使用Docker-compose实现Tomcat+Nginx负载均衡
1.理解nginx反向代理原理;
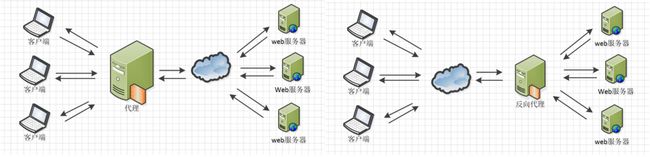
- Nginx在做反向代理时,提供性能稳定,并且能够提供配置灵活的转发功能。Nginx可以根据不同的正则匹配,采取不同的转发策略,比如图片文件结尾的走文件服务器,动态页面走web服务器,只要你正则写的没问题,又有相对应的服务器解决方案,你就可以随心所欲的玩。并且Nginx对返回结果进行错误页跳转,异常判断等。如果被分发的服务器存在异常,他可以将请求重新转发给另外一台服务器,然后自动去除异常服务器。
2.nginx代理tomcat集群,代理2个以上tomcat
- 文件目录

- nginx配置文件default.conf
upstream tomcats {
server ctc1:8080 weight=2; # 主机名:端口号,tomcat默认端口号8080,默认使用轮询策略
server ctc2:8080 weight=3;
server ctc3:8080 weight=4;
}
server {
listen 2420;
server_name localhost;
location / {
proxy_pass http://tomcats;# 请求转向tomcats
}
}
- docker-compose.yml
version: "3.8"
services:
nginx:
image: nginx
container_name: cngx
ports:
- 80:2420
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat1
- tomcat2
- tomcat3
tomcat1:
image: tomcat
container_name: ctc1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat2:
image: tomcat
container_name: ctc2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat3:
image: tomcat
container_name: ctc3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
3.负载均衡测试
- 轮询策略
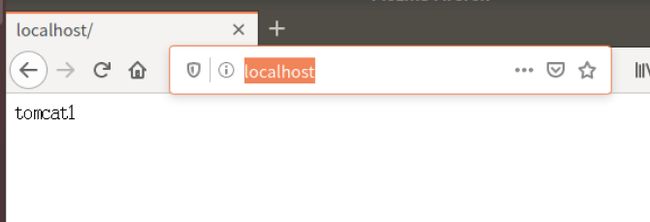
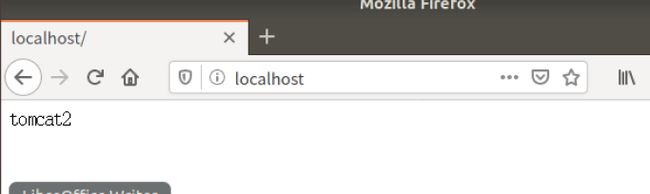
测试可以通过多次刷新浏览器也可以编写程序进行测试,上面的配置文件就是默认轮询策略的
import requests
url="http://localhost"
for i in range(0,10):
reponse=requests.get(url)
print(reponse.text)
//编写完以后用python3 文件名进行测试
多次刷新也可以出结果
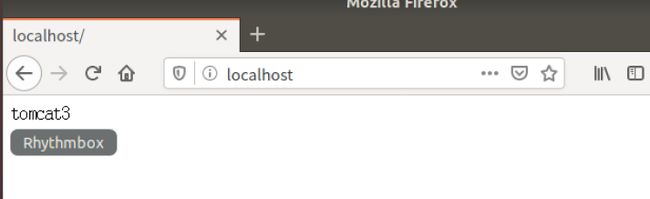
- 权重策略
修改default.conf后重启nginx
upstream tomcats {
server ctc1:8080 weight=2; # 主机名:端口号,tomcat默认端口号8080,默认使用轮询策略
server ctc2:8080 weight=3;
server ctc3:8080 weight=4;
}
server {
listen 2420;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}

用程序测试
import requests
url="http://localhost"
context={}
for i in range(0,100):
response=requests.get(url)
if response.text in context:
context[response.text]+=1
else:
context[response.text]=1
print(context)
//编写完以后用python3 文件名进行测试
测试结果里返回的结果和配置文件里的权重比值2:3:4基本一致
