AAAI论文Joint Extraction of Entities and Overlapping Relations Using Position-Attentive Sequence阅读笔记
文章目录
- 摘要
- 相关工作
- 主要方法及创新点
- 1.使用标记序列提取重叠关系
- 重叠关系的定义
- 标记方案
- 2.在关系提取中使用位置注意力机制
- 实验
- 全文翻译
本文在AAAI19发布,论文地址:https://wvvw.aaai.org/ojs/index.php/AAAI/article/view/4591

摘要
联合实体和关系提取是使用单个模型同时检测出实体和关系。目前主流的联合实体和关系抽取方法,主要是采用管道模型,先识别出实体,再找出实体间的关系。这样的框架虽然容易推导,但易导致错误传播,并且忽略了实体和关系间的内在联系。本文提出了一种新颖的统一联合提取模型,该模型根据查询词位置p标记实体和关系标签,即设定一个位置p,然后在p处检测实体,并在与前者(p处实体)有关系的其他位置识别实体。为了实现这种模式,文中还提出了一种标记方案,为n个单词的句子生成n个标记序列。然后引入位置注意机制为每个查询位置生成不同的句子表示,以对这n个标签序列进行建模。文中提出的模型可以同时提取实体及其类型以及所有重叠关系。实验结果表明,在提取重叠关系以及检测远程关系方面,文中提出的框架性能非常好。
相关工作
文中提出了新的统一框架进行联合抽取。给定一个句子和一个查询位置p,我们的模型将回答两个伪问题:“p处的实体及其类型是什么?”和“ p处的实体与哪个实体有关系?”通过回答这两个问题我们将联合抽取问题转化为序列标注问题,对于一个有n个单词的句子,我们根据n个查询位置(每个单词是一个查询位)注释了n个不同的标签序列。为了在单个统一模型中对这n个标记序列建模,我们将一种新颖的位置注意力机制引入序列标记模型以生成n个不同的位置感知语句表示。另外,所提出的注意力机制可以在单词(实体)之间建立直接连接,这有助于提取远程关系(两个实体之间的距离很长)。
本文的主要工作为:
- 设计了一种可以同时表示实体类型和重叠关系的标记方案。
- 提出了一种位置注意机制,根据查询位置p生成不同的位置感知语句表示,可用于解码不同的标签序列并提取重叠关系。
- 采用实验证明了提出的方法的有效性。
主要方法及创新点
本篇论文主要有两个创新点,一个是提出了一套新颖的标记方案,标记n个(n为句子长度)和句子长度相同的标签序列,使得模型在提取重叠关系方面相比其他模型有很大的改善。另一个是使用了位置注意力机制,位置注意力机制的使用使模型提取远程关系的效果非常出色。
1.使用标记序列提取重叠关系
重叠关系的定义
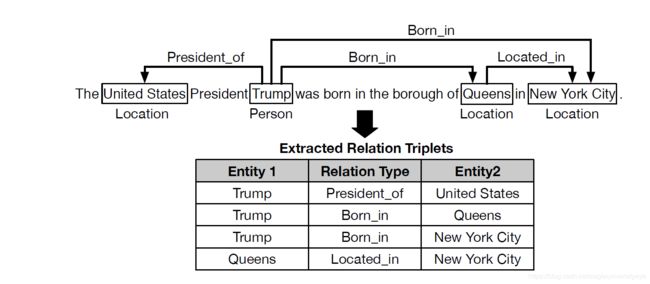 上图是论文中给出的一个重叠关系的例子。该句子中,多个关系共享该句子中同一个实体,这几个关系就是重叠关系。例如,表中的前三个关系因为它们共享相同的实体’‘特朗普’'而重叠。类似地,后两个关系也重叠,共享实体“纽约市”。这种重叠关系在关系提取数据集中非常常见,而传统的模型一般只能抽取出重叠关系中的一个,而不能把所有的重叠关系全部抽取出来。
上图是论文中给出的一个重叠关系的例子。该句子中,多个关系共享该句子中同一个实体,这几个关系就是重叠关系。例如,表中的前三个关系因为它们共享相同的实体’‘特朗普’'而重叠。类似地,后两个关系也重叠,共享实体“纽约市”。这种重叠关系在关系提取数据集中非常常见,而传统的模型一般只能抽取出重叠关系中的一个,而不能把所有的重叠关系全部抽取出来。
标记方案
为了解决重叠关系的提取问题,文中提出了标记序列的方法。标记序列的标记过程如下:
对于一个有n个单词的句子,为每一个单词创建一个长度为n的序列并标记,共标记n个长度为n的序列。根据不同的查询位置p(也就是目标单词在句子中的位置)对n个不同的标记序列进行注释。在每个标签序列中,如果查询位置p是在实体的开始处,则在查询位置p标记该实体的类型,而在p处与该实体有关系的其他实体则用关系类型标记,其余位置则分配“O”标签(外部标签),表明它们与所关注的实体没有关系。因此,可以基于标签序列提取由三元组(Entity1,RelationType,Entity2)表示的关系。显然,查询位置p处的实体可以多次使用组成重叠的关系。

上图是标记方案的一个示例,其中n表示句子长度,p∈[1,n]是查询词的位置。对于查询词p,建立一个长度为n的标签序列来表示与p处的实体相对应的所有可能的重叠关系。如果p在实体的开始处,则在p处标记该实体类型;对于其他的位置,如果它们与p处的实体具有关系,则在其余的单词上标记关系类型。这样,可以使用此标记方案对所有实体和重叠关系进行注释。在此示例中,“ B-LOC”中的“ LOC”是实体类型LOCATION的缩写,“ S-PER”中的“ PER”是PERSON的缩写,“ B-PO”中的“ PO”是关系类型的主席的缩写 ,“ B-BI”中的“ BI”是“出生于”的缩写,而“ B-LI”中的“ LI”是“位于”的缩写。在上图所示例子中,当p=5时,目标单词为Trump,建立一个标签序列,由于p=5的位置有一个实体Trump,所以在p=5的位置标记S-PER,S是signal单字的意思,PER是这个实体的类型。对于实体Trump,它和位置为14,15,16处的New York City构成了一个关系三元组{Trump, Born_in, New York City},关系为Born_in,所以在实体New York City上,分别标记了B-BI、I-BI、E-BI。由这个例子可以看出标记方案,即在关系三元组的第一个实体上标记实体的类型,第二个实体上标记关系类型。
