C++生存期与作用域
作用域和可见性可以说是对一个问题的两种角度的思考。
“域”,就是范围;而“作用”,应理解为“起作用”,也可称为“有效”。所以作用域就是讲一个变量或函数在代码中起作用的范围,或者说,一个变量或函数的“有效范围”。打个比方,就像枪发出的子弹,有一定的射程,出了这个射程,就是出了子弹的“有效”范围,这颗子弹就失去了作用。
代码中的变量或函数,有的可以在整个程序中的所有范围内起作用,这称为“全局”的变量或函数。而有的只能在一定的范围内起作用,称为“局部”变量。
1.局部作用域
“不能在同一作用范围内有同名变量”。因此,下面的代码是错误的:
...
int a; //第一次定义a
int b;
b = 2*a;
int a; //错误:又定义了一次a
...
那么,在什么情况下,变量属于不同的作用范围呢?我们这里说的是第一种:一对{}括起来的代码范围,属于一个局部作用域。如果这个局部作用域包含更小的子作用域,那么子作用域的具有较高的优先级。在一个局部作用域内,变量或函数从其声明或定义的位置开始,一直作用到该作用域结束为止。
例一:变量只在其作用域内有效
void func() { int a; a = 100; cout << a << endl; //输出a的值 } int main(int argc, char* argv[]) { cout << a << endl; // <-- 错误: 变量a未定义 return 0; }
说明:在函数 func()中,我们定义了变量a,但这个变量的“作用域”在 } 之前停止。所以,出了花括号以后,变量a就不存在了。请看图示:
结论:在局部作用域内定义的变量,其有效范围从它定义的行开始,一直到该局部作用域结束。
在局部作用域内定义的变量,称为“局部变量”。
上例中的局部作用域是一个函数。其它什么地方我们还能用到{}呢?很多,所有使用到复合语句的地方,比如:
//if 语句
if( i> j)
{
int a;
... ...
}
上面的a是一个局部变量,处在的if语句所带的那对 {} 之内。
//for 语句:
for(int i=0;i<100;i++)
{
int a;
... ...
}
上面的a也是一个局部变量。处在for语句带的{}之内。
for 语句涉及局部作用域时,有一点需要特别注意:上面代码中,变量 i 的作用域是什么?
根据最新的 ANSI C++ 规定,在for的初始语句中声明的变量,其作用范围是从它定义的位置开始,一直到for所带语句的作用域结束。而原来老的标准是出了for语句仍然有效,直到for语句外层的局部作用域结束。请看对比:
假设有一for语句,它的外层是一个函数。新老标准规定的不同作用域对比如下:

如果按照旧标准,下面的代码将有错,但对新标准,则是正确的,这也证明了i的作用域只有for有效:
void func() { for(int i=0;i<9;i++) { cout << i << endl; } for(int i=9;i>0;i--) //<-- 在这一行,旧标准的编译器将报错,为什么? { cout << i << endl; } }
Borland C++ Builder 对新旧标准都可支持,只需通过工程中的编译设置来设置采用何种标准。默认总是采用新标准。记住:如果你在代码中偶尔有需要旧标准要求的效果,你只需把代码码写成这样:
int i;
for(i=0;i<9;i++)
{
...
}
这时候,i的作用域就将从其定义行开始,一直越过整个for语句。
其它还有不少能用到复合语句(一对{}所括起的语句组)的流程控制语句,如do..while等。请复习以前相关课程。
其实,就算没有流程控制语句,我们也可以根据需要,在代码中直接加上一对{},人为地制造一个“局部作用域”。比如在某个函数中:
void func() { int a = 100; cout << a << endl; { int a = 200; cout << a << endl; } cout << a << endl; }
执行该函数,将有如下输出:100 200 100
你能理解吗?
