JAVA字符串创建及拼接分析
目录
- 一、class文件常量池
- 二、运行时常量池
- 三、字符串常量池
- 四、字符串创建案例分析
- 五、字符串+号拼接案例分析
- 六、字符串拼接比较
JAVA主要有三种常量池:class文件常量池、运行时常量池、字符串常量池。
一、class文件常量池
一个.java文件在编译阶段会被编译成.class文件,.class文件中除了有魔数、副版本号、主版本号等信息外,还有一个class文件常量池,常量池里主要包含两种数据:字面量和符号引用。
字面量:
1.文本字符串
2.八中基本类型的值
3.inal类型常量值
符号引用:
1.类和接口的全限定名
2.字段的名称和描述符
3.方法的名称和描述符
二、运行时常量池
运行时常量池存在于JVM方法区中,在类加载完成,经过验证,准备阶段之后,JVM会把class文件常量池中除了字符串以外的其他数据放入运行时常量池中,符号引用会替换为直接引用。
什么是符号引用和直接引用?
在编译的时候,JAVA类并不知道引用类的实际内存地址,只能用一些符号来代替。比如要引用org.simple.Tools类,编译的时候是不知道Tools的实际地址的,只能用个字面符号来代替,等到类装载的时候,再把这个符号换成实际的地址,也就是直接引用地址。
三、字符串常量池
刚刚说,类加载完成后,其他进入运行时常量池,字符串则进入字符串常量池。
字符串常量池在堆中,它是一个哈希表,key是字符串表面字符,value是字符串在堆中的地址。也就是说,对于一个字符串常量,它的实例是在堆中的,字符串常量池保存的只是这个实例的地址。
JDK1.7之前,所有常量都在运行时常量池中(包括字符串),也就是在方法区中,此时hotspot虚拟机对方法区的实现为永久代。
JDK1.7开始,字符串常量被单独从方法区拿到了堆中, 建立了字符串常量池,剩下其他常量还留在运行时常量池, 也就是hotspot中的永久代。
JDK1.8开始,hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间。
JDK1.7之前,实例和引用都保存在运行时常量池中;1.7之后由于把字符串常量提到了堆中,就在堆中创建实例,而字符串常量池只保存引用地址。
四、字符串创建案例分析
下面让我们来分析一个经典的面试问题:
String s=new String(“abc”)究竟创建了几个String对象?
在回答这个问题之前,我们要先分析字符串创建的过程。
——————————————————————————————————————
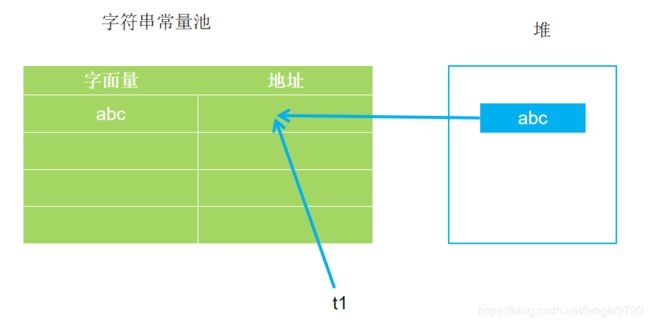
例子1:
String t1="abc";
这句话的具体执行流程是:
1.因为有字面量"abc",所以在编译时"abc"会进入class文件常量池中;
2.执行类加载后,"abc"会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;
3.当具体执行到这句语句时,因为是直接常量赋值,所以就去字符串常量池中查找"abc"的地址并返回。
结果:只创建了1个String对象,常量池中只有1项
——————————————————————————————————————
例子2:
String t1=new String("abc");
这句话的具体执行流程是:
1.因为有字面量"abc",所以在编译时"abc"会进入class文件常量池中;
2.执行类加载后,"abc"会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;
3.当具体执行到这句语句时,因为是动态new创建,所以会在堆中新产生一个实例对象,然后直接返回这个对象的地址。
结果:创建了2个String对象,常量池中只有1项