使用Docker-compose部署javaweb运行环境
因为实在不会写,用了老师的资料
- 文件结构
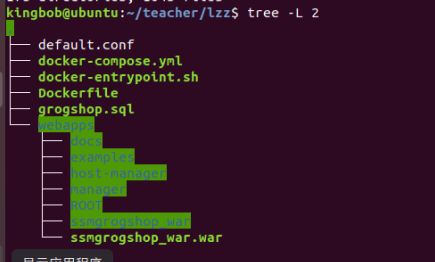
- docker-compose.yml
version: "3" #版本
services: #服务节点
tomcat: #tomcat 服务
image: tomcat #镜像
hostname: hostname #容器的主机名
container_name: tomcat00 #容器名
ports: #端口
- "5050:8080"
volumes: #数据卷
- "./webapps:/usr/local/tomcat/webapps"
- ./wait-for-it.sh:/wait-for-it.sh
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.15
mymysql: #mymysql服务
build: . #通过MySQL的Dockerfile文件构建MySQL
image: mymysql:test
container_name: mymysql
ports:
- "3309:3306"
#红色的外部访问端口不修改的情况下,要把Linux的MySQL服务停掉
#service mysql stop
#反之,将3306换成其它的
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_unicode_ci'
]
environment:
MYSQL_ROOT_PASSWORD: "123456"
networks:
webnet:
ipv4_address: 15.22.0.6
nginx:
image: nginx
container_name: "nginx-tomcat"
ports:
- 8080:8080
volumes:
- ./default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
tty: true
stdin_open: true
networks:
webnet:
ipv4_address: 15.22.0.7
networks: #网络设置
webnet:
driver: bridge #网桥模式
ipam:
config:
-
subnet: 15.22.0.0/24 #子网
- default.conf
upstream tomcat123 {
server tomcat00:8080;
}
server {
listen 8080;
server_name localhost;
location / {
proxy_pass http://tomcat123;
}
}
- docker-entrypoint.sh
#!/bin/bash
mysql -uroot -p123456 << EOF # << EOF 必须要有
source /usr/local/grogshop.sql;
- Dockerfile(配置mysql)
# 这个是构建MySQL的dockerfile
FROM registry.saas.hand-china.com/tools/mysql:5.7.17
# mysql的工作位置
ENV WORK_PATH /usr/local/
# 定义会被容器自动执行的目录
ENV AUTO_RUN_DIR /docker-entrypoint-initdb.d
#复制gropshop.sql到/usr/local
COPY grogshop.sql /usr/local/
#把要执行的shell文件放到/docker-entrypoint-initdb.d/目录下,容器会自动执行这个shell
COPY docker-entrypoint.sh $AUTO_RUN_DIR/
#给执行文件增加可执行权限
RUN chmod a+x $AUTO_RUN_DIR/docker-entrypoint.sh
# 设置容器启动时执行的命令
#CMD ["sh", "/docker-entrypoint-initdb.d/import.sh"]
- 修改这个配置文件的IP
vim ~/teacher/lzz/webapps/ssmgrogshop_war/WEB-INF/classes/ jdbc.properties
