python爬虫实践之模拟登录
有些网站设置了权限,只有在登录了之后才能爬取网站的内容,如何模拟登录,目前的方法主要是利用浏览器cookie模拟登录。
浏览器访问服务器的过程
在用户访问网页时,不论是通过URL输入域名或IP,还是点击链接,浏览器向WEB服务器发出了一个HTTP请求(Http
Request),WEB服务器接收到客户端浏览器的请求之后,响应客户端的请求,发回相应的响应信息(Http Response),浏览器解析引擎,排版引擎分析返回的内容,呈现给用户。WEB应用程序在于服务器交互的过程中,HTTP请求和响应时发送的都是一个消息结构。

Http消息
当浏览器向服务器发送请求的时候,发出http请求消息报文,服务器返回数据时,发出http响应消息报文,这两种类型的消息都是由一个起始行,消息头,一个指示消息头结束的空行和可选的消息体组成。http请求消息中,起始行包括请求方法,请求的资源, HTTP协议的版本号,消息头包含各种属性,消息体包含数据,GET请求并没有消息主体,因此在消息头后的空白行中没有其他数据。Http响应消息中,起始行包括HTTP协议版本,http状态码和状态,消息头包含各种属性,消息体包含服务器返回的数据内容。

如下图从fiddler抓取的http请求和http响应,GET请求内容为空,故消息头之后的空行和消息体都为空。

服务器发送的响应消息如下,浏览器正常接收到服务器发回的http报文
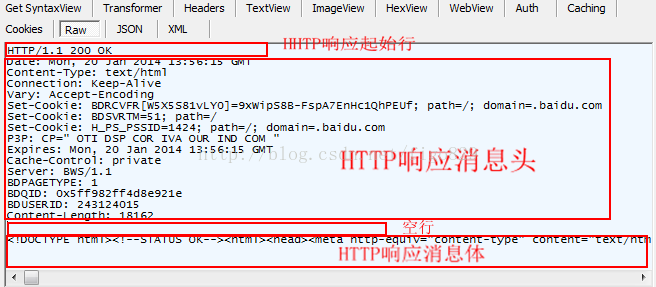

从上可以看到,cookie在http请求和http响应的头信息中,cookie是消息头的一种很重要的属性。
什么是Cookie?
当用户通过浏览器首次访问一个域名时,访问的WEB服务器会给客户端发送数据,以保持WEB服务器与客户端之间的状态保持,这些数据就是Cookie,它是 Internet 站点创建的 ,为了辨别用户身份而储存在用户本地终端上的数据,Cookie中的信息一般都是经过加密的,Cookie存在缓存中或者硬盘中,在硬盘中的是一些小文本文件,当你访问该网站时,就会读取对应网站的Cookie信息,Cookie有效地提升了我们的上网体验。一般而言,一旦将 Cookie 保存在计算机上,则只有创建该 Cookie 的网站才能读取它。
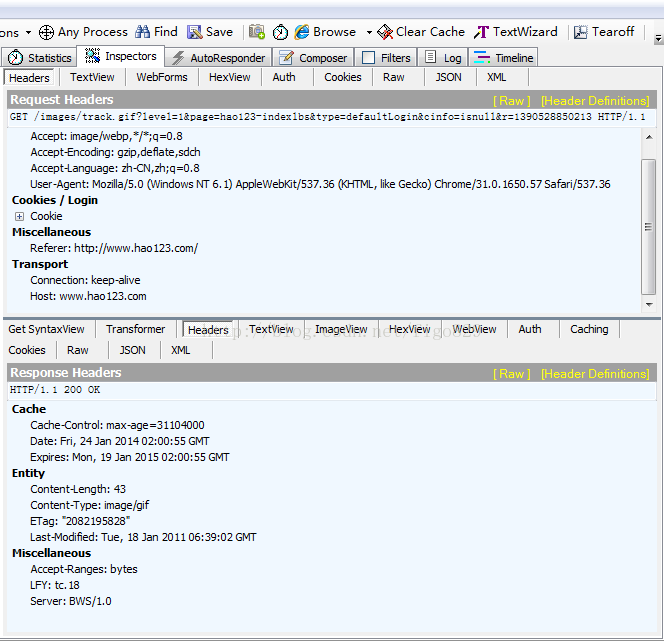
为什么需要Cookie
Http协议是一个无状态的面向连接的协议,Http协议是基于tcp/ip协议层之上的协议,当客户端与服务器建立连接之后,它们之间的TCP连接一直都是保持的,至于保持的时间是多久,是通过服务器端来设置的,当客户端再一次访问该服务器时,会继续使用上一次建立的连接,但是,由于Http协议是无状态的,WEB服务器并不知道这两个请求是否同一个客户端,这两次请求之间是独立的。 为了解决这个问题, Web程序引入了Cookie机制来维护状态.cookie可以记录用户的登录状态,通常web服务器会在用户登录成功后下发一个签名来标记session的有效性,这样免去了用户多次认证和登录网站。记录用户的访问状态。
Cookie的种类
会话Cookie(Session Cookie):这个类型的cookie只在会话期间内有效,保存在浏览器的缓存之中,用户访问网站时,会话Cookie被创建,当关闭浏览器的时候,它会被浏览器删除。
持久Cookie(Persistent Cookie): 这个类型的cookie长期在用户会话中生效。当你设置cookie的属性Max-Age为1个月的话,那么在这个月里每个相关URL的http请求中都会带有这个cookie。所以它可以记录很多用户初始化或自定义化的信息,比如什么时候第一次登录及弱登录态等。
Secure cookie:安全cookie是在https访问下的cookie形态,以确保cookie在从客户端传递到Server的过程中始终加密的。
HttpOnly Cookie :这个类型的cookie只能在http(https)请求上传递,对客户端脚本语言无效,从而有效避免了跨站攻击。
第三方cookie: 第一方cookie是当前访问的域名或子域名下的生成的Cookie。
第三方cookie:第三方cookie是第三方域名创建的Cookie。
Cookie的构成
Cookie是http消息头中的一种属性,包括:Cookie名字(Name)Cookie的值(Value),Cookie的过期时间(Expires / Max-Age),Cookie作用路径(Path),Cookie所在域名(Domain),使用Cookie进行安全连接(Secure)。
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
python模拟登录
