浅析Linux namespace
环境背景
Linux版本:linux-4.10.5
Linux namespace 作用:
Linux Namespace是一种Linux Kernel提供的资源隔离方案,提供Pid,Network,Ipc,Uts,Mount等资源的隔离,每个Namespace下的这些资源对于其他Namespace是不可见的
作用对象:进程
分析
对Linux namespace的分析会结合一些简单的源码做一些分析,代码只关注Linux namespace相关的部分,只是浅析逻辑,不涉及细节分析。有需要深入的可以自行跟踪源码分析。
好了,不多说,进入正文。
Linux namespace是作用于进程的,也就是说每个进程都有属于自己的namespce,所以在进程描述符中,就可以找到namespace的结构体信息。
代码目录:linux-4.10.5\include\linux\sched.h
struct task_struct {
...
/* namespaces */
struct nsproxy *nsproxy
...
}
# 由于这个结构体的信息比较多,这里只关注namespace相关的信息,所以直接搜索namespace或者nsproxy
这里的nssproxy结构体就是我们要分析的namespace的结构体,所以直接看它里面有什么东西(task_struct这个结构体也很值得大家去深入了解,会对进程有更加深刻的认识)
nsproxy
代码路径:linux-4.10.5\include\linux\nsproxy.h
struct mnt_namespace;
struct uts_namespace;
struct ipc_namespace;
struct pid_namespace;
struct cgroup_namespace;
struct fs_struct;
/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* The pid namespace is an exception -- it's accessed using
* task_active_pid_ns. The pid namespace here is the
* namespace that children will use.
*
* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
*
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied.
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct cgroup_namespace *cgroup_ns;
};
extern struct nsproxy init_nsproxy;
大家仔细阅读以下上面的注释,就可以知道当一个fork出来的进程,nsproxy的信息也会被复制到新的进程中。
上面的nsproxy有6个主要的结构体,下面展示每个结构体中包含了哪些内容。
uts_namespace
代码路径:include/linux/utsname.h
UTS(UNIX Time-sharing System)namespace提供了主机名和域名的隔离。
struct uts_namespace {
struct kref kref;
struct new_utsname name;
struct user_namespace *user_ns;
struct ucounts *ucounts;
struct ns_common ns;
};
extern struct uts_namespace init_uts_ns;
这里又包含了很多个结构体,这里有个user_namespace是需要我们额外关注的(在Linux3.8才开始有)
user_namespace
代码路径:include\linux\user_namespace.h
主要用来隔离安全相关的标识符(idebtifier)和属性(attribute),包括用户ID、用户组ID、root目录、key(密钥)以及特殊权限。
struct user_namespace {
struct uid_gid_map uid_map;
struct uid_gid_map gid_map;
struct uid_gid_map projid_map;
atomic_t count;
struct user_namespace *parent;
int level;
kuid_t owner;
kgid_t group;
struct ns_common ns;
unsigned long flags;
/* Register of per-UID persistent keyrings for this namespace */
#ifdef CONFIG_PERSISTENT_KEYRINGS
struct key *persistent_keyring_register;
struct rw_semaphore persistent_keyring_register_sem;
#endif
struct work_struct work;
#ifdef CONFIG_SYSCTL
struct ctl_table_set set;
struct ctl_table_header *sysctls;
#endif
struct ucounts *ucounts;
int ucount_max[UCOUNT_COUNTS];
};
ipc_namespace
代码路径:include/linux/ipc_namespace.h
进程间通信(Inter-Process Communication,IPC)涉及的IPC资源包括常见的信号量、消息队列、共享内存
struct ipc_namespace {
atomic_t count;
struct ipc_ids ids[3];
int sem_ctls[4];
int used_sems;
unsigned int msg_ctlmax;
unsigned int msg_ctlmnb;
unsigned int msg_ctlmni;
atomic_t msg_bytes;
atomic_t msg_hdrs;
size_t shm_ctlmax;
size_t shm_ctlall;
unsigned long shm_tot;
int shm_ctlmni;
