6个开源数据科学项目
作者|PRANAV DAR 编译|VK 来源|Analytics Vidhya
概述
利用这段时间,用这些顶级的开源项目来制作你的数据科学简历
从Facebook AI的计算机视觉框架到OpenAI的GPT-3模型,我们涵盖了广泛的开源数据科学项目
介绍
“到目前为止,你完成了多少数据科学项目?”
这是面试者在数据科学面试中经常问的问题。我曾进行了几次这样的面试。这个问题基本上开门见山就会询问。如果你是一个数据科学的新手,尤其需要注意
仅仅学习课程或获得证书是不够的。我认识的几乎每个人都持有数据科学各个方面的证书。如果你不把它和实际经验结合起来,它就不会给你的简历增加任何价值。
而这正是开源数据科学项目发挥如此关键作用的地方。面试者喜欢那些接手这些项目并提出解决方案的申请人。这显示了你对这个领域的好奇心、热情和热情。相信我,在简历中加入数据科学项目会增加你被录用的机会。

但你应该选择哪些数据科学项目呢?我收集了前几个月最好的项目并把它们带给你。在本月的版本中,我们将涵盖广泛的主题,从Facebook人工智能的game-changing DEtection TRansformer(DETR)框架到OpenAI的GPT-3。

Facebook AI的DEtection TRansformer (DETR)
链接:https://github.com/facebookresearch/detr
Facebook人工智能的DETR很容易成为5月份发布的最有趣的开源项目。它在一周内积累了近3000颗star,这一事实很能说明问题。
DETR(DEtection TRansformer的缩写)是计算机视觉空间中的一个变化转换器。该框架是解决目标检测问题的一种创新和有效的方法。DETR速度极快,效率极高。

正如我们的常驻数据科学家Prateek Joshi所说:
“DETR模型非常简单,不需要安装任何库就可以使用它。借助于基于transformers的编码器-解码器体系结构,DETR将目标检测问题视为直接集合预测问题。”
我们在这里详细介绍了DETR,以帮助你了解它在下面是如何工作的,以及如何将它用于对象检测任务。你还可以查看Facebook人工智能团队发布的Colab Notebook,查看DETR模型的实际应用。
https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_demo.ipynb
Real-Time Image Animation
实时图像动画:https://github.com/anandpawara/Real_Time_Image_Animation
另一个有趣的开源计算机视觉项目。顾名思义,是让我们使用OpenCV实时执行图像动画。看看我从项目的GitHub存储库中获取的这个示例:

模型模拟了人在镜头前的表情,并相应地改变了图像。这是计算机视觉的一个杰出应用,我们肯定会在内部尝试这个项目。这类项目将在业界有大量的应用,从时装和零售到营销和广告。
最初的开发人员已经很友好地发布了源代码以及Colab Notebook。去尝试下吧
https://colab.research.google.com/github/AliaksandrSiarohin/first-order-model/blob/master/demo.ipynb
OpenAI的GPT-3
链接:https://github.com/openai/gpt-3
OpenAI又实现了一个!在去年发布了GPT-2并掀起了一股热潮之后,他们已经开放了他们最新的自然语言处理(NLP)框架GPT-3!
简单地说,GPT-3是同类中最大的NLP模型。它有1750亿个参数(没错,你读得没错),而且体积庞大,几乎有350GB。GPT-3几乎是历史上最昂贵的模型之一(训练费用约为1200万美元)。