2.在关系提取中使用位置注意力机制
在计算位置注意力向量之前,需要做的准备工作有,将字向量和词向量拼接后[Ww;Wc],作为输入,输入进一个Bi-LSTM编码器,得到隐藏层状态,使用H = {ht},t∈[1,n]表示。之后进行位置注意力的计算。
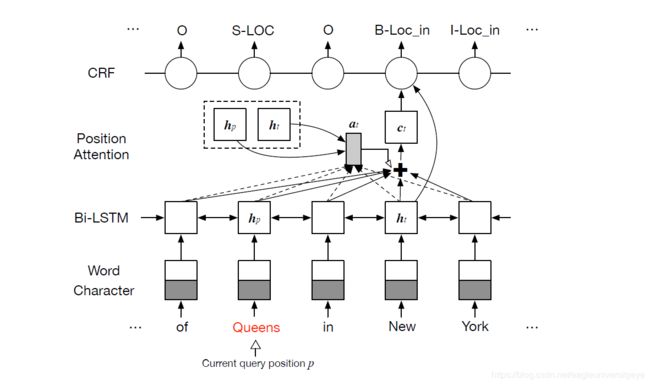
上图展示了论文中提出的位置注意力机制。其主要思想是为句子中的每一个单词求出一个注意力向量ct,ct = att(H, hp, ht),t∈[1,n]。其中H是整个句子的隐藏状态,hp是目标词状态,ht是对应的单词的隐藏状态。得到ct的方法如下:
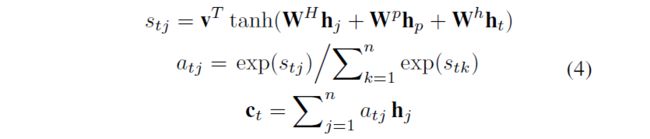 上述公式中WH,Wp,Wh,v是要学习的参数,hj,hp,ht分别是位置j,p和t处的隐藏状态,stj是通过将hp和ht与每个句子状态hj进行比较而得出的分数, atj是stj归一化产生的注意力权重。j用来遍历整个句子中的所有单词,j∈[1,n]。对句子中的一个单词wt,它的注意力权重在计算时会用到整个句子中所有单词的隐藏状态(用hj表示)、位置p处的单词的隐藏状态hp,和wt自己的隐藏状态ht。
上述公式中WH,Wp,Wh,v是要学习的参数,hj,hp,ht分别是位置j,p和t处的隐藏状态,stj是通过将hp和ht与每个句子状态hj进行比较而得出的分数, atj是stj归一化产生的注意力权重。j用来遍历整个句子中的所有单词,j∈[1,n]。对句子中的一个单词wt,它的注意力权重在计算时会用到整个句子中所有单词的隐藏状态(用hj表示)、位置p处的单词的隐藏状态hp,和wt自己的隐藏状态ht。
通过上式中的方法求出了位置注意力向量ct,将其和Bi-LSTM编码器得到隐藏层状态ht拼接,得到向量ut,然后将ut作为输入,输入进一个CRF解码器,计算后得到实体和关系三元组。
实验
实验使用了纽约时报和Wiki-KBP的数据集来评估该方法。NYT和Wiki-KBP的统计数据如下表所示。
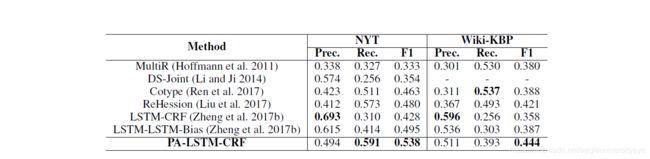 作者还通过和lstm-lstm-bias模型做的对比实验,证明了该模式在抽取长距离的实体关系方面有更杰出的效果。
作者还通过和lstm-lstm-bias模型做的对比实验,证明了该模式在抽取长距离的实体关系方面有更杰出的效果。

全文翻译
使用Google翻译,不是很准确,可以做个参考
摘要
Joint entity and relation extraction is to detect entity and relation using a single model. In this paper, we present a novel unified joint extraction model which directly tags entity and relation labels according to a query word position p, i.e., detecting entity at p, and identifying entities at other positions that have relationship with the former. To this end, we first design a tagging scheme to generate n tag sequences for an n-word sentence. Then a position-attention mechanism is introduced to produce different sentence representations for every query position to model these n tag sequences. In this way, our method can simultaneously extract all entities and their type, as well as all overlapping relations. Experiment results show that our framework performances significantly better on extracting overlapping relations as well as detecting long-range relation, and thus we achieve state-of-the-art performance on two public datasets.
