JVM篇(五)解析JVM内存分配
说到jvm内存分配,大家应该想到哦new出来的对象放入堆中,变量什么的放入栈中,其实jvm内存分配也是有规则的,为了让性能更好,那么接下来就来探索一下JVM的内存分配
1.探索堆内存如何分配
对象分配的规则有哪些?
- 对象主要分配在新生代的Eden区上。
- 如果启动了本地线程分配缓冲,将按线程优先在TLAB上分配
- 少数情况下也可能会直接分配在老年代中(这个少数情况可能分配的内存太大,不能复制到Surviver中那就直接会分配到老年代中)

1.1 什么是TLAB
TLAB(Thread Local Allocation Buffer线程TLAB局部缓存区域)
堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的,
Sun Hotspot JVM为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间TLAB(Thread Local Allocation Buffer), 其大小由JVM根据运行的情况计算而得,在TLAB上分配对象时不需要加锁,因此JVM在给线程的对象分配内存时会尽量的在TLAB上分配, 在这种情况下JVM中分配对象内存的性能和C基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配,TLAB仅作用于新生代的Eden Space,因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效。
所有新创建的Object 都将会存储在新生代Yong Generation中。 如果Young Generation的数据在一次或多次GC后存活下来,那么将被转移到OldGeneration。
新生代与老年代
- 新生代GC(Minor GC):指发生在新生代的垃圾收集动作,因为java对象大多都具备朝生夕灭的特性,所以Minor GC非常频繁,一般回收速度快。
- 老年代GC(Major GC/Full GC):指发生在老年代的GC,出现 Major GC,经常会伴随至少一次的Minor GC(但非绝对的,在Parallel Scavenge收集器的收集策略里就有直接进行Major GC的策略选择过程) Major GC的速度一般会比Minor GC慢10倍以上。
1.2 堆内存分配代码示例
1.首先写上以下代码,给实例byte数组分配40m的内存
public class qiehuanGC {
private static int byteSize=1024*1024;
public static void main(String[] args) {
byte[] bytes=new byte[40*byteSize];
}
}2.配置启动vm的参数,idea下编辑启动配置

3.填上打印GC详细信息的参数:-verbose:gc -XX:+PrintGCDetails,点击ok

4.运行main方法,出现以下日志信息,首先看图就会发现对象首先分配在eden区中,PSYoungGen是年轻代,PS是Parallel Scavenge的垃圾收集器,是一个注意吞度量并行多线程的收集器,ParOldGen是老年代Parallel Scavenge收集器

我们也可以指定垃圾收集器的类型
5.还是配置启动参数,-verbose:gc -XX:+PrintGCDetails -XX:+UseSerialGC,加上使用串行收集器Serial,最原始的收集器

6.然后运行查看结果,def就是使用了Serial垃圾收集器的意思。

1.3大对象的分配
是什么?
所谓的大对象是指,需要大量连续内存空间的java对象,最典型的大对象就是那种很长的字符串以及数组。
虚拟机提供了一个-XX:PretenureSizeThreshold(是以kb为单位),令大于这个设置值的对象直接在老年代分配,这样做的目的是避免在Eden区及两个Survivor区之间发生大量的内存复制
-verbose:gc -XX:+PrintGCDetails 开启GC日志打印
-Xms20M 设置jvm初始内存为20m
-Xmx20m 设置jvm最大内存为20m
-Xmn10m 设置年轻代内存大小为10m
示例:
1.分配14m数组空间
public static void main(String[] args) {
byte[] bytes = new byte[1024 * 1024 * 1];
}2.进行启动参数配置,-verbose:gc -XX:+PrintGCDetails -XX:+UseSerialGC -XX:PretenureSizeThreshold=3145728 设置超过3M就要存储老年代

3.从这里看已经存进了老年代

4.把数组使用内存变为1m,再查看一下,发现老年代使用了0k,说明没有存储到这里

1.4 逃逸分析和栈上分配
逃逸分析:简单来讲就是,java hotspot虚拟机可以分析创建对象的使用范围,并决定是否在java堆上分配内存的一项技术。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,称为方法逃逸。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
栈上分配:栈上分配就是把方法中的变量和对象分配到栈上,方法执行完成后自动销毁,而不需要垃圾回收的介入。
栈上分配有什么好处:
不需要GC介入去回收这个对象,出栈即释放资源,可以提高性能,由于GC每次回收对象的时候都是需要停止用户操作进行回收的,如果对象频繁的创建在我们的堆中,也就意味着要频繁的暂停所有线程,这对于用户无非是非常影响体验的,栈上分配就是为了减少垃圾回收的次数。
方法逃逸示例:
public class testEscape {
public static Object obl;
// 方法内object对象赋给了obj全局变量引用
public void variableEscape() {
obl = new Object(); // 发生逃逸
}
// 返回的值被main方法的obj所引用
public Object metnodEscape() {
return new Object(); // 发生逃逸
}
public static void alloc() {
byte[] b = new byte[2];
b[0] = 1;
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
alloc();
}
long end = System.currentTimeMillis();
System.out.println(end - start + "ms");
}
}
进行逃逸分析之后,产生的后果是对象将由栈上分配,而非从JVM内存模型中的堆来分配。
逃逸分析的jvm参数如下:
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
现在示例一下加逃逸分析和不加逃逸分析的区别
Jdk1.8默认就是加逃逸分析的,那么这个也是可配置的。那么先写一个调用100000万次方法加逃逸分析的结果示例。
Idea点击编辑配置启动参数

配置-verbose:gc -XX:+PrintGCDetails -XX:+DoEscapeAnalysis
![]()
发现结果就是5ms
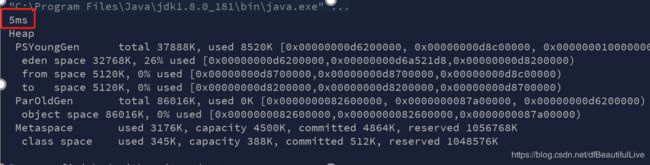
咱们在来关闭逃逸分析,将-XX:+DoEscapeAnalysis改成 -XX:-DoEscapeAnalysis来关闭逃逸分析
不仅频繁的进行GC,而且时间也运行的很长

以上就是java堆分配对象的内容!