【python】爬虫入门:爬取网易云音乐的歌曲评论、用户歌单、用户听歌记录等
目录
一、概述
二、爬取流程
1、爬取评论
1.1、资源定位
1.2、爬取准备
1.3、代码实现
2、爬取听歌记录
2.1、资源定位
2.2、爬取准备
2.3、js劫持
三、总结
一、概述
第一次学爬虫,正常来讲应该是爬百度百科或者是豆瓣之类的,但这俩网站我没兴趣,因此选择爬网易云。
学习过程中主要参考该网址。
二、爬取流程
1、爬取评论
1.1、资源定位
当我们进入网易云音乐的网页版,进入一首歌的页面:
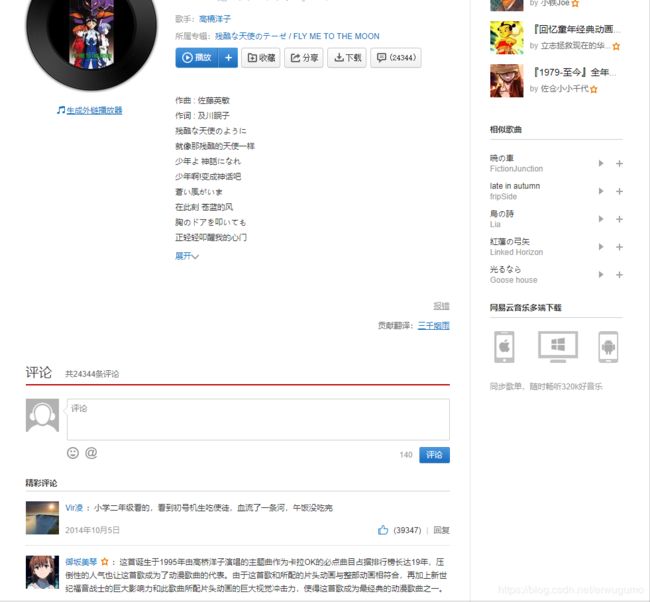
我们可以看到歌名、歌词、评论、相似歌曲、收藏该歌曲的歌单等。
这些信息我们如何得知的?
浏览器向网易的服务器发送请求,网易的服务器返回数据,浏览器再给我们看。
嗯,意思就是,如果我们能模仿浏览器的请求,让网易的服务器把我们想要的信息给我们,这样我们就能不断的收集信息了。
这也就是爬虫的基本功能了。
怎么看浏览器向网易发送请求呢?f12。

当我们在按下f12之后按f5刷新网页时,控制台就会显示所有的浏览器向客户端发出的请求。
注意,第一行为“Network”。filter选择“All”。
下面有一大堆乱七八糟的东西:jpg、png、js这些是文件,还有一些像是网址的东西:cdns?csrf_token=。看不明白。
由于我们需要的是浏览器向服务器发出的请求,我们不要选择“All”,选择“XHR”。这个XHR是个什么?
XMLHttpRequest对象(简称XHR)是ajax技术的核心,ajax可以无刷新更新页面得益于xhr。
没怎么看明白,不过不要紧,这个是前端的活,不用理解。看XHR之后,只剩下以下几项:
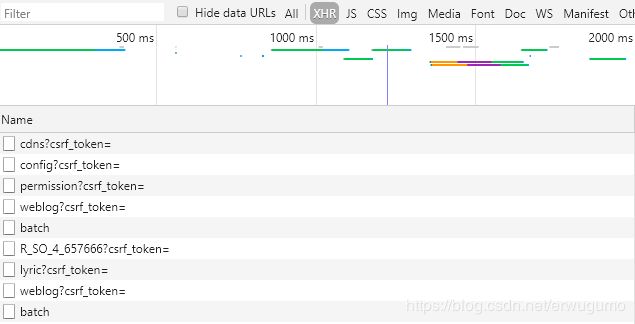
这不是之前看起来很像是网页的东西嘛。随便点进去一个看看,这个lyric看上去应该是歌词:

嗯,猜对了。也就是说,我们想要爬取歌词的话,就要分析这个。
R_SO呢?这个是啥?
