最低成本路径分析(Python)

多维数组和矩阵是编程技术面试中的热门面试主题。 尽管此类问题的实际应用有时可能会花很多时间,但此类问题确实测试了受访者使用不同数据类型的能力以及将代码整合为简洁块的能力。 我最喜欢这个小组中的一个问题,它涉及最低成本的途径。

以上面的示例为例,地图和道路均为网格格式。 如果您试图从A点到达B点,那么您可能会想到距离或时间上的每条街道。 因此,根据您从A点到B点的路线,您旅行的时间和行进的距离可能会有所不同。使事情变得复杂的是,如果每条道路都是一条单向的街道,那么如果您发现所选路线上有很多人流,那么您将无法向后行驶。 在此示例中,确定最小成本路径将需要检查每条航路的距离或时间值,并计算将获得最小总和值的路线。
这与这些技术访谈中经常问到的最低成本路径问题背后的想法非常相似。 将上面的示例转换为看起来更熟悉的示例,请考虑以下示例:

您通常会看到类似地图的内容,而不是地图。 现在是数字网格的时代。 作为开发人员,我们的工作是找到从左上方到右下方的路径,这将为我们提供最小的成本路径或最小路径总和。 通常,我们只能选择相邻的数字,并且只能沿向下或向右移动网格。 这可能是这样的:

如果在此示例中,我们选择了一条使我们直走然后再向下走的路径,则我们将在该路径上相加每个值,从而使总路径成本为2707。但是,最小成本路径可能会小得多。 让我们看另一个简化的示例:

在此视觉效果中,我减小了每个数字的值,并为每个网格值指定了参考点。 例如,第一个网格项可以由坐标(a,v)引用。 这将帮助我们确定所引用的值。 当我们从伪代码转换为实代码时,我们可能会使用数组,并且可以通过索引来引用值。
在此示例中,很明显,由于总路径有限,我们可能只需几分钟即可计算出最小路径。 但是,想象一下20 x 20甚至100 x 100的网格。即使使用程序,可能的路径数量也会很快变得太大而无法计算。 即使我们可以使用蛮力来确定每个路径的值并进行比较来确定最小路径,此类操作通常也会占用大量内存,并且效率远远低于其他方法。 让我们使用这个简单的示例查看更有效的方法来确定最小成本路径。
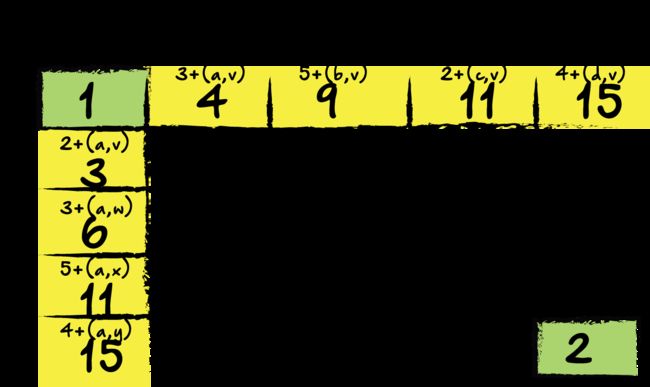
首先,我们将查看网格中的第一行和第一列。 请记住,我们只能向右或向下移动到最终值。 在这里,我已经更新了第一行和第一列中的新值,并给出了给出该值的方程式。 在第一行中,我们通过将当前网格值的值与前一个网格块的值相加来获得新值。 在第一列中,我们通过将当前值添加到该块上方的块的值来获得该块的新值。

现在,我们对块(b,w)做一些不同的操作。 因为它的上方和左侧都有一个块,所以我们可以添加其中一个块。 由于我们需要最终的最小成本路径,因此选择较小值的块是有意义的。 在这种情况下,它是块(a,w),值为3。更新后的值为7(3 + 4)。 现在,让我们在当前行中做同样的事情:

在这里,我们更新了行中的每个值,选择了每个选项的最低值。如果当前块上的值更低,我们将得到两个块的和。但是,如果左边的块是一个较小的值,我们将使用该sum来代替更新后的值。让我们用更新后的值填充网格的其余部分。
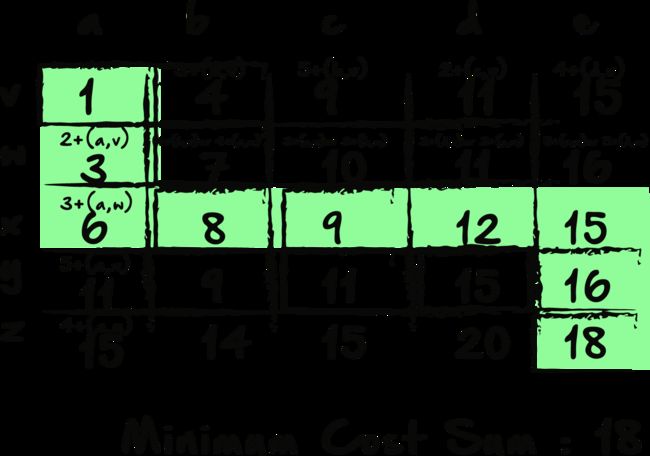
通过在每个块上加上所有最小总和,我们的结尾块的值为18。如果我们向后追溯路径,则可以确认18确实是我们的最小成本总和。 现在,在这个小例子上,这似乎有些琐碎,但请再次想象一下这种方法有多容易,特别是如果我们的数字更大或网格具有更多的值时。 更不用说,此方法比计算和比较每个可能的路径要有效得多。
现在,让我们看一下如何将其转换为实际代码。 我的目标不是编写可解决此问题的硬编码脚本,而是编写可解决任何大小的网格的函数。 为了测试我的程序,我将从之前的网格开始,但是在这里,我将其转换为单个数组:
arr = [131, 673, 234, 103, 18, 201, 96, 342, 965, 150, 630, 803,
746, 422, 111, 537, 699, 497, 121, 956, 805, 732, 524, 37, 331]接下来,我将定义一些变量。 这些变量对于以后能够在不同大小的网格上重用此精确代码非常重要。
rows = 5
columns = 5
length = len(arr)
l = range(length)
firstColumn = l[5::rows]
firstRow = range(1, columns)rows变量定义此网格具有的行数。 我的数组中有25个数字,但是我可以按行和列将其分解。 这将帮助我保持井井有条。 columns变量执行相同的操作。 现在,如果我有一个不同的数组(例如100或1000个数字),则可以更改行和列变量,以根据数组长度反映新网格将具有的新行和列数量。
我的长度变量将帮助我设置以下变量。 由于第一行和第一列的数学与所有其他网格块不同,因此我将无法分别选择它们,而知道数组的长度将有助于我做到这一点。
我定义了firstColumn变量。 由于变量“ l”现在是一个列表,其中包含代表数组长度的数字范围,因此我使用该范围来确定此变量。 在此示例中,由于我有5行,所以我想要的索引值为5、10、15和20。这将构成我的第一列。 l[5::rows]基本上从列表开始,从5开始,跳过数字并获取每第5个后续值,从而为我提供了所需的索引。 如果以后使用更大的网格,则可能会以不同的值启动它,具体取决于行和列的大小。
我的第一行变量是一个范围。 我可以简单地说“ 1, 2, 3 & 4 ”,因为这些是我需要的索引。 但是再次,我希望这段代码在将来尽可能地可重用。 因为我不想要第一个值index 0 ,所以我从'1'开始,无论网格大小如何,它都将相同,并且我将以变量列结尾,该列将保持不变。 如果我有一个较大的网格,则在更新变量column和row之后,此代码行将自动反映该更改,而无需在其他位置进行更新。
放置好变量后,我现在将使用for循环遍历数组/列表:
for idx, val in enumerate(arr):通常,python中的for循环语法看起来像for i in x: ,但是Python有一个称为enumerate的内置方法。 这真的很方便,因为没有它,如果我抓住变量i ,它将给我当前值,而不是该值的索引。 这可能会使某些人感到困惑,例如在JavaScript中,调用i给您索引而不是值。 但是,使用此语法,我可以执行以下操作:
print (idx, arr)
Python将返回一个包含索引和该索引值的数组。 索引在这里将非常重要,因为我主要通过索引来控制列表中发生的事情。 让我们从第一个索引0开始:
if idx == 0: # Targets first list value
val == val # Leaves first value the same第一个值没有改变,我们只是将其设置为适当的值。
接下来,我们将选择和修改列表/数组的第一行和第一列中的值,就像在前面的可视示例中所做的一样。
if idx in firstRow: # Targets values in first row after first value
arr[idx] = arr[idx] + arr[idx-1] # Adds all values in first row to the previous list value
if idx in firstColumn: # Targets all values in first column