联合实体和关系提取是使用单个模型检测实体和关系。在本文中,我们提出了一种新颖的统一联合提取模型,该模型根据查询词位置p直接标记实体和关系标签,即在p处检测实体,并在与前者有关系的其他位置识别实体。为此,我们首先设计一种标记方案,以为n个单词的句子生成n个标记序列。然后引入位置注意机制为每个查询位置生成不同的句子表示,以对这n个标签序列进行建模。这样,我们的方法可以同时提取所有实体及其类型以及所有重叠关系。实验结果表明,在提取重叠关系以及检测远程关系方面,我们的框架性能显着提高,因此我们在两个公共数据集上实现了最新的性能。
引言
传统的RE系统将此任务分为流水线子任务:首先检测实体,然后对候选实体对之间的关系类型进行分类,这样的框架使任务易于执行 ,但忽略了这两个子任务之间的潜在相互依赖关系和错误传播(Li和Ji,2014; Gupta,Schutze和Andrassy,2016)。
与流水线方法不同,联合提取是使用联合模型来检测实体及其之间的关系。最近的研究表明,联合学习方法可以有效地整合实体和关系的信息,因此在两个子任务中均具有更好的性能。这些模型基于基于特征的结构化学习(Kate and Mooney 2010; Li and Ji 2014; Miwa and Sasaki 2014; Ren et al.2017),这些方法在很大程度上依赖于手工制作的特征和其他NLP工具包。已经应用了架构,其中大多数利用参数共享进行联合建模,但仍然需要用于实体识别和关系分类的显式单独组件(Miwa和Bansal 2016; Gupta,Schutze和Andrassy 2016)。相比之下,Zheng等人(2017b)提出了一种特殊的标记方案,将联合提取转换为序列标记问题,以统一的方式解决任务。 Zeng等人(2018)提出的另一种统一方法是采用具有复制机制的序列到序列学习方法。提取重叠关系时,他们的模型无法识别多词实体。总的来说,使用单个统一模型联合提取实体和重叠关系仍然具有挑战性。
在本文中,我们提出了一种新的统一方法,通过根据查询词位置p同时标记实体和关系标签来解决联合提取问题。给定一个句子和一个查询位置p,我们的模型将回答两个伪问题:是实体及其类型在p?处”和“哪个实体与p处的实体有关系?”为此,我们设计了一种特殊的标记方案,该方案在查询位置p处标注实体标签,并在其他位置标注关系标签。因此,它实际上将联合关系提取问题转换为序列标签问题列表,例如,对于n字句子,我们根据n个查询位置注释n个不同的标签序列。在单个统一模型中对这n个标记序列进行建模,将一种新颖的位置注意机制引入序列标记模型(参见图3),以生成n个不同的位置感知语句表示。 sed解码不同的标记结果,从中我们可以提取所有实体,它们的类型和所有重叠的关系。此外,所提出的注意力机制可以在单词(实体)之间建立直接联系,这可能有助于提取长距离关系(这两个实体之间的距离很长。)
本文的主要贡献是新提出的统一提取实体和重叠关系的统一模型。
1.设计一种可以同时表示实体类型和重叠关系的标记方案;
2.提出一种位置注意机制,根据查询位置p生成不同的位置感知语句表示,可用于解码不同的标记序列。
3.我们使用两个公共数据集演示了该方法的有效性,并获得了最新的结果;此外,分析表明,我们的模型在提取远程关系方面表现更好,通常更多。 很难。

Figure 1: An example sentence that contains overlapping relations which share the same entity in the sentence. For example, the first three relations in the table are overlapping because they share the same entity “Trump”. Similarly, the last two relations are also overlapping due to the shared entity “New York City”. Such overlapping relations are very common in datasets of relation extraction (see Table 1).
图1:包含重叠关系的句子示例,该重叠关系共享该句子中的相同实体。例如,表中的前三个关系因为它们共享相同的实体``特朗普’'而重叠。类似地,后两个关系也重叠。 由于共享实体“纽约市”,这种重叠关系在关系提取数据集中非常常见(请参见表1)。
方法
在本节中,我们首先介绍将重叠关系提取转换为序列标记问题列表的标记方案,然后详细介绍基于该标记方案的位置注意序列标记模型。
Figure 2: An example of our tagging scheme, where n denotes the sentence length, p ∈ [1, n] is the query word position. For a query p, we build an n-tag sequence to represent all possible overlapping relations that correspond to the entity at p. Thus, entity type is labeled at p if it is the start of an entity, and relation types are labeled at the rest of words if they have relationship with the entity at p. In this way, all entities and overlapping relations can be annotated using this tagging scheme. In this example, “LOC” in “B-LOC” is short for entity type LOCATION, “PER” in “S-PER” is short for PERSON, “PO” in “B-PO” is short for relation type President of, “BI” in “B-BI” is short for Born in and “LI” in “B-LI’ is short for Located in.

图2:我们的标记方案的示例,其中n表示句子长度,p∈[1,n]是查询词的位置。对于查询p,我们建立一个n标签序列来表示与p处的实体相对应的所有可能的重叠关系。因此,如果实体类型是实体的开始,则在p处标记该实体类型;如果它们与p处的实体具有关系,则在其余的单词上标记关系类型。这样,可以使用此标记方案对所有实体和重叠关系进行注释。在此示例中,“ B-LOC”中的“ LOC”是实体类型LOCATION的缩写,“ S-PER”中的“ PER”是PERSON的缩写,“ B-PO”中的“ PO”是关系类型的主席的缩写 ,“ B-BI”中的“ BI”是“出生于”的缩写,而“ B-LI”中的“ LI”是“位于”的缩写。
As shown in Figure 2, for an n-word sentence, n different tag sequences are annotated based on our tagging scheme according to different query position p. In each tag sequence, entity type is labeled at the current query position p if this position is the start of an entity, and other entities, which have relationship to the entity at p, are labeled with relation types. The rest of tokens are assigned label “O” (Outside), indicating that they do not correspond to the entity that is attended to. Thus, relations, which are represented by a triplet (Entity1, RelationType, Entity2), can be extracted based on a tag sequence. Here, Entity1 is the first argument of the relation and can be obtained from the detected entity at the query position. Entity2, the second argument, and RelationType can be extracted from other detected entities and their labels in the same tag sequence. Obviously, the first entity can be used multiple times to form overlapping relations.
