python webdriver简单实例:爬取网页图片
Python2.7爬取网页:http://tieba.baidu.com/p/4114581614中的food图片
一、获取网页
首先,通过webdriver,获取该网页源码,然后通过正则表达式匹配出所有图片,最后将其保存在指定目录。
图片:
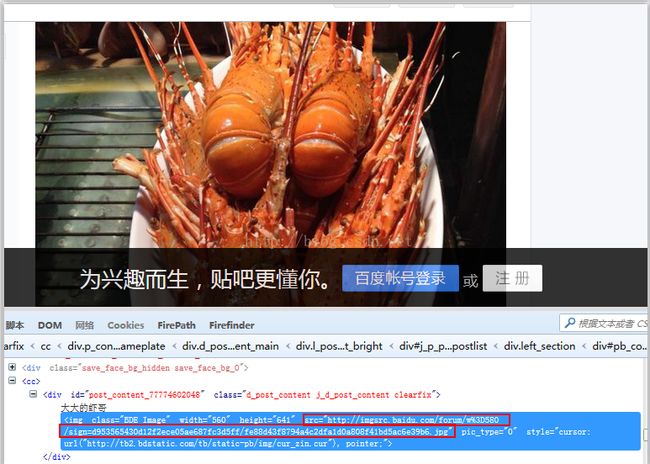
二、代码实现
#coding=utf-8
import urllib,re,os
from selenium import webdriver
driver = webdriver.Firefox()
def init():
driver.maximize_window()
driver.get("http://tieba.baidu.com/p/4114581614")
driver.set_page_load_timeout(60)
def crawler():
content=driver.page_source
reg=r'src="(http://imgsrc.baidu.com/forum/w.+?\.jpg)"'
imglist=re.findall(reg,content)
print imglist
num=1
for imgurl in imglist:
print imgurl
imgname = "%03d" % num
urllib.urlretrieve(imgurl, "d:/py/img/food"+os.sep+str(imgname)+".jpg")
num+=1
def drop():
driver.quit()
if __name__ == '__main__':
init()
crawler()
drop()