/*
* Defines whether IPC_RMID is forced for _all_ shm segments regardless
* of shmctl()
*/
int shm_rmid_forced;
struct notifier_block ipcns_nb;
/* The kern_mount of the mqueuefs sb. We take a ref on it */
struct vfsmount *mq_mnt;
/* # queues in this ns, protected by mq_lock */
unsigned int mq_queues_count;
/* next fields are set through sysctl */
unsigned int mq_queues_max; /* initialized to DFLT_QUEUESMAX */
unsigned int mq_msg_max; /* initialized to DFLT_MSGMAX */
unsigned int mq_msgsize_max; /* initialized to DFLT_MSGSIZEMAX */
unsigned int mq_msg_default;
unsigned int mq_msgsize_default;
/* user_ns which owns the ipc ns */
struct user_namespace *user_ns;
struct ucounts *ucounts;
struct ns_common ns;
};
mnt_namespace
代码路径:fs/mount.h
通过隔离文件系统挂载点对文件系统做隔离
struct mnt_namespace {
atomic_t count;
struct ns_common ns;
struct mount * root;
struct list_head list;
struct user_namespace *user_ns;
struct ucounts *ucounts;
u64 seq; /* Sequence number to prevent loops */
wait_queue_head_t poll;
u64 event;
unsigned int mounts; /* # of mounts in the namespace */
unsigned int pending_mounts;
};
pid_namespace
代码路径:include/linux/pid_namespace.h
在Linux系统中。pid为1的进程是init(或systemd),地位非常特殊。它作为所有系统的父进程,维护一张进程表,不断检查进程的状态,一旦有某个子进程因为父进程错误成为“孤儿”进程,1号进程就会负责回收这个子进程并最终回收资源,结束进程。
struct pid_namespace {
struct kref kref;
struct pidmap pidmap[PIDMAP_ENTRIES];
struct rcu_head rcu;
int last_pid;
unsigned int nr_hashed;
struct task_struct *child_reaper;
struct kmem_cache *pid_cachep;
unsigned int level;
struct pid_namespace *parent;
#ifdef CONFIG_PROC_FS
struct vfsmount *proc_mnt;
struct dentry *proc_self;
struct dentry *proc_thread_self;
#endif
#ifdef CONFIG_BSD_PROCESS_ACCT
struct fs_pin *bacct;
#endif
struct user_namespace *user_ns;
struct work_struct proc_work;
kgid_t pid_gid;
int hide_pid;
int reboot; /* group exit code if this pidns was rebooted */
struct ns_common ns;};
net
代码路径:include\net\net_namespace.h
实现网络隔离,使用ip netns可以查看network namespace的详情
struct net {
atomic_t passive; /* To decided when the network
* namespace should be freed.
*/
atomic_t count; /* To decided when the network
* namespace should be shut down.
*/
spinlock_t rules_mod_lock;
atomic64_t cookie_gen;
struct list_head list; /* list of network namespaces */
struct list_head cleanup_list; /* namespaces on death row */
struct list_head exit_list; /* Use only net_mutex */
struct user_namespace *user_ns; /* Owning user namespace */
struct ucounts *ucounts;
spinlock_t nsid_lock;
struct idr netns_ids;
struct ns_common ns;
struct proc_dir_entry *proc_net;
struct proc_dir_entry *proc_net_stat;
#ifdef CONFIG_SYSCTL
struct ctl_table_set sysctls;
#endif
struct sock *rtnl; /* rtnetlink socket */
struct sock *genl_sock;
struct list_head dev_base_head;
struct hlist_head *dev_name_head;
struct hlist_head *dev_index_head;
unsigned int dev_base_seq; /* protected by rtnl_mutex */