看上去应该是评论。成了,我们需要的就是这个。
于是我们就找到了评论的位置。
对于一些小网站,对反爬虫没什么要求或者是没有那么多资源的话,整个网页的内容都在element里面。xhr是一个没有的,比如这样一个小说网站:
网易云应该是爬的人太多了加上为了用户体验,所以用了那么多XHR。
1.2、爬取准备
既然我们知道了评论是由XHR中的某一条显示的,那就看看这一条里面有什么:
先看Headers,这是浏览器向服务器发送的信息储存的位置:
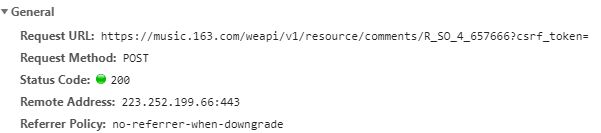
第一个url很有用,要记下来。
再看Response Headers,回复头部?应该是服务器返回的信息的头部:
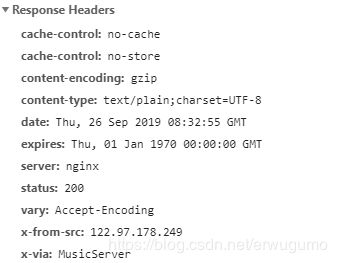
时间啊,解码方式什么的。服务器竟然用的是nginx,有点熟悉。
然后是Request Headers,重头戏:
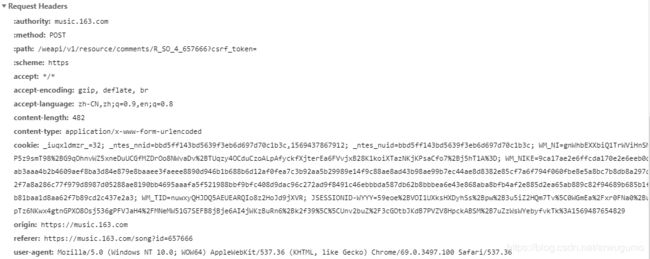
这个是浏览器发往服务器的request的头部,主要记住两个参数:referer和user-agent。这两个参数在服务器返回cheating时候加载head里。
接下来是Form data。不知道有什么用:

来分析一下:
我们的浏览器向服务器发送一条请求:
发送的地址应该就是第一个url,通过Request Headers表明我的身份。那问题来了:如何表明我的目的呢?
比如说我的目的是要残酷天使的行动纲领这首歌的第100-200条评论,那么我们要发给服务器的信息有:
歌名:残酷天使的行动纲领
需求:评论
条数:100
起始评论:第100条
一共四个关键信息。
根据我们分析这个XHR,显示提供的信息有:url、浏览器配置、时间等。
平平无奇。
这说明有隐式信息。
首先分析显示信息的url:
https://music.163.com/weapi/v1/resource/comments/R_SO_4_657666?csrf_token=
当我们调换不同的歌的时候,发现该url整体不会变动,只有R_SO后面的数字会变。因此,这数字就是我们传递的一个变量,该数字应与歌一一对应。
url中的comments指的是评论,可以与我们的需求对应上。
现在还有两个关键信息,不能显示传递:起始评论和评论条数。
url有传递过去的参数。藏在哪里呢?