这句代码是犯错最多的地方,总是看到有人说:
new创建时会先看常量池有没有对应的字符,如果有就拷贝一份到堆中,然后返回堆地址;如果没有就先在堆中创建一个实例,然后拷贝一份放到常量池中。
这句话错的原因在于:字面常量在类加载后就进入字符串常量池了,堆中已经有了实例了,而动态创建的实例在具体执行到该语句时才会创建,这是两个分开的过程,我们总是混为一谈。
只需要记住两个原则就行:
1.动态创建的实例和常量池没有任何关系
2.字符串要想进入常量池只有两个方法,一个自动一个手动。自动的方法就是用双引号“”引起来,手动的方法就是调用intern()方法
——————————————————————————————————————
例子3:
String t1=new String("abc");
String t2="abc";
System.out.println(t1==t2);
//>false
这段代码的具体执行流程是:
1.因为有字面量"abc",两个都一样所以就只有一个,在编译时"abc"会进入class文件常量池中;
2.执行类加载后,"abc"会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;
3.具体执行到t1语句时,因为new动态创建所以在堆中创建一个新实例,然后直接返回地址,跟常量池不发生任何交互;
4.具体执行到t2语句时,因为常量赋值,所以去常量池中找对应的字符,返回对应地址。
结果:创建了2个String对象,常量池中只有1项

这下你终于明白为什么t1和t2不等了吧!
——————————————————————————————————————
例子4:
String t1=new String("abc");
String t2="abc";
System.out.println(t1==t2);
//>false
t1.intern();
System.out.println(t1==t2);
//>false
t1=t1.intern();
System.out.println(t1==t2);
//>true
这个例子主要是想说明intern()方法的使用。
intern()方法的执行步骤是:在字符串常量池中查找对应字符是否存在,如果存在就直接返回常量池中存储的地址;如果不存在就将它的引用保存到常量池中,并返回这个引用。
所以intern()的方法的返回值才是字符串在常量池中的地址,而只执行不返回是没有用的,t1该是多少还是多少,要重新接收返回值才行。
结果:创建了2个String对象,常量池中只有1项

——————————————————————————————————————
例子5:
String t1="abc";
String t2=new String("abc");
String t3=new String(t1);
System.out.println(t1==t2);
//>false
System.out.println(t1==t3);
//>false
System.out.println(t2==t3);
//>false
这段代码的具体执行流程是:
1.因为有字面量"abc",两个都一样所以就只有一个,在编译时"abc"会进入class文件常量池中;
2.执行类加载后,"abc"会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;
3.具体执行到t1语句时,因为常量赋值,所以去常量池中找对应的字符,返回对应地址;
4.具体执行到t2语句时,因为new动态创建所以在堆中创建一个新实例,然后直接返回地址,跟常量池不发生任何交互;
5.具体执行到t3语句时,因为new动态创建所以在堆中创建一个新实例,然后直接返回地址,跟常量池不发生任何交互。
结果:创建了3个String对象,常量池中只有1项

——————————————————————————————————————
例子6:
String t1=new String("abc");
String t2=new String("def");
这段代码的具体执行流程是:
1.因为有字面量"abc"和“def”,在编译时"abc"和"def"会进入class文件常量池中;
2.执行类加载后,"abc"会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;"def"也会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;
3.具体执行到t1语句时,因为new动态创建所以在堆中创建一个新实例,然后直接返回地址;
4.具体执行到t2语句时,因为new动态创建所以在堆中创建一个新实例,然后直接返回地址。
结果:创建了4个String对象,常量池中有2项

——————————————————————————————————————
五、字符串+号拼接案例分析
下面让我们来分析一个经典的面试问题:
String s=new String(“abc”)+new String(“def”)究竟创建了几个对象?
在回答这个问题之前,我们还是要先分析字符串创建的过程。
你应该知道,JAVA的String是一个隐式final修饰的不可变变量,如果有改变就会创建一个新的String对象,所以在涉及到字符串+号的时候,系统会自动创建一个StringBuilder对象,然后每执行一次+号,就会append一次,也就是说上面的代码其实具体执行的时候是:
String s=new StringBuilder().append(new String("abc")).append(new String("def")).toString();
——————————————————————————————————————
例子1:
String t1="abc";
String t2="a"+"bc";
System.out.println(t1==t2);
//>true
你可以猜一下,字符串常量池里有几个字符串?三个?
答案是只有一个,就是"abc"。
对于字面常量的+号拼接,编译器在编译的过程中会进行优化,只保留最终结果,也就是说哪怕你中间有几万个字面常量字符串,只要你是以+号拼接的,最终都只有一个最终结果。所以在编译的过程中这两个就是同一个字面量"abc",只会往常量池中存一个。
所以对于字面量的+号拼接,在编译阶段其实就已经完成了,所以在具体执行阶段不会产生StringBuilder对象,更不会执行append方法了。
所以这个过程只在堆中创建了一个String实例,这个实例的地址存到了字符串常量池中,t1指向这个地址,t2也指向这个地址。
结果:创建了1个String对象,0个StringBuilder对象,常量池中有1项

