W系列GAN(小白学GAN系列 四)
PS:学习完WGAN之后,发现其实原WGAN中还存在一些不完善的地方,而也有很多后来人在填坑,本篇选取其中主要的两篇进行研究。阅读本篇之前,请先阅读Wasserstein GAN(小白学GAN系列 三)
原文链接:WGAN-GP(https://arxiv.org/abs/1704.00028)
WGAN-DIV(https://arxiv.org/abs/1712.01026)
简介
WGAN中提出了“W距离”:

这里的Pr(x) 是真实样本的分布,Pg(y)是伪造分布,‖x−y‖是传输成本;而γ∈Π(Pr(x),Pg(y)) 的意思是说:γ 是任意关于下x,y 的二元分布,其边缘分布则为Pr(x) 和Pg(y) 。直观来看,γ 描述了一个运输方案,而‖x−y‖ 则是运输成本,Wc(Pr(x),Pg(y)) 就是说要找到成本最低的那个运输方案所对应的成本作为分布度量。
但是由于联合分布γ难以求解,所以将其转化成对偶问题:

其中f(x)是标量函数,![]() 是Lipschitz范数:
是Lipschitz范数:
![]()
即要满足 ![]()
则WGAN的训练过程可以表达为![]()
核心问题:如何保证![]() 呢?
呢?
解决思路:
- 权重裁剪,即原WGAN中的方法,在优化判别器时每一步梯度下降后,将判别器的参数的绝对值裁剪到不超过某个固定常数。但是这种方式是很粗鲁的,直接限制了判别器优化步长,不仅训练慢且容易陷入局部最优出不来。
- 加惩罚项,通过构造一个合理的惩罚项,来使得在任何时候
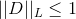 条件都成立。
条件都成立。 - 谱归一化,其本质也是抑制梯度下降更新的幅度,只不过他是在构造LOSS计算时加入,保证算出来的LOSS得到限制。
Improved Training of Wasserstein GANs
核心思路:既然要时刻都满足L约束的话,那么就干脆把L约束构造成惩罚项放到LOSS中。

即便引入了惩罚项L约束是在联合分布上的,即上式中![]() 是难以求解的,所以文中提出了一种取巧的方式来解决这个问题,即将真实样本与随机样本混合后在随机抽样来模拟在联合分布的样本中抽样的过程。其中的
是难以求解的,所以文中提出了一种取巧的方式来解决这个问题,即将真实样本与随机样本混合后在随机抽样来模拟在联合分布的样本中抽样的过程。其中的 =10,是一个经验得出的系数。
=10,是一个经验得出的系数。
Wasserstein Divergence for GANs
核心思路:提出“W散度”来代替“W距离”, 那么相应的限制条件也发生了改变,加到LOSS中的惩罚项就不同。

“W散度”去除了L约束,但却保留了“W距离”可以描述Pr和Pg分布相似性的性质,具体证明可以到原论文中研读。那么直接看使用了“W散度”后,网络的训练流程如下:

简单来看当k=1,p=2它与WGAN-GP就只差一个常数项了,而上式中作者通过实验指出当K=2,P=6时,效果最好。
代码与实践
参考链接(https://github.com/WingsofFAN/PyTorch-GAN)
import argparse
import os
import numpy as np
import math
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd as autograd
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
# Loss weight for gradient penalty
lambda_gp = 10
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def compute_gradient_penalty_div(real_imgs,real_validity,fake_imgs,fake_validity):
real_grad_out = Variable(Tensor(real_imgs.size(0), 1).fill_(1.0), requires_grad=False)
real_grad = autograd.grad(
real_validity, real_imgs, real_grad_out, create_graph=True, retain_graph=True, only_inputs=True
)[0]
real_grad_norm = real_grad.view(real_grad.size(0), -1).pow(2).sum(1) ** (p / 2)
fake_grad_out = Variable(Tensor(fake_imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake_grad = autograd.grad(
fake_validity, fake_imgs, fake_grad_out, create_graph=True, retain_graph=True, only_inputs=True
)[0]
fake_grad_norm = fake_grad.view(fake_grad.size(0), -1).pow(2).sum(1) ** (p / 2)
div_gp = torch.mean(real_grad_norm + fake_grad_norm) * k / 2
return div_gp
def compute_gradient_penalty_gp(D, real_samples, fake_samples):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = Tensor(np.random.random((real_samples.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
d_interpolates = D(interpolates)
fake = Variable(Tensor(real_samples.shape[0], 1).fill_(1.0), requires_grad=False)
# Get gradient w.r.t. interpolates
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# ----------
# Training
# ----------
batches_done = 0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z)
# Real images
real_validity = discriminator(real_imgs)
# Fake images
fake_validity = discriminator(fake_imgs)
#WGAN_GP的LOSS计算
# Gradient penalty
gradient_penalty = compute_gradient_penalty_gp(discriminator, real_imgs.data, fake_imgs.data)
# Adversarial loss
d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
#--------------------------------------------------------------------------------
#WGAN_div的LOSS计算
# Compute W-div gradient penalty
# div_gp = compute_gradient_penalty_div(real_imgs,real_validity,fake_imgs,fake_validity)
# Adversarial loss
# d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + div_gp
#---------------------------------------------------------------------------------
d_loss.backward()
optimizer_D.step()
optimizer_G.zero_grad()
# Train the generator every n_critic steps
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
# Generate a batch of images
fake_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
# Train on fake images
fake_validity = discriminator(fake_imgs)
g_loss = -torch.mean(fake_validity)
g_loss.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
if batches_done % opt.sample_interval == 0:
save_image(fake_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
batches_done += opt.n_critic
minist测试
WGAN WGAN_GP WGAN_div
从上述结果来看,WGAN系列的改进是很成功的,并且从改进的趋势来看从WGAN,到WGAN_GP,再到WGAN_div,其实是在逐渐放宽关于“Wasserstein距离”的限制条件,虽然都基于“Wasserstein距离”所构造出的损失函数,但其实在改进的过程中都是将“Wasserstein距离”改换成了约束相对更弱LOSS来优化判别器。令人陷入深思的是,条件放宽不但没有使得模式搜索困难,反而使得模式建立的更快,从上面测试的MINIST数据来看,三种网络均以同样的学习率和迭代次数来优化,WGAN到最后都未能生成足够好的数据,WGAN_GP迭代到总次数五分之四时生成较为好的数据,WGAN_div迭代到总次数五分之三时生成较为好的数据。
在查阅文献的时候,发现了一篇文章也验证了这个现象,《How Well Do WGANs Estimate the Wasserstein Metric》对许多基于“Wasserstein距离”的GAN网络架构进行了实验和分析也得出了相应的结论:即并不是越接近"Wasserstein距离"的LOSS函数就表现越好。
这个现象的出现其实也并不出乎意料,以下是一些个人的猜想,可能不正确,希望大家指教。我们都知到数据样本分布只是能近似代表数据真实的分布,而我们实际使用GAN网络在学习的是数据样本分布,而其与数据的真实分布还是存在着偏差的。“Wasserstein距离”能够很好地刻画出两个分布之间的距离,可以让生成器学习到数据样本的分布,但是实际上我们期望得到的是数据的真实分布。
可能有点绕,用一个例子来解释:我们希望用GAN生成手写的阿拉伯数字,实际上呢就是我们希望生成网络学会一个映射从高斯分布映射到手写阿拉伯数字的数据分布;但是在现实中我们是无法获得所有手写阿拉伯数字的样本,于是我们使用MINIST数据集来作为替代品;于是,我们在优化判别器时就把“更接近手写阿拉伯数字的数据分布”的目标替代为“更接近MINIST的数据分布”;那么当生成器生成了一个相对接近“手写阿拉伯数字的数据分布”,却相对“MINIST的数据分布”的样本时,严格的“Wasserstein距离”会对它加上“惩罚”让其远离“手写阿拉伯数字的数据分布”而靠近“MINIST的数据分布”,导致最终结果反而表现下降;然而,我们放宽“Wasserstein距离”让生成器学习到的分布靠近“MINIST的数据分布”到一定范围内,而不是以完全趋同为目标,那么当生成器学习到接近“MINIST的数据分布”的分布时,可能这个分布更接近“手写阿拉伯数字的数据分布”,因此效果就更好了。如下图,在条件放宽后,或许无法很好地拟合到“MINIST的数据分布”,但我们可能拟合到“手写阿拉伯数字的数据分布”。