藏在Form Data里。
这两串好长的字符串是加密过的,解密的过程参见我在第一部分所示的链接。
我的主要代码也是参考的这位大佬。
解密的过程可以不去在意,但是这种定位方式一定要学会,十分有用。
1.3、代码实现
大佬的代码为python2,如下:
#coding = utf-8
from Crypto.Cipher import AES
import base64
import requests
import json
headers = {
'Cookie': 'appver=1.5.0.75771;',
'Referer': 'http://music.163.com/'
}
first_param = "{rid:\"\", offset:\"0\", total:\"true\", limit:\"20\", csrf_token:\"\"}"
second_param = "010001"
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
forth_param = "0CoJUm6Qyw8W8jud"
def get_params():
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data)
return response.content
if __name__ == "__main__":
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_30953009/?csrf_token="
params = get_params();
encSecKey = get_encSecKey();
json_text = get_json(url, params, encSecKey)
json_dict = json.loads(json_text)
print json_dict['total']
for item in json_dict['comments']:
print item['content'].encode('gbk', 'ignore')有以下几点要注意:
第一,代码使用了Crypto.Cipher包,这个包我安装失败,可以通过安装pycrypto代替。
第二,由于我用的python3,而python3和2的一大区别就是str与bytes的分家,所以有以下几句代码要更改一下:
def get_params():
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
h_encText = AES_encrypt(first_param.encode(), first_key, iv)#第一个参数要更改
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text2=bytes(pad * chr(pad),encoding='gbk')#这里也要改
text3 = text + text2#这里也要改
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text3)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text第三,该url需要五个参数,在代码中体现为:
first_param = "{rid:\"\", offset:\"0\", total:\"true\", limit:\"20\", csrf_token:\"\"}"即:rid,offset,total,limit,token。
整份代码绝大多数工作就是把这五个参数组成的bytes转换为加密后的形式。
其中,rid是歌曲id,这个为空的话就直接默认是url带的参数,所以可以无视掉,当我们需要在爬虫中换歌的时候就要用这个了;
offset是偏移量,也就是相对第一个评论向后便宜多少;
total在第一页是true,其余是false。
其实知道参数以后自己试就可以了,整个爬虫最难的就在于解密,其次就是url传递的参数的获取。
然后就是按部就班的带参数post,解析返回值即可。
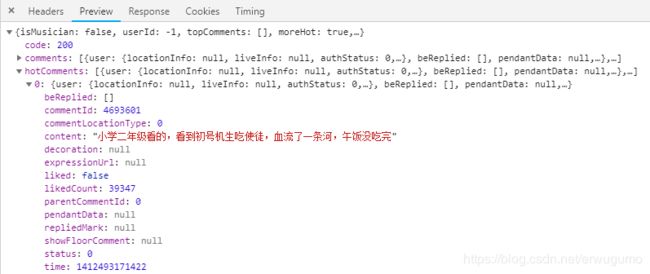
其四,在解析返回值时,返回的是一个嵌套字典,字典对应的关键字可以在PreView中查看,如下:

这就指的是“热门评论”中的第一条的内容。
效果如下:

这样就实现了评论的爬取。
2、爬取听歌记录
这部分才是我自己主要做的。难点就在于url的参数找不到。
2.1、资源定位
类似评论,我们要想找听歌记录,肯定要去他的个人主页。这个有点涉及隐私,我就以爬我自己的为例:
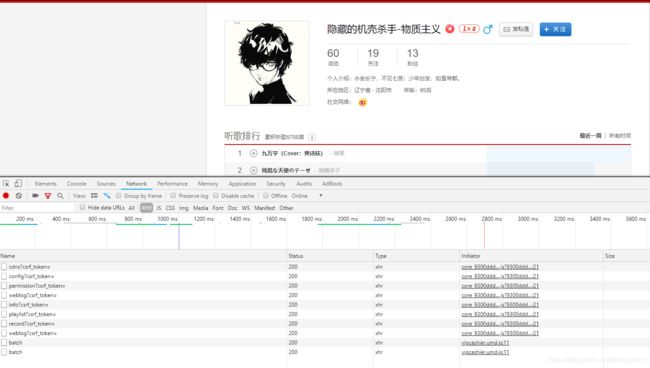