如图2所示,对于n个单词的句子,根据我们的标记方案,根据不同的查询位置p对n个不同的标记序列进行注释。在每个标签序列中,如果实体类型是在实体的开始处,则在当前查询位置p标记实体类型,而在p与该实体有关系的其他实体则用关系类型标记。其余令牌被分配了标签“ O”(外部),表明它们不对应于所关注的实体。因此,可以基于标签序列提取由三元组(Entity1,RelationType,Entity2)表示的关系。在这里,Entity1是关系的第一个参数,可以从查询位置处的检测到的实体中获取.Entity2,第二个参数和RelationType可以从其他检测到的实体及其相同标签序列中的标签中提取。显然,第一个实体可以多次使用以形成重叠关系。
For example, when the query position p is 5 and the token at this position is “Trump”, the label of “Trump” is PERSON. Other entities, such as “United States”, “Queens” and “New York City”, which are corresponding to “Trump”, are labeled as President of, Born in and Born in. The first entity “Trump” will be used for three times to form three different triplets in this situation. If the query p is 12 and the token is “Queens”, its tag is LOCATION, and the corresponding entity “New York City” is labeled as Located in. For p is 2, there is no corresponding entity and thus only the entity type of “United States” is labeled (notice that the relation is unidirectional). All of the tokens are labeled as “O” when p is 1 because there is no entity at the position p which is attended to. For both entity and relation type annotation, we use “BIES” (Begin, Inside, End, Single) signs to indicate the position information of tokens in the entity, and therefore we can extract multi-word entities. Through our tagging scheme, all of overlapping relations in an n-word sentence, together with all entity mentions and their entity types, can be represented in n tag sequences.
Note that our tagging scheme is quite different from table filling method (Miwa and Sasaki 2014). It uses only half of the table and hence cannot represent reverse relation, which is also a kind of overlapping form, e.g., if the relation of entity pair (Entity1, Entity2) is Capital of, the reverse pair (Entity2, Entity1) may have relation of Contains. In addition, the best search order “close-first” actually equals to first detecting entities and then classifying relations. Most joint neural methods following table filling (Gupta, Schutze, and Andrassy 2016; Zhang, Zhang, and Fu 2017) also use this search order and usually require explicit RC components in the network.
例如,当查询位置p为5且该位置的令牌为“特朗普”时,“特朗普”的标签为PERSON。对应于“特朗普”的其他实体,例如“美国”,“皇后”和“纽约市”,被标记为总裁,出生地和出生地。在这种情况下,第一个实体“ Trump”将被使用三次以形成三个不同的三元组。如果查询p为12,令牌为“ Queens”,则其标签为LOCATION,而对应的实体“ New York City”为标记为位于。对于p为2,没有对应的实体,因此仅标记了“美国”的实体类型(请注意,该关系是单向的)。当p为1时,所有标记都被标记为“ O”,因为在位置p上没有任何实体。对于实体和关系类型注释,我们都使用“ BIES”(开始,内部,结尾,单个)。符号来表示令牌在实体中的位置信息,因此我们可以提取多字实体。通过我们的标记方案,n字句子中的所有重叠关系以及所有实体提及及其实体类型都可以用n个标记序列表示。
请注意,我们的标记方案与表格填充方法完全不同(Miwa和Sasaki 2014)。它仅使用表的一半,因此不能表示反向关系,这也是一种重叠形式,例如,如果实体对(Entity1,Entity2)的关系为Capital of,则反向对(Entity2,Entity1)可能具有包含的关系。此外,最佳搜索顺序“先近”实际上等于先检测实体然后对关系进行分类。表格填充后的大多数联合神经方法(Gupta,Schutze和Andrassy 2016; Zhang,Zhang和Fu 2017)也使用此方法。搜索顺序,通常需要网络中的显式RC组件。
End-to-End Sequence Labeling Model with Position-Attention
With our tagging scheme, we build an end-to-end sequence labeling neural architecture (Figure 3) to jointly extract entities and overlapping relations. Our architecture first encodes the n-word sentence using a RNN encoder. Then, we use a position-attention mechanism to produce different position-aware sentence representations for every query position p. Based on these positionaware representations, we finally use Conditional Random Field (CRF) to decode the n tag sequences to extract entities and overlapping relations. Bi-LSTM Encoder RNNs have been shown powerful to capture the dependencies of input word sequence. In this work, we choose bidirectional Long Short Term Memory (Bi-LSTM) as the encoding RNN. Consider a sentence that consists of n words S = {wt}n , we first convert the words to their word-level representations {wt }tn=1 , where wt ∈ Rd is the d-dimensional word vector corresponding to the t-th word in the sentence. As out of vocabulary (OOV) word is common for entity, we also augment word representation with character-level information. Character-level representations {w }tn=1 are extracted by a convolution neural network (CNN), where w ∈ Rk is the k-dimensional outputs of the CNN with k-filters. This CNN, similar to the one applied on words, receives character embeddings as input and generates representation which effectively captures the morphological information of the word. The final representations of words are concatenation of word-level and character-level representation [wt ; w ]. Then, the Bi-LSTM is implemented to produce forward state h−→t and backward state h←−t for each time step:
具有位置注意的端到端序列标记模型
通过我们的标记方案,我们构建了端到端序列标记神经体系结构(图3),以共同提取实体和重叠关系。我们的架构首先使用RNN编码器对n字句子进行编码。然后,我们使用位置注意机制为每个查询位置p生成不同的位置感知语句表示。基于这些位置感知表示,我们最终使用条件随机场(CRF)对n个标记序列进行解码,以提取实体和重叠关系。Bi-LSTM编码器RNN已显示出强大的功能,可以捕获输入单词序列的依赖性。在本文中,我们选择双向长期短期记忆(Bi-LSTM)作为编码RNN。考虑由n个单词S = {wt} n组成的句子,我们首先将单词转换为它们的单词级表示形式{wt} tn = 1,其中wt∈Rd是与第t个单词相对应的d维单词向量句子中的单词。由于词汇外(OOV)单词对于实体很常见,因此我们还使用字符级信息来增强单词表示。字符级表示{w} tn = 1是由卷积神经网络(CNN)提取的,其中w∈Rk是带有k滤波器的CNN的k维输出。该CNN与应用于单词的CNN相似,接收字符嵌入作为输入,并生成有效捕获单词形态信息的表示形式。单词的最终表示形式是单词级别表示形式和字符级别表示形式的组合[wt; w]。然后,Bi-LSTM被实现为在每个时间步产生正向状态h−→t和反向状态h←−t:
These two separate hidden states capture both past (forward) and future (backward) information of the word sequence. Finally, we concatenate h−→t and h←−t as the encoding output of the t-th word, donated as ht = [h−→t ; h←−t ], to obtain the final sentence representations H = {ht}tn=1. However, such representations are not enough for decoding the n tag sequences produced by our tagging scheme. Because position information is lacking where to detect Entity1 and other components in overlapping triplets.
