多任务学习论文导读: Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
基于神经网络的大规模多任务学习在产业界有广泛的应用,例如推荐系统。为什么现在的推荐系统会追求多任务呢?以头条类的新闻推荐为例,如果只追求点击率,那么标题党会大行其道,所以一般还会把阅读时长也作为一个目标。再比如短视频推荐,平台方更希望给用户带来更好的体验,例如长时间播放、点赞、高评分等。因此,我们可能需要针对多个目标进行建模,追求多目标之间的平衡或者共赢。
借助多任务学习,我们的目标是构建一个统一模型来实现同时对多个目标进行建模。每年各种AI领域会议上,都有N多论文都是借助基于深度学习的多任务学习模型实现了线上数据的提升,例如alibaba, youtube等巨头。但是,绝大部分多任务模型并不是在所有任务上都可以战胜单模型结构。 多任务学习,对任务之间的关系很敏感,也就是效果好坏与数据分布关系很大。
根据我在短视频推荐上经验,在短视频社区,适合播放和适合下载/转发的视频往往是两种截然不同的类型。猥琐男们可能喜欢点击性感美女的视频,但是绝对不会转发到朋友圈。当我们试图训练分别以播放和转发为目标的多任务学习模型。这两个目标潜在的冲突会导致模型的效果下降,或者过度拟合其中某个目标。因此,如何在任务共性和特性上做有效的折中是多任务学习特别需要关注的问题。
之前,有一些工作通过引入不同任务之间、数据之间的相关性和差异性度量,来解决多任务学习中存在的问题。但是现实中的数据、任务之间的相关性和差异性很难被度量。 最近的工作大都摒弃了之前的方式,转而通过对相关性和差异性进行建模来改善多任务学习。但是这些方法通常都需要引入大量的参数来学习任务间的差异性,这些参数会加重训练阶段对数据的需求量以及收敛的难度。尤其是线上部署时,性能通常会比较差。
本文提出了一个新颖的多任务学习框架MMoE(Multi-gate Mixture-of-Experts),显式地对任务之间的关系进行建模。在该模型中所有任务共享底层的一组Experts, 并且通过Multi-gate来控制每个Experts起得作用,这种思路在机器学习中很普遍,例如attention机制。 为了验证数据相关性与多任务模型效果之间的关系,作者首先人工生成了一批数据,通过参数控制其相关性,来说明模型(目标)相关性和多任务学习之间的关系。同时,证明MMoE相比其他多任务学习架构在应对任务之间正相关性低的情况下,在效果上的优势。 除此之外,MMoE特殊的结构还带来了训练上优势,这种优势和数据的随机程度,以及模型的初始化有关。文章最后在真实的数据和任务上验证了MMoE结构的优势。
Mixture Of Experts
假如我们想预测一个人的信用水平,可用数据包含以下几组:
1. 生理数据
2. 消费数据
3. 职场数据
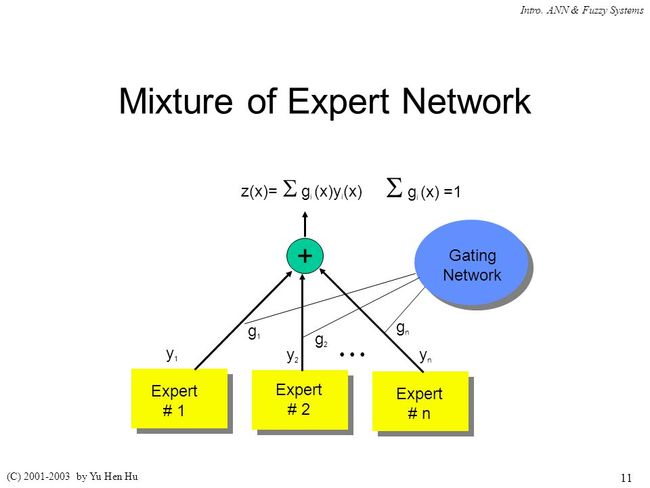
这时候我们可以对数据进行拆分,每一组特征和标记用一个模型来学习,这个模型就称为某个领域的Experts。然后我们把每个Experts的预测的结果Mixtures在一起做最终的预测。原始的MoE预测的表达式如下所示

其中![]() 是gate网络
是gate网络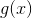 输出向量的一个维度。
输出向量的一个维度。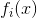 是第
是第 个expert网络。
个expert网络。
后来MoE逐渐演变成神经网络的一个组件,可以搭建多层的MoE,即:下一层的MoE的输出作为上一层MoE的输入。每个输入 ,每个expert共享的强度都不同,可以理解只能激活神经网络中的部分。
,每个expert共享的强度都不同,可以理解只能激活神经网络中的部分。