2.全局作用域 和 域操作符
如果一个变量声明或定义不在任何局部作用域之内,该变量称为全局变量。同样,一个函数声明不处于任何局部作用域内,则该函数是全局函数。
一个全局变量从它声明或定义的行起,将一起直接作用到源文件的结束。
请看下例:
//设有文件 Unit1.cpp,内定义一个全局变量:
int a = 100; void func() { cout << a << endl; }
输出:100
我们今天还要学习到一个新的操作符,域操作符 “::”。域操作符也称“名字空间操作符”,由于我们还没学到“名字空间”,所以这里重点在于它在全局作用域上的使用方法。
:: 域操作符,它要求编译器将其所修饰的变量或函数看成全局的。反过来说,当编译器遇到一个使用::修饰的变量或函数时,编译器仅从全局的范围内查找该变量的定义。
下面讲到作用域的嵌套时,你可以进一步理解全局作用域如何起作用,同时,下例也是我们实例演示如何使用域作用符::的好地方。
3. 生存期
一个变量为什么有会不同的作用域?其中一种最常见的原因就是它有一定的生存期。什么叫生存期?就像人一样,在活着的时候,可以“起作用”,死了以后,就不存在了,一了百了。
那么,在什么情况下一个变量是“活”着,又在什么情况下它是“死”了,或“不存在”了呢?
大家知道,变量是要占用内存的。比哪一个int类型的变量占用4个字节的内存,或一个char类型的变量占用1个字节的内存。如果这个变量还占用着内存,那么我们就认为它是“活着”,即,它存在着。而一个变量释放了它所占用的内存,我们就认为它“死了”,“不存在”了。
4. 程序的内存分区
先从程序上看“生”和“死”。
用CB编译出一个可执行文件(.exe),它被存放在磁盘上。当它没有运行时,我们认为它是“死”的。而当我们双击它,让它“跑”起来时,我们认为它是“活”的,有了“生命”。等我们关闭它,或它自行运行结束,它又回到了“死”的状态下。在这个过程里。
程序运行时,它会从操作系统那里分得一块内存。然后程序就会把这些内存(严格讲是内存的地址)进行划分,哪里到哪里用来作什么。这有点像我们从老板那里领来2000大洋,其中1000无要交月租,500元做生活费……真惨。
那么,程序有哪些需要入占用内存呢?
首先,代码需要一个空间来存放。因此,到手的内存首先要分出一块放代码的地方,称为代码区。剩下的是数据。根据不同需要,存放数据有区域有三种:数据区,栈区,堆区。为什么存放数据的内存需要分成三个区域?这个我先不说,先来说说数据(变量等)被放入不同的区内,将遇上什么样不同的命运。
第一、放入数据区的数据。
生存期:这些数据的命运最好。它们拥有和程序一样长的生存期。程序运行时,它们就被分配了内存,然后就死死占着,直到程序结束。
谁负责生死:这些数据如何产生,如何释放,都是程序自动完成的,我们程序员不用去费心为产生或释放这些变量写代码。
占用内存的大小:这些数据都必须有已知,且固定的大小,比如一个int变量,大小是4个字节,一个char类型,大小是1个字节。为什么必须这样?因为如果这个数据可以占用的大小是未定的,那么,程序就不可能为自动分配内存。
初始化:就是这个变量最开始的值是什么?放在数据区里的数据,可以是程序员用代码初始化,比如:
int a = 100;
这样,a的值按你意思去办,并初始化为100;但如果你没有写初始的代码,如:
int a;
那么,数据区内的数据将被初始化为全是0。
第二、放入堆区的数据。
生存期:堆内的数据什么时候“生(分配内存)”,什么时候“死(释放内存)”,由程序员决定。
谁负责生死:当然就是程序员了。C++里,有专门的函数或操作符来为堆里的变量分配或释放内存。程序员通过写这些代码来在需要时,让某个堆里的变量“生”,不需要时,让它“死”。
占用内存的大小:堆里的数据占用的内存可以是固定的,也可以是可变的。这就是C,C++里最强大也最难学的内容:“指针”所要做事。
初始化:由程序员完成。如果程序员不给它初始值,则它的值是未定的。
由于程序员掌握着堆区内的数据的“生死大权”,并且决定着该数据占用多少内存。所以在写程序时,必须特别注意这些数据。一不小心就会出错。比如一个数据还没有分配内存呢,你就要使用它,就会出错。更常见的是,一个数据,你为它分配了内存,可是却始终没有为替它释放内存,那样就会造成“内存泄漏”。就算你的程序都退出了,这个数据依然可能“阴魂不散”地占用着内存。
第三、放入栈区的数据。