语言模型需要大量的数据来训练人类在几秒钟内就能完成的任务,这已经不是什么秘密了。升级–GPT-3。在讨论GPT-3如何在引擎盖下工作的官方论文中,OpenAI展示了扩展语言模型如何极大地提高任务无关性和少量镜头的性能。
现在这一部分可能会涉及到很多数据科学伦理人士——GPT-3可以很容易地生成新闻文章的样本,而人类很难将其识别为假新闻。在当今相互关联的世界,这可能是灾难性的。为了公平起见,他们在论文中讨论了这个问题。
基于PyAudio的实时音频分析
链接:https://github.com/tr1pzz/Realtime_PyAudio_FFT
这个开源的数据科学项目是个人的最爱。这个Python库由Xander Steenbrugge创建并发布,他是前两次DataHack峰会上备受尊敬的演讲者,它使我们能够执行实时音频分析。
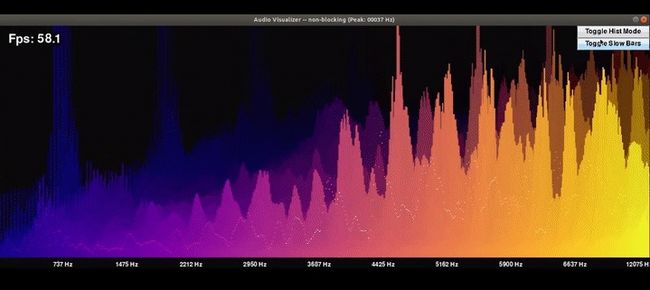
正如Xander在他的GitHub存储库中所说:
这是一个简单的包,用于在本机Python中进行实时音频分析,它使用PyAudio和Numpy从实时音频流中提取和可视化FFT特征
这里的FFT代表快速傅立叶变换。它是一个出色的工具,在你的数据科学技能集,因为它解答了广泛的问题,你可以使用它。
TextShot,获取文本的Python工具
链接:https://github.com/ianzhao05/textshot
你有没有遇到过图片或截图有文字,但不能完全提取文字?我知道有一些工具是为这个目的而存在的,但我不想在我的机器上安装任何额外的软件。
现在,我们可以简单地使用这个Python工具抓取屏幕截图并从中提取文本,称为TextShot(好名字),这是一个很好的工具,可以快速收集我们的数据科学项目所需的任何文本数据。以下是一个演示TextShot的工作原理:
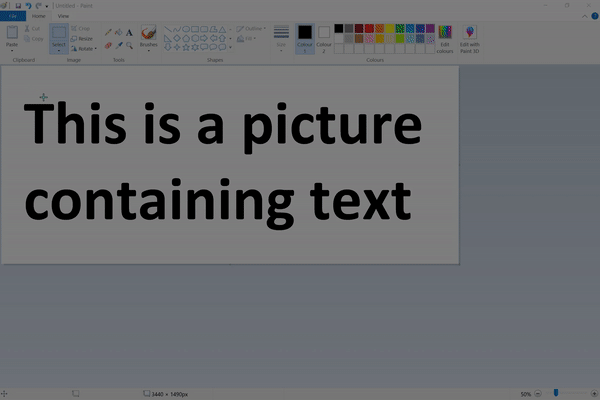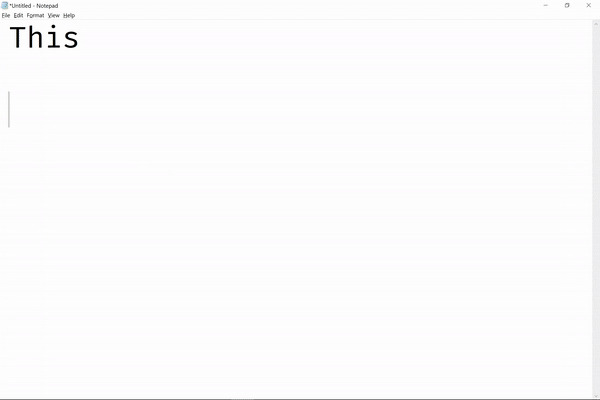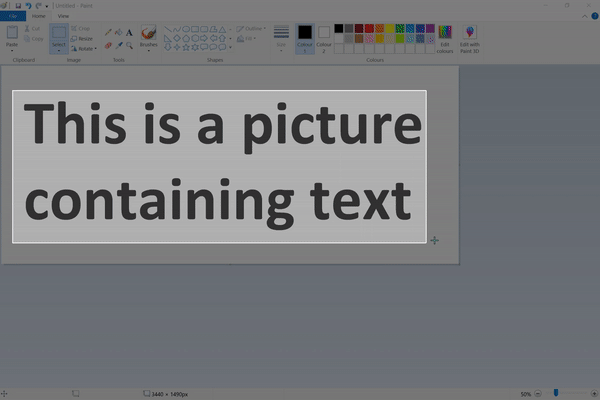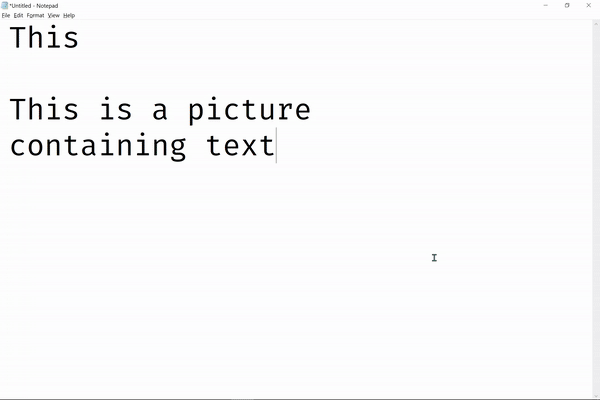
TextShot要求你在计算机上安装谷歌的Tesseract。
Machine Learning Visuals-数据科学专业人士交流的绝佳方式
链接:https://github.com/dair-ai/ml-visuals
我喜欢这个开源存储库,许多新来的人(甚至是有经验的人)经常在技术和科学交流上有矛盾。
ML Visuals是一个开源的协作项目,旨在帮助数据科学界理解和改进技术交流。这个出色的存储库提供了大量的视觉、模板和图形,帮助你构建一个完美的演示文稿或研究论文。
这个项目最棒的部分是你可以在谷歌的幻灯片上找到所有东西。看看我从这些幻灯片中拍摄的几张图片:

很棒!
结尾
在这个月我收集了很多有趣的开源数据科学项目!例如Facebook人工智能的DETR上和OpenAI的GPT-3。
原文链接:https://www.analyticsvidhya.com/blog/2020/06/6-open-source-data-science-projects-interviewer/
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/