Position-Attention Mechanism The key information for detecting an entity and its relationship with another entity include: (1) the words inside the entity itself; (2) the depended entity; (3) the context that indicates the relationship. Under these considerations, we propose position-attention, which can encode the entity information at query position as well as the context information of the whole sentence to generate position-aware and context-aware representations {ut}n
这两个单独的隐藏状态捕获单词序列的过去(向前)和将来(向后)信息。最后,我们将h−→t和h←−t连接为第t个单词的编码输出,输出为ht = [h−→t; h←−t],以获得最终的句子表示形式H =(ht } tn = 1。但是,这样的表示不足以对我们的标记方案产生的n个标记序列进行解码。因为缺少位置信息来检测重叠的三胞胎中的Entity1和其他组件。位置注意机制用于检测一个实体及其与另一个实体的关系的关键信息包括:(1)实体本身内部的单词;(2)从属实体;(3)表示关系的上下文。基于这些考虑,我们提出了位置注意,它可以对查询位置处的实体信息以及整个句子的上下文信息进行编码,以生成位置感知和上下文感知的表示形式{ut} n
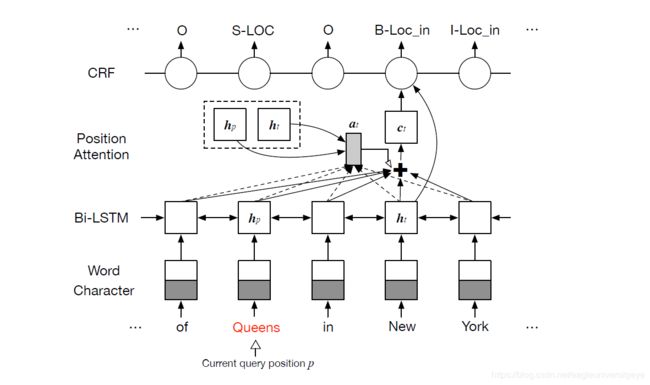
Figure 3: The architecture of our position-attentive sequence labeling model. It receives the same sentence input and a different query position p to extract all overlapping relations. Here, the red “Queens” is the token at query position p, hp is the hidden state of time-step p, ht is the hidden vector of time-step t, at is the attention weights and ct is the attention-pooling vector.
图3:我们的位置注意序列标记模型的体系结构。它接收相同的句子输入和不同的查询位置p以提取所有重叠关系。在这里,红色“ Queens”是查询位置p处的标记,hp是时间步长p的隐藏状态,ht是时间步长t的隐藏向量,at是注意力权重,ct是注意力集中向量 。
where WH , Wp, Wh, v are parameters to be learned, hj , hp, ht are the hidden states at position j, p and t respectively, stj is the score computed by comparing hp and ht with each of the sentence state hj , and atj is the attention weight produced by normalization of stj . It means that hp, the state at the position that we attend to, is used for comparing with the sentence representations to encode position information, and ht is used for matching the sentence representations against itself (self-matching) to collect information from the context (Wang et al. 2017). The positionattention mechanism produces different sentence representations according to the query position p, and thus solves the problem for modeling different tag sequences of a sentence. The following tag decoder can predict completely distinct labels given the same sentence and different query positions.CRF Decoder It is shown beneficial for sequence labeling model to consider the correlations between labels in neighborhoods and jointly decode the best chain of labels. Thus, we use CRF for jointly decoding, instead of independently decoding each label.
其中WH,Wp,Wh,v是要学习的参数,hj,hp,ht分别是位置j,p和t处的隐藏状态,stj是通过将hp和ht与每个句子状态hj进行比较而得出的分数, atj是stj归一化产生的注意力权重。这意味着hp(我们所处位置的状态)用于与句子表示进行比较以编码位置信息,而ht用于将句子表示与自身进行匹配(自我匹配)以从上下文中收集信息(Wang et al.2017)。位置注意机制根据查询位置p产生不同的句子表示,从而解决了对句子的不同标签序列进行建模的问题。在给定相同的句子和不同的查询位置的情况下,以下标签解码器可以预测完全不同的标签。
CRF解码器 对于序列标记模型来说,考虑邻域中的标记之间的相关性并共同解码最佳标记链被证明是有益的。因此,我们使用CRF进行联合解码,而不是独立地解码每个标记。
Thus, we use CRF for jointly decoding, instead of independently decoding each label. We consider Z = {zt}n to be the input sequence scores, which is generated from position-aware sentence representation ut:
因此,我们使用CRF进行联合解码,而不是独立地解码每个标签。我们认为Z = {zt} n是输入序列分数,它是根据位置感知语句表示ut生成的:
where zt ∈ RNt is the tag scores of the t-th word, and Nt is the number of distinct tags. Consider Zt,j as the score of the j-th tag at position t. For a sequence of labels y = {yt}tn=1 we define the decoding score as:
其中zt∈RNt是第t个单词的标签分数,Nt是不同标签的数量。将Zt,j视为在位置t处第j个标签的分数。对于标签序列y =(yt } tn = 1我们定义解码分数为:
where A is transition matrix such that Ai,j represents the transition score from the tag i to tag j. Then we get the conditional probability over all possible label sequences y with the following form:
其中A是过渡矩阵,使得Ai,j表示从标签i到标签j的过渡分数。然后,我们以以下形式获得所有可能的标签序列y的条件概率:
Extracting Entities and Overlapping Relations from Tag Sequences
From our tagging scheme, we know that the first entity of the triplet and its entity type can be extracted from the labels at the query position, and the second corresponding entity, if existed, as well as the relation type, can be obtained from the labels at other positions (see Figure 2). The overlapping relation extracting problem is solved because the first entity is allowed to belong to multiple triplets in a tag sequence. Through n tag sequence results considering different query positions, we can extract all overlapping relations in a sentence, as well as all entity mentions and their entity types. Moreover, the extracted entity types can be used to validate the triplets, for example, if the relation type is Born in, the entity type of the first argument must be PERSON.
