前言:今天上午接到一个网友的求助,说是服务器的根分区满了。但是,找不到具体的大文件在哪里。由于故障确实很古怪,我就要来了故障服务器的相关账户密码。
故障服务器相关环境:
系统:Centos 6.5
selinux: Disabled
iptables:开启,但是默认策略全部是:ACCEPT
我方辅助服务器相关环境:
系统:Centos 6.5
selinux:Permissive
iptables:开启,但是默认策略全部是:ACCEPT
首先我们在故障服务器上先简单摸排一下问题的情况:
[root@abc ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/simfs 20G 970M 0 100% /
none 512M 4.0K 512M 1% /dev
none 512M 0 512M 0% /dev/shm
[root@abc ~]# df -ih
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/simfs 10M 27K 10M 1% /
none 128K 156 128K 1% /dev
none 128K 1 128K 1% /dev/shm
[root@abc ~]# cd /
[root@abc /]# du -sh *
6.7M bin
12K boot
4.0K dev
7.6M etc
4.0K home
11M lib
39M lib64
4.0K lost+found
4.0K media
4.0K mnt
16K nonexistent
4.0K opt
du: cannot access `proc/626/task/2558': No such file or directory
du: cannot access `proc/2551/task/2551/fd/4': No such file or directory
du: cannot access `proc/2551/task/2551/fdinfo/4': No such file or directory
du: cannot access `proc/2551/fd/4': No such file or directory
du: cannot access `proc/2551/fdinfo/4': No such file or directory
0 proc
478M root
13M sbin
4.0K selinux
4.0K srv
0 sys
152K tmp
960M usr
197M var
通过du命令,我们可以看到,磁盘空间并没有使用多少。加起来不超过2G。
接下来我们看一下内存:
[root@abc ~]# free -m
total used free shared buffers cached
Mem: 1024 76 947 0 0 28
-/+ buffers/cache: 47 976
Swap: 0 0 0
内存也是充足的,并且没有开启swap分区。
接着查看一下磁盘挂载的情况:
[root@abc ~]# mount
/dev/simfs on / type simfs (rw,relatime)
proc on /proc type proc (rw,relatime)
sysfs on /sys type sysfs (rw,relatime)
none on /dev type devtmpfs (rw,relatime,mode=755)
none on /dev/pts type devpts (rw,relatime,gid=5,mode=620,ptmxmode=000)
none on /dev/shm type tmpfs (rw,relatime)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,relatime)
[root@abc ~]# fdisk /dev/simfs
Unable to open /dev/simfs
文件系统是:simfs,这个文件系统没有见过,但是估计应该是vps供应商采用的,但是执行fdisk报错,暂时记下
接下来top命令查看一下,看看是否有异常的进程:
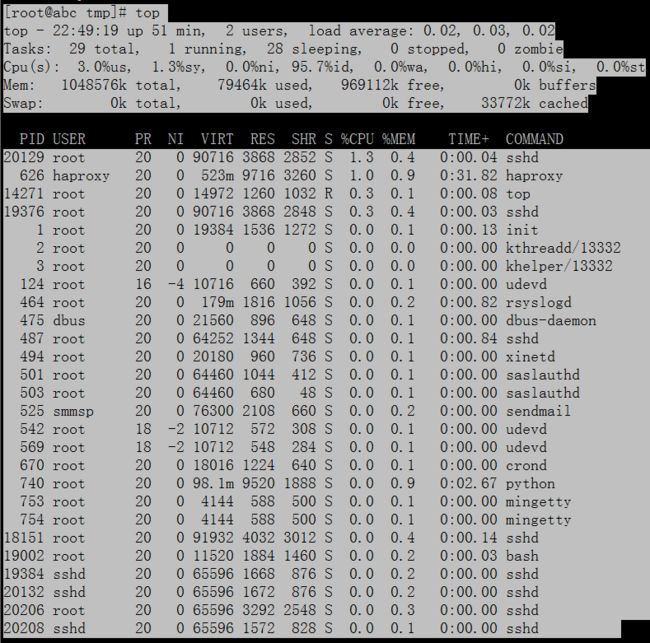
通过top命令并没有查到异常的进程,并且服务器的负载并不高。
接下来查看一下服务器打开的端口:
[root@abc tmp]# ss -tnlp
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 0 *:22 *:* users:(("sshd",487,3))
LISTEN 0 0 :::1999 :::* users:(("python",740,4))
LISTEN 0 0 :::2000 :::* users:(("python",740,9))
LISTEN 0 0 :::2001 :::* users:(("python",740,11))
LISTEN 0 0 :::2002 :::* users:(("python",740,7))
LISTEN 0 0 :::2003 :::* users:(("python",740,6))
LISTEN 0 0 :::2004 :::* users:(("python",740,17))
LISTEN 0 0 :::2005 :::* users:(("python",740,19))
LISTEN 0 0 :::2006 :::* users:(("python",740,13))
LISTEN 0 0 :::22 :::* users:(("sshd",487,4))
LISTEN 0 0 :::2007 :::* users:(("python",740,15))
LISTEN 0 0 :::2008 :::* users:(("python",740,21))
LISTEN 0 0 :::2009 :::* users:(("python",740,23))
LISTEN 0 0 :::2010 :::* users:(("python",740,25))
可以看到服务器打开了很多端口,有sshd的22,另外一些都是python程序打开的。
因为这个是云服务器,有可能是服务器端口放出来了,但是在云厂商的web防火墙那边把端口给封锁掉了,所以我们通过辅助服务器再来扫描一下此服务器:
Starting Nmap 5.51 ( http://nmap.org ) at 2018-09-07 10:44 CST
Nmap scan report for abc.com (1.1.1.1)
Host is up (0.20s latency).