如图,XHR有以下几个,很容易就一眼看到records,以我半吊子的英语水平也能看得出来这个是记录的意思。
点进去看一下吧:

不出所料,果然是。不过网页版没法看听歌次数,而是用一个score代替,看上去这个分值应该就是100*count/countMAX,看我第一首歌是100分,第二首就只有41分了。
2.2、爬取准备
爬听歌记录肯定也要看Headers啊。
先看General:
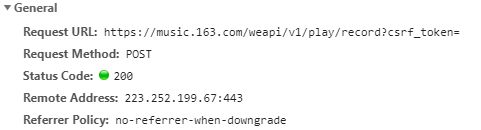
wc,这个url好狠毒,一个参数都没有显示给我们,也就是说全部参数都是在DataForm里。
看看Request Headers:
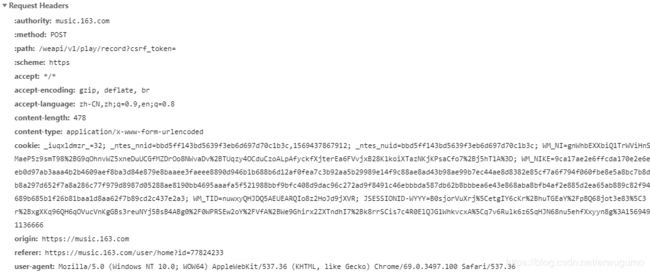
平平无奇,只有referer变成了我的主页的链接。看来想要攻克这个,就得去找url带的参数了。
参数不可能是凭空出来的,它一定是一个函数生成的,我们找到这个函数就好了。怎么找呢?要看控制台中的一项:

也就是initiator。这一列中就是对应的XHR的妈妈,调用这个文件产生所需的XHR。我们需要的文件叫core_乱码.js。
看看这个文件里有什么:
wdnmd死机了。这文件有点大,复制到notepad++里面好长好长。我们需要什么呢?需要Data Form里面的params和encSerKey。直接ctrl+f找一找,定位到第90行:
(function()
{
var c4g=NEJ.P,et7m=c4g("nej.g"),v4z=c4g("nej.j"),k4o=c4g("nej.u"),
Sj0x=c4g("nm.x.ek"),l4p=c4g("nm.x");
if(v4z.bg5l.redefine)
return;
window.GEnc=true;
var bry7r=function(cxa3x)
{
var m4q=[];
k4o.be5j(cxa3x,function(cwZ3x)
{
m4q.push(Sj0x.emj[cwZ3x])
});
return m4q.join("")
};
var cwX3x=v4z.bg5l;
v4z.bg5l=function(Z5e,e4i)
{
var i4m={},e4i=NEJ.X({},e4i),md9U=Z5e.indexOf("?");
if(window.GEnc&&/(^|\.com)\/api/.test(Z5e)&&!
(e4i.headers&&e4i.headers[et7m.zx3x]==et7m.Gv5A)&&!e4i.noEnc)
{
if(md9U!=-1)
{
i4m=k4o.gU7N(Z5e.substring(md9U+1));
Z5e=Z5e.substring(0,md9U)
}
if(e4i.query)
{
i4m=NEJ.X(i4m,k4o.fO7H(e4i.query)?k4o.gU7N(e4i.query):e4i.query)
}
if(e4i.data)
{
i4m=NEJ.X(i4m,k4o.fO7H(e4i.data)?k4o.gU7N(e4i.data):e4i.data)
}
i4m["csrf_token"]=v4z.gQ7J("__csrf");
Z5e=Z5e.replace("api","weapi");
e4i.method="post";
delete e4i.query;
window.console.info(i4m);//这一行是后加的
var bUS6M=window.asrsea(JSON.stringify(i4m),
bry7r(["流泪","强"]),
bry7r(Sj0x.md),
bry7r(["爱心","女孩","惊恐","大笑"]));
e4i.data=k4o.cx5C(
{
params:bUS6M.encText,
encSecKey:bUS6M.encSecKey
})
}
cwX3x(Z5e,e4i)
};
v4z.bg5l.redefine=true
}
)();我真是日了,原文件里面一行代码结果弄出来这么多行。看最后可以看到我们需要的params和encSecKey。
这俩怎么来的呢?看一下它们是BUS6M的两个属性,这个BUS6M又是怎么来的?是window.asrsea的返回值。
这个window.asrsea就是加密算法了。具体解析去看我上文的链接。
现在只看这个函数的参数,有四个,第一个是i4m转为string格式,剩下三个看上去怪怪的。你说这个流泪啊,强啊,爱心,女孩什么的都是常量,肯定不是我们要的参数,那参数只可能是i4m或者Sj0x.md了。先看前者吧。
看上一行,i4m应该是一个字典,里面的键有csrf_token,那有九成概率确定它就是参数的原始形态了。
我们只要输出i4m不就行了。怎么输出呢?