从标签序列中提取实体和重叠关系
从我们的标记方案中,我们知道可以从查询位置的标签中提取三元组的第一个实体及其实体类型,而从其他位置的标签中获取第二个对应的实体(参见图2)。 如果存在,以及关系类型,因为第一实体被允许属于标签序列中的多个三元组,所以解决了重叠关系提取问题。通过考虑不同查询位置的n个标记序列结果,我们可以提取句子中所有重叠的关系,以及所有实体提及及其实体类型。此外,提取的实体类型可用于验证三元组,例如,如果关系类型为“出生于”,则第一个参数的实体类型必须为PERSON。
Experiments
Experiment Settings
Datasets We use two public datasets to demonstrate the effectiveness of our method: (1) NYT (Riedel, Yao, and McCallum 2010) is a news corpus sampled from 294k 1989-2007 New York Times news articles. We use the same dataset1 published by (Ren et al. 2017). The training data are automatically labeled using distant supervision, while 395 sentences are annotated by the author of (Hoffmann et al. 2011) and used as test data. (2) Wiki-KBP (Xiao and Weld 2012) utilizes 1.5M sentences sampled from 780k Wikipedia articles as training corpus, while test set consists of 289 sentences selected by the author of (Ren et al. 2017) from the manual annotations in 2013 KBP slot filling assessment results (Ellis et al. 2012). We use the public training data2 which are automatically labeled using distant supervision and handcrafted patterns by the author of (Liu et al. 2017). Statistics of the datasets are shown in Table 1.
Evaluation We mainly focus on overlapping relation extraction in this paper. Because our model directly extracts relations without detecting entities and their entity types first, we only evaluate the results of extracted triplets. We use the F1 metric computed from Precision (Prec.) and Recall (Rec.) for evaluation. A triplet is marked correct when its relation type and two corresponding entities are all correct, where the entity is considered correct if the head and tail offsets are both correct. We exclude all triplets with relation type of “None” (because we do not require them as negative samples) and create a validation set by randomly sampling 10%sentences from test set as previous studies (Ren et al. 2017; Zheng et al. 2017b) did.
数据集
我们使用两个公共数据集来证明我们方法的有效性:
(1)NYT(Riedel,Yao,and McCallum 2010)是一个新闻语料库,样本来自294k 1989-2007年《纽约时报》新闻文章,我们使用(Ren et al.2017)发布的相同数据集1。训练数据会使用远程监督自动标记,而395个句子由(Hoffmann et al。2011)的作者注释,并用作测试数据。
(2)Wiki-KBP(Xiao and Weld 2012)使用从780k Wikipedia文章中抽取的150万个句子作为训练语料,而测试集由(Ren et al.2017)的作者从2013年的手动注解中选择的289个句子组成KBP插槽填充评估结果(Ellis et al.2012)。我们使用公开培训数据2(Liu et al.2017)的作者使用远程监督和手工制作的模式自动标记这些数据。表1显示了数据集的统计信息。
评估
本文主要关注重叠关系提取。因为我们的模型直接提取关系,而不先检测实体及其实体类型,所以我们仅评估提取的三元组的结果。我们使用从Precision(Prec。)和Recall(Rec。)计算出的F1指标进行评估。当三元组的关系类型和两个对应的实体都正确时,则将其标记为正确;如果前后偏移都正确,则认为该实体正确。我们排除关系类型为“无”的所有三元组(因为我们不要求它们作为阴性样本),并通过从先前的研究中随机抽取测试集中的10%句子来创建验证集(Ren等人,2017; Zheng等人。 2017b)。
Implementation Details
For both datasets, the word embeddings are randomly initialized with 100 dimensions and the character embeddings are randomly initialized with 50 dimensions. The window size of CNN is set to 3 and the number of filters is 50. For Bi-LSTM encoder, the hidden vector length is set to 200. We use l2 regularization with a parameter of 0.001 to avoid overfitting. Parameter optimization is performed using Adam (Kingma and Ba 2014) with learning rate 0.001 and batch size 16. In addition, we randomly sample 10% negative tag sequences in which all words are labeled as “O” to reduce the training samples.
Baselines We compare our method on NYT and Wiki-KBP datasets with the following baselines: (1) MultiR (Hoffmann et al. 2011) models training label noise based on multi-instance multilabel learning; (2) DS-Joint (Li and Ji 2014) jointly extracts entities and relations using structured perceptron; (3) Cotype (Ren et al. 2017) learns jointly the representations of entity mentions, relation mentions and type labels; (4) ReHession (Liu et al. 2017) employs heterogeneous supervision from both knowledge base and heuristic patterns. (5) LSTM-CRF and LSTM-LSTM-Bias (Zheng et al. 2017b), the most related work to our method, converts the joint extraction task to a sequence labeling problem based on a novel tagging scheme. However, it cannot detect overlapping relations. Note that we do not compare our method with (Zeng et al. 2018) for two reasons. First, their model can decode only the first word of multi-word entity, while ours can detect the whole. In this paper, we conduct a stricter evaluation in which an entity is considered correct only if the head and tail offsets are both correct, which makes the task more challenging. Second, they do not report the result on manually labeled NYT test set. Instead, they use test set split from training data which is generated by distant supervision.