int ifindex;
unsigned int dev_unreg_count;
/* core fib_rules */
struct list_head rules_ops;
struct net_device *loopback_dev; /* The loopback */
struct netns_core core;
struct netns_mib mib;
struct netns_packet packet;
struct netns_unix unx;
struct netns_ipv4 ipv4;
#if IS_ENABLED(CONFIG_IPV6)
struct netns_ipv6 ipv6;
#endif
#if IS_ENABLED(CONFIG_IEEE802154_6LOWPAN)
struct netns_ieee802154_lowpan ieee802154_lowpan;
#endif
#if defined(CONFIG_IP_SCTP) || defined(CONFIG_IP_SCTP_MODULE)
struct netns_sctp sctp;
#endif
#if defined(CONFIG_IP_DCCP) || defined(CONFIG_IP_DCCP_MODULE)
struct netns_dccp dccp;
#endif
#ifdef CONFIG_NETFILTER
struct netns_nf nf;
struct netns_xt xt;
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct netns_ct ct;
#endif
#if defined(CONFIG_NF_TABLES) || defined(CONFIG_NF_TABLES_MODULE)
struct netns_nftables nft;
#endif
#if IS_ENABLED(CONFIG_NF_DEFRAG_IPV6)
struct netns_nf_frag nf_frag;
#endif
struct sock *nfnl;
struct sock *nfnl_stash;
#if IS_ENABLED(CONFIG_NETFILTER_NETLINK_ACCT)
struct list_head nfnl_acct_list;
#endif
#if IS_ENABLED(CONFIG_NF_CT_NETLINK_TIMEOUT)
struct list_head nfct_timeout_list;
#endif
#endif
#ifdef CONFIG_WEXT_CORE
struct sk_buff_head wext_nlevents;
#endif
struct net_generic __rcu *gen;
/* Note : following structs are cache line aligned */
#ifdef CONFIG_XFRM
struct netns_xfrm xfrm;
#endif
#if IS_ENABLED(CONFIG_IP_VS)
struct netns_ipvs *ipvs;
#endif
#if IS_ENABLED(CONFIG_MPLS)
struct netns_mpls mpls;
#endif
struct sock *diag_nlsk;
atomic_t fnhe_genid;
};
cgroup_namespace
代码路径:include\linux\cgroup.h
提供cgroup的一些隔离
struct cgroup_namespace {
atomic_t count;
struct ns_common ns;
struct user_namespace *user_ns;
struct ucounts *ucounts;
struct css_set *root_cset;
};
Linux namespace的几个重要的结构体就是这些,深入研究的需要进入源码。
fork流程分析
下面分析下Linux namespace在整个生成进程中是如何创建的。
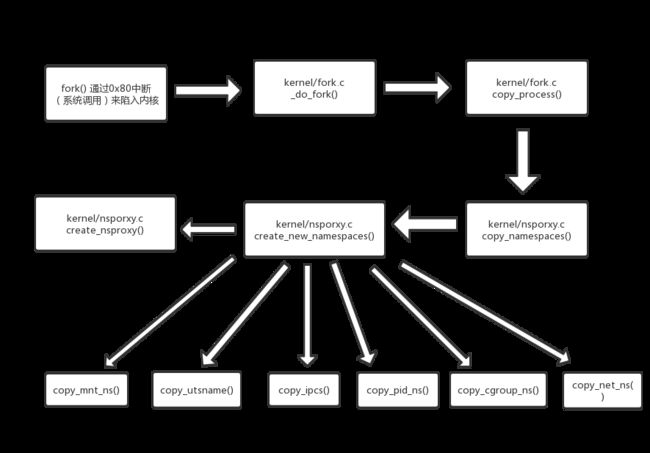
Linux使用fork函数来创建一个进程
代码路径:kernel/fork.c
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
return _do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL, 0);
}
#endif
通过上面的信息可以看到主要是fork和vfork,而且两个都是调用_do_fork。
这里分析的是Linux namespace 所以重点关注namespace相关的,忽略一些代码
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
...
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
}
...
copy_process是重点,其它可以个人再去分析。
/*
* This creates a new process as a copy of the old one,
* but does not actually start it yet.
*
* It copies the registers, and all the appropriate
* parts of the process environment (as per the clone
* flags). The actual kick-off is left to the caller.
*/
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
...
cgroup_fork(p);
....
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
...
}
上面终于看到我们要分析的Linux namespace的函数了。
代码路径:kernel/nsproxy.c
/*
* called from clone. This now handles copy for nsproxy and all
* namespaces therein.