arr[idx] = arr[idx] + arr[idx-rows] # adds value to the value above in previous rowidx in firstRow的idx in firstRow基本上会检查当前索引是否在变量firstRow中。 请记住,firstRow不是包含一个数字,而是一系列数字,这些数字代表数组中除第一个索引之外的所有第一个索引值。 如果我们要遍历的当前索引包含在该列表/数组中,则只需将其添加到先前的索引值即可。 idx in方法可以与JavaScript include方法媲美。
我们对列执行相同的操作,我们使用in firstColumn中的索引检查索引是否也在该列表中。 如果是这样,我们可以使用变量rows来回首,而不是将其添加到先前的索引值。 这样做将返回到上一行,然后获取这两个值的总和。 我可以在此处执行[idx-5],但是[idx-rows]再次允许我的代码在将来更可重用,因为如果我的网格较大,我需要更改的唯一变量将是行和列变量。
现在,我们已经处理了网格中的第一行和第一列,剩下的就是剩下的数字。 我不需要指定行或列。 我可以简单地说:“如果当前索引不在其他任何一个列表中,请执行其他操作”。
if idx not in firstColumn and idx not in firstRow: # targes any other values not in first row or first column
if arr[idx] + arr[idx-1] < arr[idx] + arr[idx-rows]: # determine if value above or previous is smaller
arr[idx] = arr[idx] + arr[idx-1] # sets value
else:
arr[idx] = arr[idx] + arr[idx-rows] # sets value在上一个示例中,我们取上一个索引的值,或者取上一行的索引值,这取决于我们是在网格的第一行还是第一列中。 在这些索引值中,我们可以选择其中一个。 因此,我们使用if语句确定当前值左侧的值或当前值上方的索引值是否较小。 我们得到两者中较小的一个,然后将当前数组值设置为新值。
如果我们打印数组/列表,那么我们想要的值将是数组末尾的第二个值。 我们在这里可以看到,此示例的最小成本路径为2427,比我们开始时使用的总路径2707小很多。
整个代码块如下所示:
arr = [131, 673, 234, 103, 18, 201, 96, 342, 965, 150, 630, 803,
746, 422, 111, 537, 699, 497, 121, 956, 805, 732, 524, 37, 331]rows = 5
columns = 5
length = len(arr)
l = range(length)
firstColumn = l[5::rows]
firstRow = range(1, columns)
for idx, val in enumerate(arr):
if idx == 0: # Targets first list value
val == val # Leaves first value the same
if idx in firstRow: # Targets values in first row after first value
arr[idx] = arr[idx] + arr[idx-1] # Adds all values in first row to the previous list value
if idx in firstColumn: # Targets all values in first column
arr[idx] = arr[idx] + arr[idx-rows] # adds value to the value above in previous row
if idx not in firstColumn and idx not in firstRow: # targes any other values not in first row or first column
if arr[idx] + arr[idx-1] < arr[idx] + arr[idx-rows]: # determine if value above or previous is smaller
arr[idx] = arr[idx] + arr[idx-1] # sets value
else:
arr[idx] = arr[idx] + arr[idx-rows] # sets value
print arr # returns list再说一次,回到技术面试中,学习和熟悉这些网格以及多维数组问题是一件很重要的事情,那就是他们建立了巩固代码的技能,以便可以更高效地运行代码。 让我知道您是否有任何反馈意见。 谢谢!
原文链接: https://hackernoon.com/minimum-cost-path-analysis-python-47ad79a54519