生存期:对比前面的两种,数据区里数据具有永久的生存期,而堆里的数据的生存期算是“临时”的。需要了,程序员写代码产生;不需要了,又由程序员写代码释放。在程序员,临时才需要变量非常多,如果每个变量都由程序员来负责产生、释放,那程序员岂不很累?并且很危险(万一忘了释放哪个大块头的家伙....)。所以,必须有一种机制可以让程序自已来产生和释放某些临时变量。所以,放入堆区的数据是只有程序员才能决定的何时需要,何时不需的临时数据,而栈区数据则是编译器就能决定是否需要的临时数据。 当然,要想让编译器能知道数据什么时候需要,什么时候不需要,就必须做一种约定。这正是我们现在讲的“生存期”的语法内容。
谁负责生死:程序(和数据区的一样)。
占用内存的大小:固定大小(和数据区的一样)。
初始化:由程序员完成。如果程序员不给它初始值,则它的值是未定的(和堆区的一样)。
下面是三个区加上代码区的分布示意图:
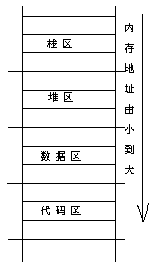
现在,我们也比较好回答前面的问题:“为什么存放数据的内存需要分成三个区域”?原因正在于程序所要用到的数据具有不同的生存期要求,所以编译器把它们分别放到不同空间,好方便实现要求。
生存期和作用域的关系是:如果一个变量已经没有了生存期,那么自然它也就没了有作用域。但反过来,如果一个变量出了它的作用域,它并不一定就失去了生存期。典型的如函数内的静态数据,下面会讲到。
5. 动态生存期
就是放在“堆区”的数据。这些数据是在程序运行到某一处时,由程序员写的代码动态产生;后面又由程序员写的代码进行释放。
6. 局部生存期
这里的局部和前面讲“局部作用域”一致,都是指“一对{}括起来的代码范围”。
请看下面代码,并思考问题:
//从前,有一个函数…… void func() { //函数内,有一个局部变量…… int a; cout << a << endl; a = 100;
//看清楚了,上面输出 a 的值的语句, 位于给a赋值之前!
//然后,下面的代码是两次调用这个函数:
...
func();
func();
...
第一次调用,我们知道屏幕肯定是要输出一个莫名其妙的数,因未初始化的局部变量,其值是不定的。我们以前讲变量时,就做过实例。现在,这里的变量a被输出后,我们让赋于它100。再接下来,我们又调用了一次函数func();请问这回输出的值,是100呢?或者仍然是莫名其妙的数?
7.静态生存期
就是放在“数据区”里的数据。程序一运行时,它们就开始存在;程序结束后,它们自动消亡。
这里讲的“静态”,和前面的“静态存储类型”不是一个意思。(老师,我忘了什么叫“静态存储类型”?呵,这有可能,本章的内容互相都有些关联和相似,大家多看几遍本章,最主要是课程让你动手的地儿,你就动手做,正所谓“该出手时就出手手……”)。
“静态存储类型”是指:一个全局变量,它被加上static之后,就只能在本文件内使用,别的文件不能通过加extern的声明来使用它。
“静态生存期“是指:一个变量,它仅仅产生和消亡一次(即在程序运行时产生,在程序退时消亡),而不像“动态生存期”或“局部生存期”那样可以生生死死,不断“投胎转世”。
下面的代码演示了“静态生存期”和“局部生存期”变量的不同。请你看完以后,回答问题。
#include
//定义,声明一个全局变量:
int a;
//声明一个函数,定义在后面
void func(); int main(int argc, char* argv[ { int b = 100; a = 10; cout << a << end; cout << b << end; //调用函数func: func(); } //func()的定义: void func() { cout << a << endl; cout << b << endl; }
哪里有错呢?请大家想想,试试。
8.局部静态变量
//从前,有一个函数…… void func() { //函数内,有一个局部变量…… int a; cout << a << endl; a = 100; } //调用两次: func(); func();
同样是这个例子,我们只是要把 int a 之前加上一个 static 关键字:
void func() { //函数内,有一个局部静态变量…… static int a; cout << a << endl; a = 100; } ... func(); func(); ...
我们要问的也是同样一个问题:第二次调用 func()后,输出的 a 值是多少?
这回答案是:输出的值是100。
这就是局部静态变量的特殊之处:尽管出了函数的作用域之后,变量已经不可见,并且也失去了作用。但是,它仍然存在着!并且保留着它最后的值。因此,它也是静态生存期。它也只在程序结束之后,才失去生存期。
上面讲的是局部静态变量“死”的问题,它也只“死”一次,对应地,显然它也只能“生”一次。