ResNet最强改进版来了!ResNeSt:Split-Attention Networks

《ResNeSt: Split-Attention Networks》
作者团队:亚马逊(张航和李沐等)&UC Davis
代码(提供PyTorch和MXNet双版本):
https://github.com/zhanghang1989/ResNeSt
论文:https://hangzhang.org/files/resnest.pdf
前言
开头先致敬一下 ResNet!Amusi 于2020年4月17日在谷歌学术上查看ResNet的引用量,发现已高达 43413!请注意,这还只是ResNet发表短短4年多的引用量。
这里吐槽一句,现在出现很多基于NAS的新网络(趋势),暴力出奇迹,比如MobileNetV3、EfficientNet等,但论应用场景,还是ResNet给力。实际上,很多下游工作(目标检测、图像分割等)仍然在使用ResNet或其变体,主要是因为结构简洁通用。

本文要介绍的是ResNet 的新变体:ResNeSt。继续将ResNet"发扬光大",值得点赞。
Amusi 将标题注明了最强,很多人肯定会质疑是不是标题党?究竟有多强?往下看,你就知道了!
先说几组数据:
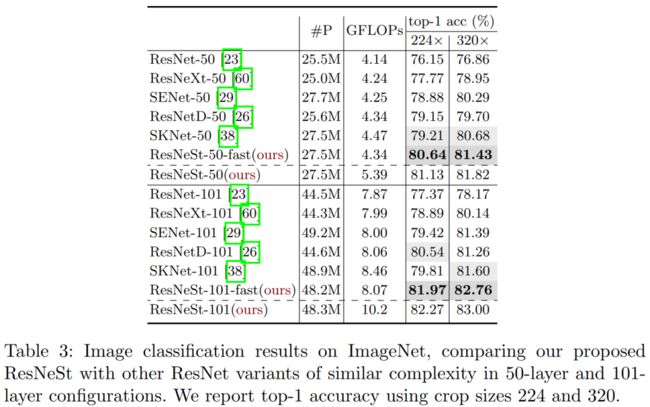
ResNeSt-50 在 ImageNet 上实现了81.13% top-1 准确率
简单地用ResNeSt-50替换ResNet-50,可以将MS-COCO上的Faster R-CNN的mAP从39.25%提高到42.33%!
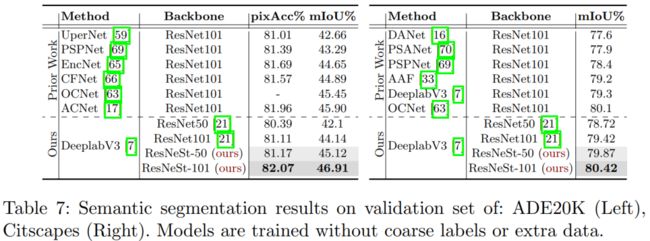
简单地用ResNeSt-50替换ResNet-50,可以将ADE20K上的DeeplabV3的mIoU从42.1%提高到45.1%!
性能显著提升,参数量并没有显著增加,部分实验结果如下图所示。轻松超越ResNeXt、SENet等前辈(巨人)们。

