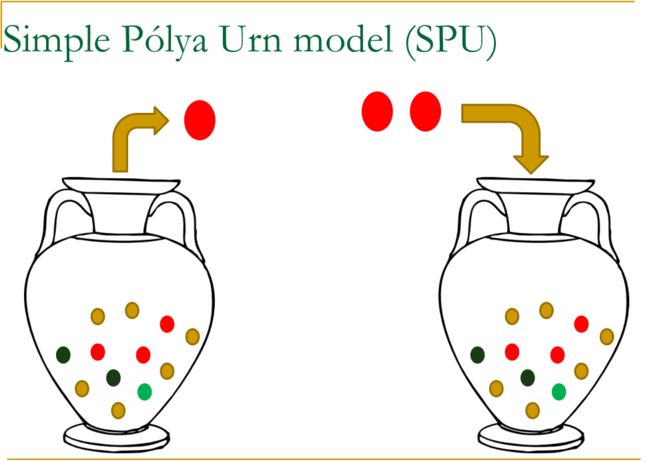
当一个有着特定颜色的球被取出时,这个球需要携带一个相同颜色的球被放回到瓮中。瓮中的内容随时间变化,它有一个自我增强的属性,即”the rich get richer”。

而GPU则不同,但一个特定颜色的球被取出时,两个这种颜色的球被放回,且携带一定数量的其他颜色的球,来增加其他颜色在瓮中的比例。
在我们的例子中应用这种思想:当词 w 被分配了主题t,与 w 共享主题t的pk-set的 w′ 也被分配特定次数主题t,这个次数由矩阵 A′t,w′,w 决定。这里的主题t的pk-set是从主题t的p-topics匹配得到的。
下面讨论矩阵 A′t,w′,w 如何设定,它反映词之间在主题t的相关性。这里我们也考虑错误知识的问题。由于pk-set是从多个先前领域的p-topics中自动挖掘出来的,pk-set中词的语义关系在新的领域中未必正确。判定pk-set是否适合是一个挑战。一个方法就是在当前领域计算pk-set中词的相关性。他们越相关,越有可能适合这个领域,应该被提升更多。他们越不相关,越有可能是错误知识,应该被提升更少。
为了衡量当前领域的pk-set中两个词的相关性,我们使用PMI。
其中:
#Dt(w) 为 Dt 中包含词w的文档数, #Dt(w1,w2) 为 Dt 中包含词 w1 和词 w2 的文档数。 #Dt 为 Dt 的文档总数。
PMI值为正说明词之间语义相关,而PMI值为非正说明有微小相关或不相关。我们加入一个参数因子 μ 来控制GPU模型应该多大程度相信PMI值。
2. Gibbs Sampler的条件概率公式
Reference
[1] Zhiyuan Chen and Bing Liu. Topic Modeling using Topics from Many Domains, Lifelong Learning and Big Data. Proceedings of the 31st International Conference on Machine Learning (ICML 2014), June 21-26, Beijing, China.
[2] LDA数学八卦