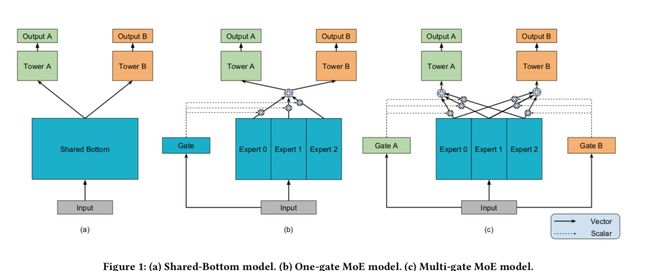
Shared-Bottom Model
基于神经网络的多任务学习两种最常见的套路:一种是shared-bottom,底层公用若干层神经网络,然后上面每个任务自己特有的tower。另外一种是每个任务单独一个模型,但是添加了约束来约束不同模型的参数,例如L2约束。这一类方法需要学习的参数很多,训练模型需要的数据量也很大,更重要的是不适合线上问题。
shared-bottm模型是神经网络多任务模型中出现较早,应用广泛的一种模型。如上图最左侧,不同的任务共享输入层、shared-bottom层,每个任务有自己的task-specific tower层,每个Tower层可以是一个独立的神经网络。在一些CV领域的多任务学习中,share-bottom层可能就是某种卷积模型。
Multi-Gating Mixture Of Experts
最右侧就是本文提出的MMoE模型,不同任务共享底层的一组Bottom层,称为一组Expert,每个Experts可能善于捕捉部分数据和目标之间的关系。并且,每个任务会关联一个gating网络,这个gating网络输入和Experts层一样,输出层是一个softmax,每个权重和一个experts绑定。相当于每个任务对Experts层输出的结果倚重程度不同。上面是task-specific层,每个tower也是一个神经网络,输出具体某个任务的输出。
所以,gating网络针对不同的任务,输出一种独特的Experts混合方式,通过这个操作来学习不通过任务之间的关系。为了理解MMoE如何通过训练、Gate网络来对任务相关性建模,作者设计了一组基于模拟数据的实验,任务相关性用皮尔斯相关系数来衡量。最终实验得出两个结论:
* 任务相关性越低,MMoE相比传统方法的优势越大
* MMoE训练会收敛到一个更小的Loss,这和最近的发现相吻合:调制和门机制更有利于模型的训练。
本文把shared-bottom多任务框架中的shared-bottom替换成MoE层,并且为每个任务添加了一个gating网络,来控制该目标对每个Experts的倚重。第 个任务的输出:
个任务的输出:
![]()
其中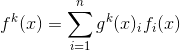 。每个task对应一个gate, 也就是说对应一个
。每个task对应一个gate, 也就是说对应一个![]() ,每个
,每个![]() 一个softmax层,输出是一个
一个softmax层,输出是一个 维向量,就是expert的数量。每个task对应的gate网络实现的作用也是对expert的选择。
维向量,就是expert的数量。每个task对应的gate网络实现的作用也是对expert的选择。
相比于shared-bottom结构,MoE网络中,每个Expert网络规模很小,MoE网络的参数量和shared-botton结构的参数量相当。而且多个task共享MoE层,所以任务增加并不会增加MoE层的参数,只是上层的task-specific层增加了一个tower。
作者通过实验证实,MOE结果可以让模型的结果更鲁棒,即:对参数初始化和超参的选择依赖程度更低,结果更稳定。
最后在现实的推荐场景对比了MMoE和Shared-bottom结构的效果,无论离线AUC还是在线效果都可以吊打。 所以总结一下,这篇文章的三个主要贡献:
1. 提出了MMoE结构,可以显式的对任务相关性进行建模,通过调制和门网络自动的调节共享和特有信息的参数权重。
2. 利用模拟数据进行了一组实验,来说明任务相关性对多任务精度和训练速度的影响,并且证明MMoE在任务相关性低的情况下的优势,以及训练的优势
3. 最后在公开数据集和线上环境测试了MMoE,证明其效果。