修改这个core就行啊。
那问题来了,这文件在人家网易的服务器里,浏览器是调用服务器的这个文件生成参数加密前的序列的。我又没法进网易的服务器。
这时候就需要js劫持了。
2.3、js劫持
简而言之,就是浏览器要使用core这个文件的时候,不去向网易要这个文件,而是和我要——反正我都有这个文件的所有代码了,从我这里运行一样能得到结果不是。
怎么实现“浏览器和我要这个文件”的功能呢?
要用到fiddler。这个程序很厉害,很简单就能实现js劫持:
上面链接中的方法不好用,我建议用我的方法:
第一:安装并使用fiddler。安装很简单,使用它可能会有一点麻烦,要是有代理就更麻烦。我建议使用
Chrome的switchOmega插件,选择系统代理。
判断是否好用的一个方法为:开着fiddler,随便开一个网址,如果fiddler界面出来一堆花花绿绿的就是好用。
第二:修改fiddler的过滤器。默认过滤器是不会显示js文件的请求的,我们需要知道浏览器发出调用core的请求,因此要把它显示出来。如下图:
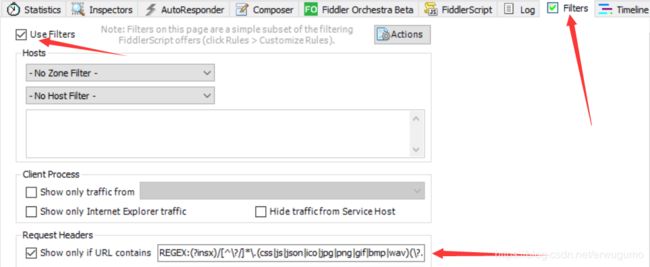
在Show only if URL contains中添加如下的正则表达式:
REGEX:(?insx)/[^\?/]*\.(css|js|json|ico|jpg|png|gif|bmp|wav)(\?.*)?$即可。
第三:设定劫持条件。如下图:
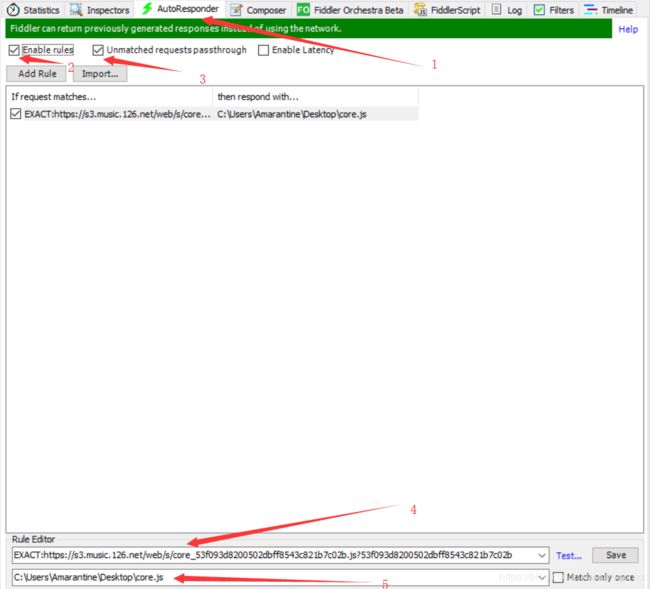
在界面右侧选择AutoResponder,也就是1;下面三个框勾上前面两个也就是2和3;add之后添加4和5,其中4不用自己写,5是我们上面复制下来的core.js的绝对地址,我是放在桌面的,加上输出i4m的那一句。
如何自动填充4呢?