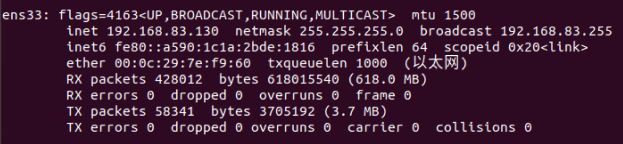
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://192.168.83.130:3309/grogshop?useUnicode=true&characterEncoding=utf-8
username=root
password=123456
- 启动服务

- 浏览器访问
http://127.0.0.1:8080/ssmgrogshop_war
http://主机ip地址:8080/ssmgrogshop_war
上面端口号也可以用5050访问tomcat
- 增加房间
- 操作结果
使用Docker搭建大数据集群环境
- 检查有没有ubuntu镜像,没有去pull一个
docker pull ubuntu
- 创建一个目录用来像Docker里的ubuntu镜像传文件
mkdir ~/build
- 创建容器
sudo docker run -it -v /home/kingbob/build:/root/build --name ubuntu ubuntu
- 进入容器后,为了让安装速度更快,进行换源,选用阿里云
cat</etc/apt/sources.list #覆盖掉原先内容,注意左边只有一个>,<是覆盖;<>则变成追加
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
EOF
- 换好源后按以下操作安装
apt-get update
apt-get install vim # 安装vim软件
apt-get install ssh # 安装sshd,因为在开启分布式Hadoop时,需要用到ssh连接slave:
/etc/init.d/ssh start # 运行脚本即可开启sshd服务器
vim ~/.bashrc
/etc/init.d/ssh start # 在该文件中最后一行添加如下内容,实现进入Ubuntu系统时,都能自动启动sshd服务
- 配置ssh
ssh-keygen -t rsa # 一直按回车即可
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
- 安装JDK8
apt-get install openjdk-8-jdk
vim ~/.bashrc # 在文件末尾添加以下两行,配置Java环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc # 使.bashrc生效
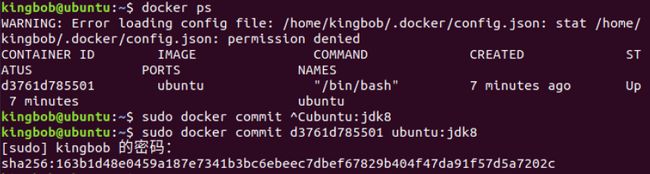
- 安装完后好保存镜像后创建容器
#另开一个终端
sudo docker commit 容器id ubuntu:jdk8 #讲其保存说明是jkd8版本的ubuntu
sudo docker run -it -v /home/kingbob/build:/root/build --name ubuntu-jdk8 ubuntu:jdk8
#开启保存的那份镜像ubuntu:jdk8
- 安装Hadoop
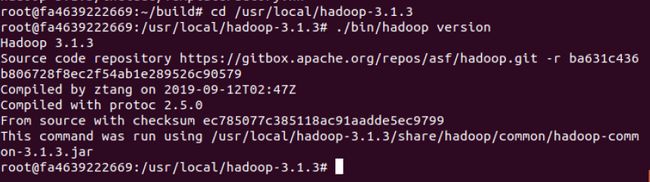
cd /root/build
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local #因为做过大数据实验,所以直接拷贝hadoop的压缩包到build文件夹里
cd /usr/local/hadoop-3.1.3
./bin/hadoop version # 验证安装
- 配置Hadoop集群
这里的一些配置文件直接用大数据实验里的配置就行
hadoop-env.sh
cd /usr/local/hadoop-3.1.3/etc/hadoop #进入配置文件存放目录
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ # 在任意位置添加
core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/usr/local/hadoop-3.1.3/tmp
A base for other temporary derectories.
hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop-3.1.3/tmp/dfs/name
dfs.namenode.data.dir
file:/usr/local/hadoop-3.1.3/tmp/dfs/data
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
mapreduce.application.classpath
/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/lib/*,/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/*
yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.vmem-pmem-ratio
2.5

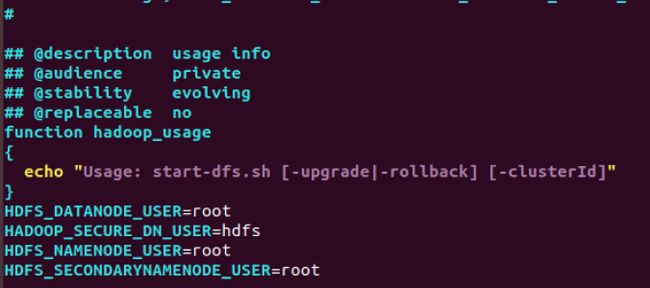
- 对于start-dfs.sh和stop-dfs.sh文件,添加下列参数
cd /usr/local/hadoop-3.1.3/sbin
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
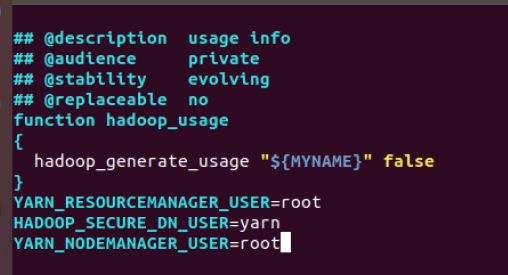
- 对于start-yarn.sh和stop-yarn.sh,添加下列参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 保存镜像
sudo docker commit 容器id ubuntu/hadoopinstalled
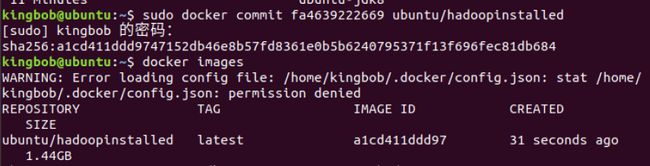
- 从三个终端分别开启三个容器运行ubuntu/hadoopinstalled镜像
# 以下三条对应三个终端
sudo docker run -it -h master --name master ubuntu/hadoopinstalled
sudo docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled
sudo docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled
- 三个终端分别打开/etc/hosts,根据各自ip修改为如下形式
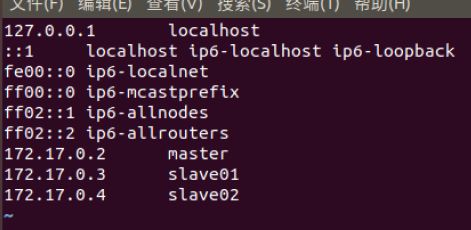
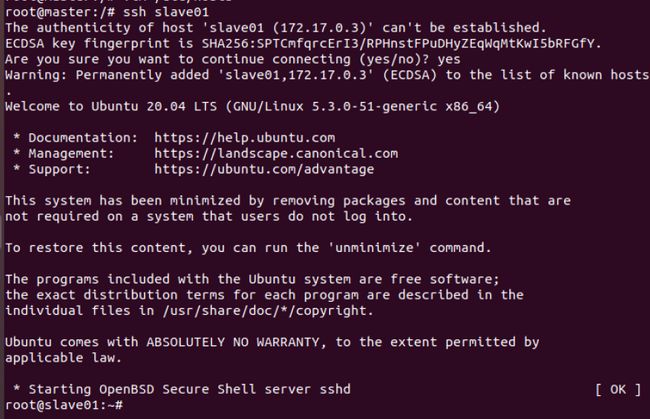
- mater结点上连接slave
ssh slave
exit