*/
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET |
CLONE_NEWCGROUP)))) {
get_nsproxy(old_ns);
return 0;
}
if (!ns_capable(user_ns, CAP_SYS_ADMIN))
return -EPERM;
/*
* CLONE_NEWIPC must detach from the undolist: after switching
* to a new ipc namespace, the semaphore arrays from the old
* namespace are unreachable. In clone parlance, CLONE_SYSVSEM
* means share undolist with parent, so we must forbid using
* it along with CLONE_NEWIPC.
*/
if ((flags & (CLONE_NEWIPC | CLONE_SYSVSEM)) ==
(CLONE_NEWIPC | CLONE_SYSVSEM))
return -EINVAL;
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
if (IS_ERR(new_ns))
return PTR_ERR(new_ns);
tsk->nsproxy = new_ns;
return 0;
}
上面主要的重点是create_new_namespaces
/*
* Create new nsproxy and all of its the associated namespaces.
* Return the newly created nsproxy. Do not attach this to the task,
* leave it to the caller to do proper locking and attach it to task.
*/
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs)
{
struct nsproxy *new_nsp;
int err;
new_nsp = create_nsproxy();
if (!new_nsp)
return ERR_PTR(-ENOMEM);
new_nsp->mnt_ns = copy_mnt_ns(flags, tsk->nsproxy->mnt_ns, user_ns, new_fs);
if (IS_ERR(new_nsp->mnt_ns)) {
err = PTR_ERR(new_nsp->mnt_ns);
goto out_ns;
}
new_nsp->uts_ns = copy_utsname(flags, user_ns, tsk->nsproxy->uts_ns);
if (IS_ERR(new_nsp->uts_ns)) {
err = PTR_ERR(new_nsp->uts_ns);
goto out_uts;
}
new_nsp->ipc_ns = copy_ipcs(flags, user_ns, tsk->nsproxy->ipc_ns);
if (IS_ERR(new_nsp->ipc_ns)) {
err = PTR_ERR(new_nsp->ipc_ns);
goto out_ipc;
}
new_nsp->pid_ns_for_children =
copy_pid_ns(flags, user_ns, tsk->nsproxy->pid_ns_for_children);
if (IS_ERR(new_nsp->pid_ns_for_children)) {
err = PTR_ERR(new_nsp->pid_ns_for_children);
goto out_pid;
}
new_nsp->cgroup_ns = copy_cgroup_ns(flags, user_ns,
tsk->nsproxy->cgroup_ns);
if (IS_ERR(new_nsp->cgroup_ns)) {
err = PTR_ERR(new_nsp->cgroup_ns);
goto out_cgroup;
}
new_nsp->net_ns = copy_net_ns(flags, user_ns, tsk->nsproxy->net_ns);
if (IS_ERR(new_nsp->net_ns)) {
err = PTR_ERR(new_nsp->net_ns);
goto out_net;
}
return new_nsp;
out_net:
put_cgroup_ns(new_nsp->cgroup_ns);
out_cgroup:
if (new_nsp->pid_ns_for_children)
put_pid_ns(new_nsp->pid_ns_for_children);
out_pid:
if (new_nsp->ipc_ns)
put_ipc_ns(new_nsp->ipc_ns);
out_ipc:
if (new_nsp->uts_ns)
put_uts_ns(new_nsp->uts_ns);
out_uts:
if (new_nsp->mnt_ns)
put_mnt_ns(new_nsp->mnt_ns);
out_ns:
kmem_cache_free(nsproxy_cachep, new_nsp);
return ERR_PTR(err);
}
上面的代码就能看到熟悉的身影了
总结
- 先调用create_nsproxy 创建一个nsproxy
- copy_mnt_ns 创建一个mnt_namespace
- copy_utsname 创建一个uts_namespace
- copy_ipcs 创建一个ipc_namespace
- copy_pid_ns 创建一个pid_namespace
- copy_cgroup_ns 创建一个cgroup_namespace
- copy_net_ns 创建一个net
这里文章主要是分析个流程,没有对具体的代码进行分析。