实施细节
对于两个数据集,单词嵌入都是使用100个维度随机初始化的,而字符嵌入则是使用50个维度随机初始化的。CNN的窗口大小设置为3,过滤器数为50.对于Bi-LSTM编码器,隐藏矢量长度设置为200。我们使用参数0.001的l2正则化来避免过度拟合。参数优化是使用Adam(Kingma and Ba 2014),学习率为0.001,批次大小为16进行的。此外,我们随机抽取10%的负面标签序列,其中所有单词均标记为“ O”以减少训练样本。基线我们将NYT和Wiki-KBP数据集上的方法与以下基线进行比较:
(1)MultiR(Hoffmann et al。2011)基于多实例多标签学习对训练标签噪声进行建模;
(2)DS-Joint(Li和Ji 2014)使用结构化感知器共同提取实体和关系;
(3)Cotype(Ren et al.2017)共同学习实体提及,关系提及和类型标签的表示;
(4)ReHession(Liu et al.2017)采用了知识库和启发式模式的异构监督。
(5)LSTM-CRF和LSTM-LSTM-Bias(Zheng et al.2017b)是与我们方法最相关的工作,基于一种新颖的标记方案将联合提取任务转换为序列标记问题。
但是,它无法检测到重叠关系。请注意,由于两个原因,我们没有将我们的方法与(Zeng等人2018)进行比较。首先,他们的模型只能解码多字实体的第一个字,而我们的模型可以检测整个字。在本文中,我们进行了更严格的评估,其中只有当头部和尾部偏移量都正确时,才将实体视为正确,这使任务更具挑战性。其次,他们不会在手动标记的NYT测试仪上报告结果。相反,他们使用从远程监督生成的训练数据中分离出的测试集。
Experimental Results and Analyses
Main Results
We report our experimental results on NYT and Wiki-KBP datasets in Table 2. It is shown that our model, position-attentive LSTM-CRF (PA-LSTM-CRF), outperforms all the baselines and achieves state-of-the-art F1 score on both datasets. Specially, compared to LSTM-LSTM-Bias (Zheng et al. 2017b), our method achieves significant improvements of 5.7% in F1 Wiki-KBP dataset, which is mainly because our model can extract overlapping relations. For NYT dataset, although no overlapping relation is manually labeled, our model also outperforms LSTM-LSTM-Bias by 4.3% in F1 due to a large improvement in Recall. We consider that it is because our model our model is capable of identifying more long-range relations, which will be further discussed in section of attention analysis. We also notice that the Precision of our model drops compared with LSTM-LSTM-Bias. This is mainly because many over-lapping relations are not annotated in the manually labeled test data. We will discuss it in the following paragraph.
Effect on Overlapping Relation Extraction
As Table 1 shows, there are about a third of sentences that contain overlapping relations in training data of both datasets, but much less in test sets. In fact, we find that many overlapping relations are omitted from the manually labeled test data in both datasets, especially for the relations of reverse pair of entities, e.g., “per:parents” and “per:children” in Wiki-KBP, or “/location/country/administrative divisions” and “/location/administrative division/country” in NYT. This may significantly affect the performance of our model on overlapping relation detection, especially the Precision. Thus, to discover the capability of our model to identify overlapping triplets, we simply add some gold triplets into test set of Wiki-KBP. For example, we add a ground-truth reverse triplet with “per:parents” type if “per:children” is originally labeled and vice versa. This will increase the number of sentences with overlapping relations in test set to about 50 from 23, but still much less in proportion to training data. We report the evaluation results compared with LSTM-LSTM-Bias in Table 3. It can be seen that our model achieves an large improvement of 6.9% in F1 and 11.2% in Precision compared with the results in Table 2, while the performance of LSTM-LSTM-Bias basically remain the same in F1. Moreover, for overlapping relations, our model significantly outperforms LSTM-LSTM-Bias by about 30%, which demonstrates the effectiveness of our method on extraction of overlapping relations.
实验结果与分析
主要结果
我们在表2中针对NYT和Wiki-KBP数据集报告了我们的实验结果,结果表明,我们的模型(即位置专注的LSTM-CRF(PA-LSTM-CRF))优于所有基线并达到了最新水平两个数据集上的F1得分。特别是,与LSTM-LSTM-Bias(Zheng et al.2017b)相比,我们的方法在F1 Wiki-KBP数据集中实现了5.7%的显着改进,这主要是因为我们的模型可以提取重叠关系。对于NYT数据集,尽管没有重叠这种关系是手动标记的,由于召回率有很大的改善,因此我们的模型在F1中也比LSTM-LSTM-Bias高出4.3%。我们认为这是因为我们的模型能够识别更多的远程关系,这将在注意力分析部分中进一步讨论。我们还注意到,与LSTM-LSTM-Bias相比,我们模型的Precision有所下降。这主要是因为在手动标记的测试数据中没有注释许多重叠的关系。我们将在以下段落中进行讨论。
对重叠关系提取的影响
如表1所示,两个数据集的训练数据中大约有三分之一的句子包含重叠关系,而在测试集中则少得多。实际上,我们发现在两个数据集中手动标记的测试数据中都省略了许多重叠关系,特别是对于反向实体对的关系,例如Wiki-KBP中的“每个:父母”和“每个:孩子”,或者纽约时报中的“ /位置/国家/行政区划”和“ /位置/国家行政区划/国家”。这可能会严重影响我们模型在重叠关系检测上的性能,尤其是精度。因此,为了发现我们的模型识别重叠的三胞胎的能力,我们只需在Wiki-KBP的测试集中添加一些金三胞胎即可。例如,如果“ per:儿童”最初带有标签,反之亦然。这将使测试集中具有重叠关系的句子数量从23个增加到大约50个,但与训练数据的比例仍然要少得多。我们在表3中报告了与LSTM-LSTM-Bias相比的评估结果。可以看出,与表2的结果相比,我们的模型在F1方面实现了6.9%的大幅改进,在Precision方面实现了11.2%的大幅改进,而LSTM-LSTM-Bias的性能在F1中基本保持不变。此外,对于重叠关系,我们的模型明显优于LSTM-LSTM-Bias约30%,这证明了我们的方法在提取重叠关系方面的有效性。
Ablation Study
We also conduct ablation experiments to study the effect of components of our model. As shown in Table 4, all the components play an important roles in our model. Consistent with previous work, the character-level representations are helpful to capture the morphological information and deal with OOV words in sequence labeling task (Ma and Hovy 2016). Introducing position attention mechanism for generating the position-aware representations seems an efficient way to incorporate the information of the query position compared with directly concatenating the the hidden vector at the query position to each state of the BiLSTM encoder. In addition, the self-matching in our position-attention mechanism also contributes to the final results for the reason of extracting more information from the context.