首先清除浏览器缓存,如果不清除缓存,浏览器会将core下载下来,不会再次请求服务器(在这里可能也可以改,但我没试过),fiddler就找不到调用core的请求了。
然后进入网易云音乐用户主页,刷新,就可以看到了:

如图,第一条紫色的就是core的调用请求。左键单击,按住后拽到右边的AutoResponder里面,4就填充好了。
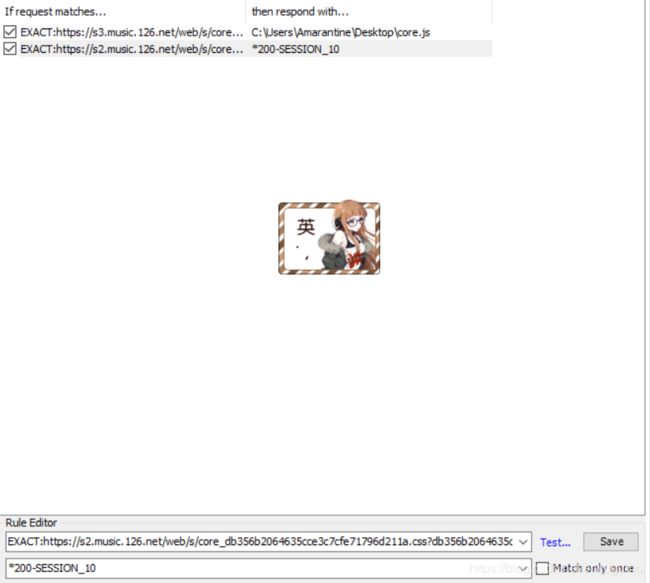
这时我们把默认的*200-SESSION_10改成修改后的core的绝对路径即可。
然后重新刷新网页,就是调用我们自己的core了。效果如下:

在f12的console里,输出了以下几个i4m,我们可以猜测,后两个应该就是歌单和听歌历史的url对应参数了。这样我们就找到了答案。然后将1中的代码改一下就可以:
#first_param = "{rid:\"\", offset:\"0\", total:\"true\", limit:\"20\", csrf_token:\"\"}"#歌曲评论
first_param = "{uid: \"77824233\",type: \"-1\",limit: \"1000\",offset: \"0\",total: \"true\",csrf_token: \"\"}"#听歌记录上面是歌曲评论的参数,下面是我们找到的听歌历史的参数。
然后把url改一下,显示部分的代码也改一下就好了。
如果报错![]()
把fiddler关闭即可。
效果如下:
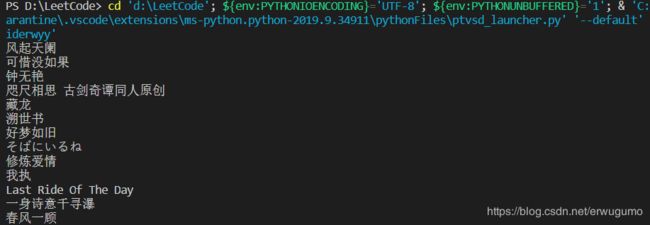
成功获取到听歌记录。
三、总结
本次爬虫结束之后,对爬虫的具体流程有了一个大概的认识:
简而言之,爬虫就是定位资源→模拟请求→获取资源的一个过程。
通过在f12中寻找可以找到资源的位置,所需的url或者直接的元素等,通过将网页元素保存或者是向url发出请求得到所有资源,在所有资源中寻找我们想要的。
没有利用ip池等技术,八成我这个爬一百首歌ip就会被封了。