- master上将localhost改成slave的映射
vim /usr/local/hadoop-3.1.3/etc/hadoop/workers
slave01
slave02
- 测试Hadoop集群
cd /usr/local/hadoop-3.1.3
bin/hdfs namenode -format #首次启动Hadoop需要格式化
sbin/start-all.sh #启动所有服务
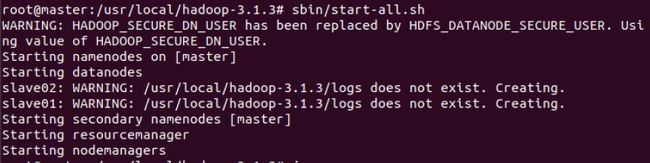
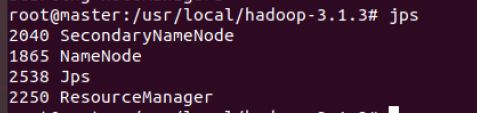
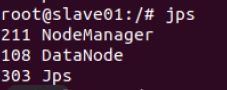
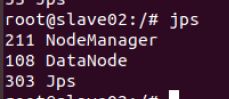

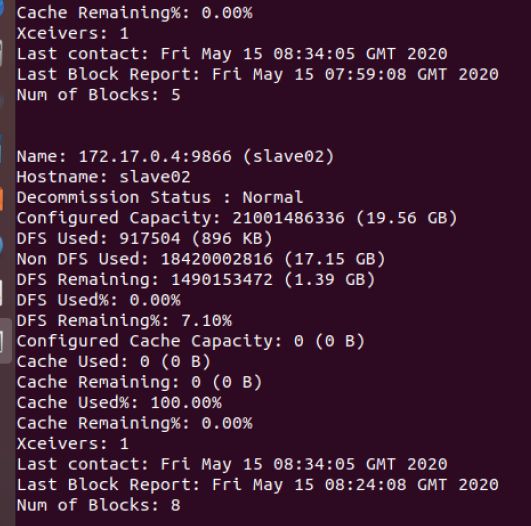
- 在HDFS里建文件夹
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root #注意input文件夹是在root目录下
bin/hdfs dfs -mkdir input

- 新建一个测试样例,上传到input文件夹

- 运行mapreduce的测试样例,这里用的是计算字符串个数的样例
bin/hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount input output
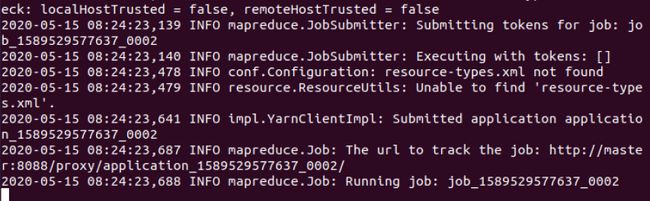
- 查看结果
./bin/hdfs dfs -cat output/*
- 使用完记得关闭服务
sbin/stop-all.sh
实验问题
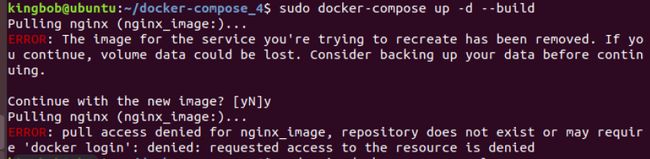
- 一个问题就是网络的问题换了中科院还有阿里的源都有报这样的错,后面换自己的热点连接到电脑,虽然还是不快,但是这个报错解决了,还有第三张图要注意一下docker-compose.yml文件里nginx的镜像名是nginx要直接从你当前docker里拥有的镜像名,改成存在的镜像名就行


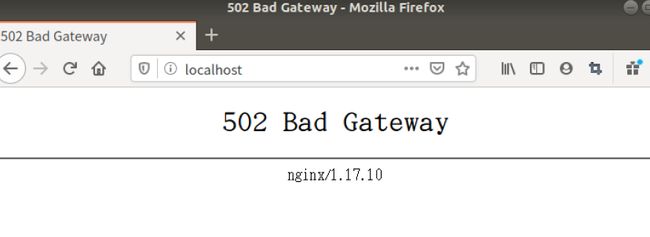
- 还有个问题就是在容器创建完一会,如果用浏览器打开端口报这个错,过几分钟再打开就没事了
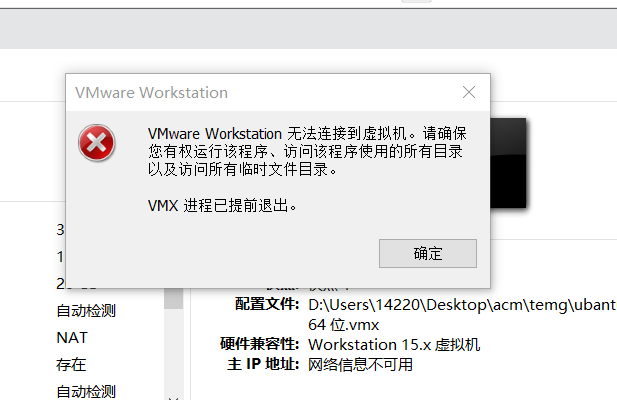
- 最让我心态爆炸的就是这个错了,在我大数据部署到最后几步的时候,虚拟机死机了,等了它一个多小时还是没有反应以后用控制台强制关闭VMware进程然后再启动就变这样了,网上各种方法用了还是没用,没办法只能重新做一遍实验,一个上午的时间直接打水漂,建议虚拟机内存开3G以上稳一点