——————————————————————————————————————
例子2:
String t1="abc";
final String t2="a";
String t3=t2+"bc";
System.out.println(t1==t3);
//>true
final常量在编译的时候会被识别为与字面常量同一类型,也就是t3在编译的时候就会变成这句:
String t3="a"+"bc";
所以最终在常量池里你会看到“a”和"abc",但你找不到"bc",因为常量+号拼接只保留最终结果。
所以最终因为字面量“abc”和“a”会在堆中创建两个实例,然后地址加到常量池中,t1、t2、t3通通都是常量赋值,直接返回常量池的地址即可。
结果:创建了2个String对象,0个StringBuilder对象,常量池中有2项

——————————————————————————————————————
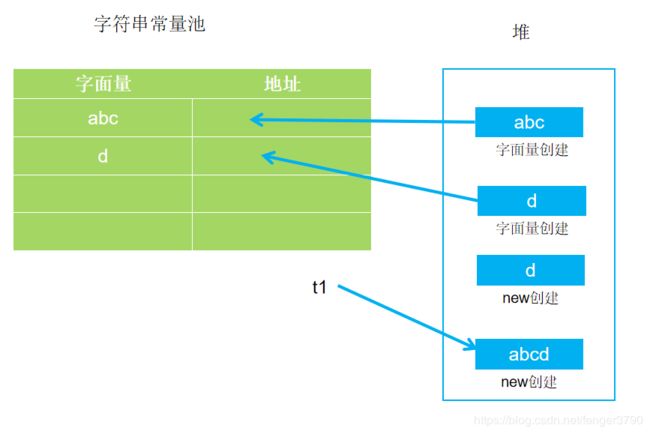
例子3:
String t1="abc"+new String("d");
因为+左右的不是字面常量,所以不会在编译阶段自动拼接了。所以这条语句的具体执行步骤如下:
1.因为有字面量"abc"和“d”,在编译时"abc"和"d"会进入class文件常量池中;
2.执行类加载后,“abc"会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;“d"也会在堆中创建一个实例对象,然后把这个实例对象的地址放到字符串常量池中;
3.具体执行到t1语句时,先创建一个StringBuilder对象初始化;
4.遇到字面常量"abc”,则去常量池查找对应地址,提出字符内容,然后调用append方法将"abc"拷贝到StringBuilder的底层数组中(StringBuilder底层是用char[]依次保存所有字符);
5.遇到new动态创建代码,在堆中创建一个实例对象,然后返回地址;
6.利用返回的地址提出具体字符内容"d”,然后调用append方法将"d"拷贝到StringBuilder底层数组中;
7.调用StringBuilder的toString()方法,在堆中创建一个实例对象,然后返回地址给t1。
所以这个例子等同于:
String t1=new StringBuilder().append("abc").append(new String("d")).toString();
其中StringBuilder的toString()源代码如下,,可以看到是动态创建了一个String对象。
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
好,这里有个问题:字符串常量池里有"abcd"吗?
答案是没有!
原因就是我之前说过的,动态创建字符串不会和常量池产生任何关系。
在这里,StringBuilder调用new String来创建一个实例"abcd",然后就直接返回堆地址了,不会和常量池产生关系。这里就证实了“动态创建之后会去常量池找对应的字符,没有就把引用放到常量池中”这句话是不对的!
结果:创建了4个String对象,1个StringBuilder对象(图里没画),常量池中有2项
——————————————————————————————————————
例子4:
String t1="abc"+new String("d");
String t2="abcd";
System.out.println(t1==t2);
//>false
这是例3的扩展,因为有字面量"abc"、“d”、“abcd”,所以常量池中会有3项,而t2就指向常量池中的地址,而t1是StringBuilder的toString()方法新创建出来的,所以不等。
结果:创建了5个String对象,1个StringBuilder对象(图里没画),常量池中有3项