设置一个cookie处理对象,它负责 将cookie添加到http请求中,并能从http响应中得到cookie , 向网站登录页面发送一个请求Request, 包括登录url,POST请求的数据,Http header 利用urllib2.urlopen发送请求,接收WEB服务器的Response。
首先我们查看登陆页面源码
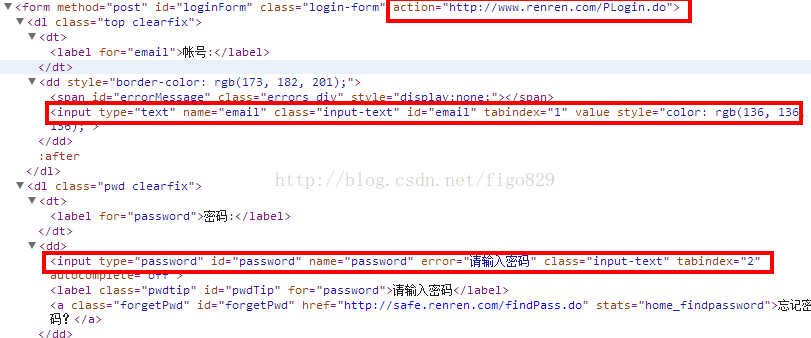
当我们使用urllib处理url的时候,实际上是通过urllib2.OpenerDirector实例进行工作,他会自己调用资源进行各种操作如通过协议、打开url、处理cookie等。而urlopen方法使用的是默认的opener来处理问题,基本的urlopen()函数不支持验证、cookie或其他的HTTP高级功能。要支持这些功能,必须使用build_opener()函数来创建自己的自定义Opener对象。
cookielib模块定义了自动处理HTTP cookies的类,用来访问那些需要cookie数据的网站,cookielib模块包括CookieJar,FileCookieJar,CookiePolicy,DefaultCookiePolicy,Cookie及FileCookieJar的子类MozillaCookieJar和LWPCookieJar,CookieJar对象可以管理HTTP cookies,将cookie添加到http请求中,并能从http响应中得到cookie,FileCookieJar对象主要是从文件中读取cookie或创建cookie,其中,MozillaCookieJar是为了创建与Mozilla浏览器cookies.txt兼容的FileCookieJar实例,LWPCookieJar是为了创建与libwww-perl的Set-Cookie3文件格式兼容的FileCookieJar实例,用LWPCookieJar保存的cookie文件易于人类阅读。默认的是FileCookieJar没有save函数,而MozillaCookieJar或LWPCookieJar都已经实现了。 所以可以用MozillaCookieJar或LWPCookieJar,去自动实现cookie的save。
#! /usr/bin/env python
#coding:utf-8
import sys
import re
import urllib2
import urllib
import requests
import cookielib
## 这段代码是用于解决中文报错的问题
reload(sys)
sys.setdefaultencoding("utf8")
#####################################################
#登录人人
loginurl = 'http://www.renren.com/PLogin.do'
logindomain = 'renren.com'
class Login(object):
def __init__(self):
self.name = ''
self.passwprd = ''
self.domain = ''
self.cj = cookielib.LWPCookieJar()
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cj))
urllib2.install_opener(self.opener)
def setLoginInfo(self,username,password,domain):
'''设置用户登录信息'''
self.name = username
self.pwd = password
self.domain = domain
def login(self):
'''登录网站'''
loginparams = {'domain':self.domain,'email':self.name, 'password':self.pwd}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
req = urllib2.Request(loginurl, urllib.urlencode(loginparams),headers=headers)
response = urllib2.urlopen(req)
self.operate = self.opener.open(req)
thePage = response.read()
if __name__ == '__main__':
userlogin = Login()
username = 'username'
password = 'password'
domain = logindomain
userlogin.setLoginInfo(username,password,domain)
userlogin.login()