ResNeSt
ResNeSt 的全称是:Split-Attention Networks,也就是特别引入了Split-Attention模块。如果没有猜错,ResNeSt 的 S 应该就是 Split。
这里要说一下,ResNeSt 实际上是站在巨人们上的"集大成者",特别借鉴了:Multi-path 和 Feature-map Attention思想。
其中:
GoogleNet 采用了Multi-path机制,其中每个网络块均由不同的卷积kernels组成。
ResNeXt在ResNet bottle模块中采用组卷积,将multi-path结构转换为统一操作。
SE-Net 通过自适应地重新校准通道特征响应来引入通道注意力(channel-attention)机制。
SK-Net 通过两个网络分支引入特征图注意力(feature-map attention)。
ResNeSt 和 SE-Net、SK-Net 的对应图示如下:
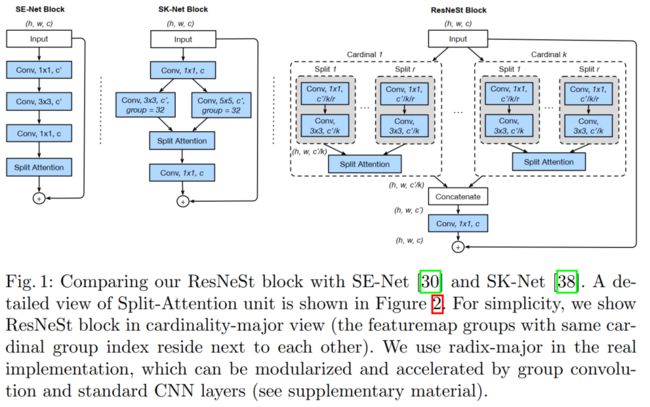
其中上图中都包含的 Split Attention模块如下图所示:
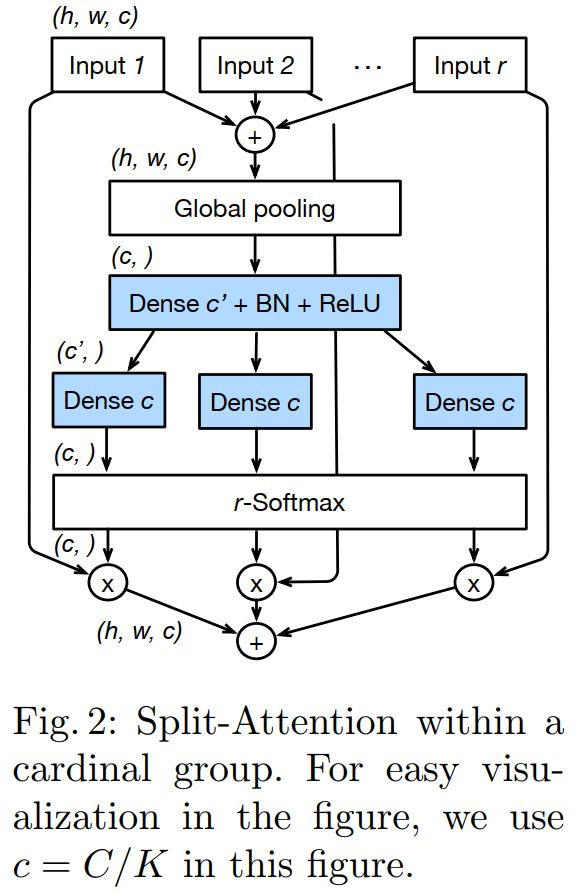
从图1和图2可知,都有split的影子。比如图1中的 K(k) 和图2中的 R(r) 都是超参数,也就是共计 G = K*R 组。
限于篇幅问题,本文旨在论文速递。完整理解Split Attention模块需要涉及部分公式,这里建议大家结合原文和代码进行理解。目前代码已经提供PyTorch和MXNet两个版本。
https://github.com/zhanghang1989/ResNeSt
同时论文还介绍了训练策略,这个对大家目前的工作应该具有很大的参考价值(涨点tricks)。
Large Mini-batch Distributed Training
Label Smoothing
Auto Augmentation
Mixup Training
Large Crop Size
Regularization
实验结果
ResNeSt 在ImageNet 图像分类性能如下,轻松超越SKNet、SENet、ResNetXt和ResNet。
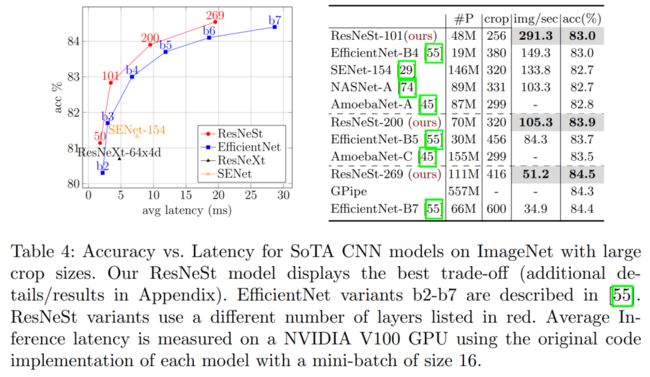
ResNeSt 和其他SoTA的CNN模型进行性能比较(特别是NAS阵营)
ResNeSt 在MS-COCO 目标检测和实例分割任务上的表现性能如下,涨点太恐怖!


ResNeSt 在ADE20K 语义分割任务上的表现性能如下:

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)本站qq群1003271085,加入微信群请回复“加群”获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/yFQV7am喜欢文章,点个在看