——————————————————————————————————————
例子5:
String s=new String(“abc”)+new String(“def”)究竟创建了几个对象?
看到这终于可以回答这个问题,一共几个对象?
结果:创建了5个String对象,1个StringBuilder对象,常量池中有2项
其中字面常量"abc"和"def"创建了2个String对象,new动态创建了2个String对象,StringBuilder最后调用toString()方法还动态创建了1个,所以一共是5个String对象。
六、字符串拼接比较
字符串的拼接主要有以下几种方式:
1.+号
2.concat()方法
3.join()方法
4.StringBuilder的append()方法
5.StringBuffer的append()方法
——————————————————————————————————————
情况1:
final String t="rstuvw";
String t1="a"+"bcd"+"efghijkl"+"mno"+"p"+t;
上面说到了,如果只涉及到字面量和final常量的拼接,用+号是最快的,编译器会在编译阶段就直接优化出最终结果,比其他任何方式都快。
+号拼接有一个明显的优势就是:+几乎可以拼接一切字符,+可以拼字符串、单个字符、常量、变量、整数、浮点数、数组、对象(只不过这两是地址)等等。
——————————————————————————————————————
情况2:
String t2="abc";
String t3=t2+"def";
如果不是纯字面常量的拼接,中间涉及到了非final变量的话,如果用+号就会在底层创建一个StringBuilder对象,然后不断调用append()方法,也就是说上面的代码和下面的是一样的:
String t2="abc";
StringBuilder s=new StringBuilder();
s.append(t2);
s.append("def");
String t3=s.toString();
StringBuilder的append()方法和+一样可以填入各种类型。
这里需要注意的是:在一行+号内只创建一个StringBuilder,如果使用多行就会创建多个StringBuilder,比如下面的例子。
——————————————————————————————————————
情况3:
String t1="abc"+new String("def");
t1+="ghi"+new String("jkl");
t1+="mno";
比如在这种情况下每一行就会产生一个StringBuilder,同时每一行都会执行一次toString(),也就是说每一行都会额外新建一个String对象,这是非常冗杂的。
正确的做法应该如下:
StringBuilder s=new StringBuilder();
s.append("abc");
s.append(new String("def"));
s.append("ghi");
s.append(new String("jkl");
s.append("mno");
String t1=s.toString();
——————————————————————————————————————
情况4:
有一种情况是你需要把一个数组里的元素拼成字符串,比如[“abc”,“def”,“ghi”]拼成字符串,能想到的做法有以下几种:
String[] arr=new String[]{"abc","def","ghi"};
String t1="";
for(int i=0;i<arr.length;i++){
t1+=arr[i];
}
这种方法上面说了,每循环一次就会创建一个StringBuilder,同时每次还会新建一个String对象,太冗杂。
String[] arr=new String[]{"abc","def","ghi"};
StringBuilder s=new StringBuilder();
for(int i=0;i<arr.length;i++){
s.append(arr[i]);
}
String t1=s.toString();
这种方法是可行的,并且不会创建额外的变量。
String[] arr=new String[]{"abc","def","ghi"};
String t1=String.join("-",arr);
//t1="abc-def-ghi"
String自带的join函数适用于按需求拼接数组,看源码会发现join()方法底层用的是StringJoiner,而StringJoiner底层用的还是StringBuilder,所以这种方法虽然简单,还其实没有上面那种高效,会创建额外的StringJoiner对象。
还有一个缺点就是join函数只能拼String[],int[]就拼不了了,必须先转成String[]。
最常见的用法还是下面这个:
String[] arr=new String[]{"abc","def","ghi"};
String t1= Arrays.toString(arr);
Arrays工具包提供的toString()方法可以直接转换一切类型的数组,而且它的底层是直接用StringBuilder执行的,所以会比较快,当然缺点就是不能在中间插入一些自己想加的字符。
——————————————————————————————————————
情况5:
String s=new String("abc").concat("def").concat("ghi");
concat()方法底层其实是利用数组拷贝来拼接的,然后new出一个String对象,也就是说如果调用一次concat函数就会申请一段内存数组来存放拼接后的所有字符,然后再把这些字符new出一个String返回,等于你调用了几次就多了几个String。
虽然底层直接数组拷贝比较快,但由于多了String中间量,所以比较冗余。
还有一个缺点就是concat只能拼字符串,单个字符、整数、浮点数、数组等等都不能做为concat的参数。
——————————————————————————————————————
情况6:
StringBuffer s=new StringBuffer();
s.append("abc");
s.append(new String("def"));
String t1=s.toString();
StringBuffer基本用法跟StringBuilder差不多,差别就在于StringBuffer是线程安全的,它的所有方法都用synchronized修饰,保证了多线程原子性,但同时性能相对StringBuilder也会下降很多,而同时StringBuilder速度快但是线程不安全。
——————————————————————————————————————
总结一下就是:
1.如果是单纯字面量和final常量拼接,用+号最好;
2.如果要加的元素能在一行内写完的话,用+号和用StringBuilder是一样的,不过+号代码写起来简单;
3.如果要加的元素要累加多行的话,用StringBuilder逐一append()是最好的;
4.如果要把一个数组所有元素直接拼成字符串用Arrays.toString()是最简单最好的;
5.如要用拼接一个数组元素,但是中间想添加一些自定义字符用String.join()比较好,或者也可以用StringBuilder在每次append()数组内容之前先append()一下自定义元素;
6.如果要保证线程安全的话必须用StringBuffer
7.String自带的concat()方法因为每次都会新建一个String对象,而且参数限制太大,所以很少用