Comparison of Running Time While LSTM-LSTM-Bias or LSTM-CRF runs sequence tagging only once to extract non-overlapping relations, our model tags the same sentence for another n − 1 times in order to recognize all overlapping relations. This means our model is more time-consuming (O(n2) vs. O(n)). For instance, LSTM-CRF only predicts about 300 samples and consumes 2s on Wiki-KBP test set, while our model decodes about 7000 tag sequences and takes about 50s. However, testing can be speeded up by sharing the sentence representation before position attention because it is identical for the other n−1 times decoding. In this way, the running time of our model reduces to 16s. Moreover, we may also prune some query positions to further accelerate in real application because it is impossible for some words to be the head of an entity.
消融研究
我们还进行了消融实验,以研究模型组件的效果。如表4所示,所有组件都在模型中起着重要作用。与以前的工作一致,字符级表示有助于捕获形态信息和在序列标记任务中处理OOV单词(Ma and Hovy 2016)。与直接将查询位置处的隐藏向量连接到BiLSTM编码器的每个状态相比,引入用于生成位置感知表示的位置注意机制似乎是合并查询位置信息的有效方法。此外,由于从上下文中提取了更多信息,因此我们的位置注意机制中的自我匹配也有助于最终结果。
运行时间比较
虽然LSTM-LSTM-Bias或LSTM-CRF仅运行一次序列标签以提取非重叠关系,但我们的模型将同一句子再标记n-1次,以便识别所有重叠关系。
这意味着我们的模型比较费时(O(n2)vs. O(n)),例如,LSTM-CRF仅预测约300个样本,在Wiki-KBP测试集上消耗2s,而我们的模型则解码约7000个标签序列,大约需要50秒钟。但是,可以通过在位置注意之前共享句子表示来加快测试速度,因为它与其他n-1次解码相同。这样,我们的模型的运行时间减少到16s。此外,我们还可以修剪一些查询位置以在实际应用中进一步加快速度,因为某些词不可能成为实体的头部。
Further Analysis for Attention
Detecting Long-Range Relations It is shown in previous work that attention mechanism is helpful to capturing the long range dependencies between arbitrary tokens, which is very important for detecting triplets composed of entities that have a long distance from each other. To further prove the effectiveness of position attention, we analyze the F1 score on triplets with different distances between entities on Wiki-KBP dataset. As shown in Figure 4, we find that the performance of our model remains stable as the distance between entities increases, while that of LSTM-LSTM-Bias drops significantly. It means that our model can effectively model the dependencies between entities despite a long distance between them.
Case Study for Attention Weights We select two sentences from the test set of Wiki-KBP to show the alignment of our position-attention for case study. As shown in Figure 5, the information of the first entity at the query position, together with the context evidence for recognizing relations, is encoded into the position-aware representations regardless of distance between entities. For instance, in Figure 5(a), the second entity “Albert” pays more attention to the possible corresponding entities “Anderson” and “Carol”, as well as the key context word “sons” that contains information of relation. The model also produces reasonable alignment at other query position as Figure 5(b) shows. In Figure 5©, “Thousand Oaks” can still attend to the first entity “Sparky Anderson” despite a long distance between them.
进一步分析注意
检测远距离关系在先前的工作中表明,注意力机制有助于捕获任意标记之间的远距离依赖关系,这对于检测由彼此之间具有较长距离的实体组成的三元组非常重要。为了进一步证明位置注意的有效性,我们分析了Wiki-KBP数据集上实体之间具有不同距离的三元组的F1分数。如图4所示,我们发现随着实体之间距离的增加,我们模型的性能保持稳定,而LSTM-LSTM-Bias的性能却显着下降。这意味着我们的模型可以有效地建模实体之间的依赖关系,尽管它们之间的距离很长。注意权重的案例研究我们从Wiki-KBP的测试集中选择两个句子,以显示案例研究中我们的位置注意的对齐方式。如图5所示,与实体之间的距离无关,在查询位置的第一个实体的信息以及用于识别关系的上下文证据被编码为位置感知表示。例如,在图5(a)中,第二个实体“阿尔伯特”更加关注可能的对应实体“安德森”和“卡罗尔”,以及包含关联信息的关键上下文单词“子”。该模型还在其他查询位置产生了合理的对齐,如图5(b)所示。在图5(c)中,“千橡树”仍然可以参加第一个实体“ Sparky Anderson”,尽管它们之间的距离很长。
Figure 5: Part of attention matrices for position-attention. Each row is the attention weights of the whole sentence for the current token. The query position is marked by an arrow, the red tokens indicate the first entity extracted at the query position, and the blue tokens indicates the second corresponding entities. (a) and (b) are the attention matrices of different query positions for the same sentence, and © is the attention matrix for a sentence with long-range entity pairs.
图5:位置注意的部分注意矩阵。每行是当前令牌的整个句子的关注权重。查询位置由箭头标记,红色标记指示在查询位置提取的第一个实体,蓝色标记指示第二个对应的实体。(a)和(b)是同一句子的不同查询位置的注意矩阵,(c)是具有远程实体对的句子的注意矩阵。