Python爬虫框架:scrapy 爬取纵横网实战
前言
闲来无事就要练练代码,不知道最近爬取什么网站好,就拿纵横网爬取我最喜欢的雪中悍刀行练手吧
准备
- python3
- scrapy
项目创建:
cmd命令行切换到工作目录创建scrapy项目 两条命令 scarpy startproject与scrapy genspider 然后用pycharm打开项目
D:\pythonwork>scrapy startproject zongheng
New Scrapy project 'zongheng', using template directory 'c:\users\11573\appdata\local\programs\python\python36\lib\site-packages\scrapy\templates\project', created in:
D:\pythonwork\zongheng
You can start your first spider with:
cd zongheng
scrapy genspider example example.com
D:\pythonwork>cd zongheng
D:\pythonwork\zongheng>cd zongheng
D:\pythonwork\zongheng\zongheng>scrapy genspider xuezhong http://book.zongheng.com/chapter/189169/3431546.html
Created spider 'xuezhong' using template 'basic' in module:
zongheng.spiders.xuezhong
确定内容
首先打开网页看下我们需要爬取的内容
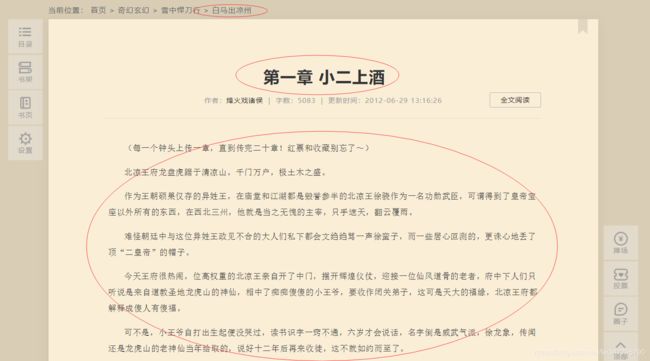
其实小说的话结构比较简单 只有三大块 卷 章节 内容
因此 items.py代码:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZonghengItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
book = scrapy.Field()
section = scrapy.Field()
content = scrapy.Field()
pass
内容提取spider文件编写
还是我们先创建一个main.py文件方便我们测试代码
from scrapy import cmdline
cmdline.execute('scrapy crawl xuezhong'.split())
然后我们可以在spider文件中先编写
# -*- coding: utf-8 -*-
import scrapy
class XuezhongSpider(scrapy.Spider):
name = 'xuezhong'
allowed_domains = ['http://book.zongheng.com/chapter/189169/3431546.html']
start_urls = ['http://book.zongheng.com/chapter/189169/3431546.html/']
def parse(self, response):
print(response.text)
pass
运行main.py看看有没有输出
发现直接整个网页的内容都可以爬取下来,说明该网页基本没有反爬机制,甚至不用我们去修改user-agent那么就直接开始吧
打开网页 F12查看元素位置 并编写xpath路径 然后编写spider文件
需要注意的是我们要对小说内容进行一定量的数据清洗,因为包含某些html标签我们需要去除
# -*- coding: utf-8 -*-
import scrapy
import re
from zongheng.items import ZonghengItem
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class XuezhongSpider(scrapy.Spider):
name = 'xuezhong'
allowed_domains = ['book.zongheng.com']
start_urls = ['http://book.zongheng.com/chapter/189169/3431546.html/']
def parse(self, response):
xuezhong_item = ZonghengItem()
xuezhong_item['book'] = response.xpath('//*[@id="reader_warp"]/div[2]/text()[4]').get()[3:]
xuezhong_item['section'] = response.xpath('//*[@id="readerFt"]/div/div[2]/div[2]/text()').get()
content = response.xpath('//*[@id="readerFt"]/div/div[5]').get()
#content内容需要处理因为会显示标签和标签
content = re.sub(r'', "", content)
content = re.sub(r'||
',"\n",content )
xuezhong_item['content'] = content
yield xuezhong_item
nextlink = response.xpath('//*[@id="readerFt"]/div/div[7]/a[3]/@href').get()
print(nextlink)
if nextlink:
yield scrapy.Request(nextlink,callback=self.parse)
有时候我们会发现无法进入下个链接,那可能是被allowed_domains过滤掉了 我们修改下就可以
唉 突然发现了到第一卷的一百多章后就要VIP了 那我们就先只弄一百多章吧 不过也可以去其他网站爬取免费的 这次我们就先爬取一百多章吧
内容保存
接下来就是内容的保存了,这次就直接保存为本地txt文件就行了
首先去settings.py文件里开启 ITEM_PIPELINES
然后编写pipelines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class ZonghengPipeline(object):
def process_item(self, item, spider):
filename = item['book']+item['section']+'.txt'
with open("../xuezhongtxt/"+filename,'w') as txtf:
txtf.write(item['content'])
return item
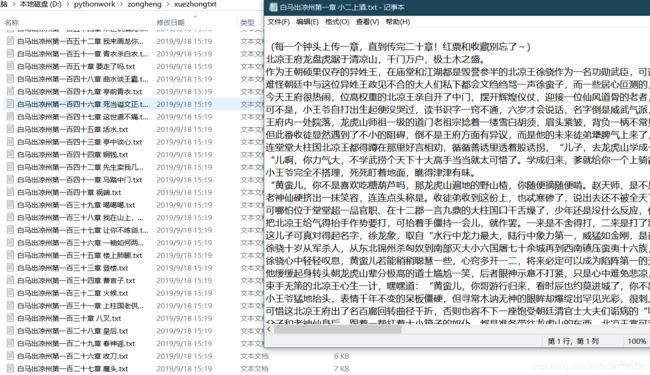
由于选址失误导致了我们只能爬取免费的一百多章节,尴尬,不过我们可以类比运用到其他网站爬取全文免费的书籍
怎么样 使用scrapy爬取是不是很方便呢