Not shown: 982 closed ports
PORT STATE SERVICE
22/tcp open ssh
135/tcp filtered msrpc
139/tcp filtered netbios-ssn
445/tcp filtered microsoft-ds
593/tcp filtered http-rpc-epmap
1999/tcp open tcp-id-port
2000/tcp open cisco-sccp
2001/tcp open dc
2002/tcp open globe
2003/tcp open finger
2004/tcp open mailbox
2005/tcp open deslogin
2006/tcp open invokator
2007/tcp open dectalk
2008/tcp open conf
2009/tcp open news
2010/tcp open search
4444/tcp filtered krb524
通过nmap扫描此服务器,发现确实是开了这么多端口,服务器的主人真的是胆子很大啊,大家千万不要学习这位兄弟。
我们再通过ps查看一下跑的相关应用:
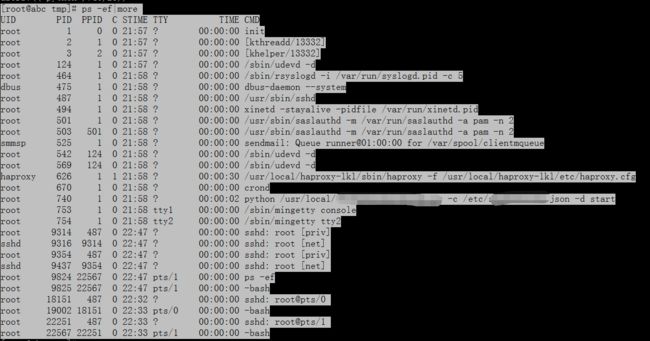
跑的进程非常的少,并且也没有看起来很异常的进程。额,打码的是因为此进程是:是是。大家忽略哈。
通过w命令,查看发现登录此服务器的用户有2个,一个是服务器主人,一个是我

此时,简单的(额,算不算复杂?)服务器状况排查,已经告一段落了。根据看到的情况,我怀疑是不是手动删除了某个大文件,但是这个文件还被Python或者haproxy之类的进程占用中。导致磁盘没有释放出来。
我们通过lsof查看一下:
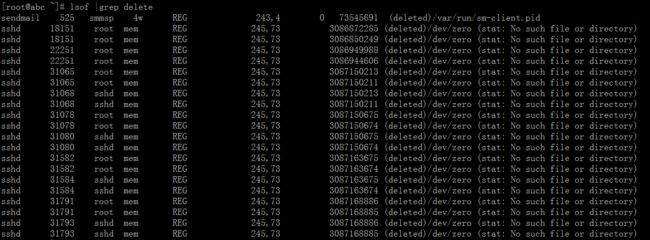
发现并没有什么大的文件,sshd这个删除看起来比较诡异。但是应该不是这个问题,因为询问过服务器主人,发生这个问题后,他都已经重启过服务器了,但是,此问题还是存在。
既然这样,我怀疑是不是服务器被入侵了,命令都被换掉了。所以,我们看到的不一定是真相。
看一下df命令的大小,看看跟我辅助服务器的命令大小是否一致:
故障服务器:
[root@abc ~]# which df
/bin/df
[root@abc ~]# ll /bin/df
-rwxr-xr-x 1 root root 90544 Jun 25 2014 /bin/df
辅助服务器:
[root@CTE2-nginx-tomcat ~]# ll /bin/df
-rwxr-xr-x. 1 root root 95880 Nov 22 2013 /bin/df
服务器的系统版本是一致的,按道理来说,命令的大小应该是一致的。但是故障服务器的命令比辅助服务器的要小一些。
我们再看一下ps命令
故障服务器:
[root@abc tmp]# which ps
/bin/ps
[root@abc tmp]# ll /bin/ps
-rwxr-xr-x 1 root root 82024 Nov 15 2012 /bin/ps
辅助服务器:
[root@CTE2-nginx-tomcat tmp]# which ps
/bin/ps
[root@CTE2-nginx-tomcat tmp]# ll /bin/ps
-rwxr-xr-x. 1 root root 89480 Jul 12 2017 /bin/ps
这里的话,也是这个情况。故障服务器的命令比辅助服务器的大小要小一些
这就更能证明我们的推测:命令可能已经被动过手脚了,既然这样,那我们把辅助服务器的正常命令上传到故障服务器的/tmp目录,然后再看看结果:
[root@CTE2-nginx-tomcat tmp]# scp /bin/ps 1.1.1.1:/tmp/
Address 1.1.1.1 maps to abc.com, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!
[email protected]'s password:
ps 100% 87KB 87.4KB/s 00:00
好了,辅助服务器的ps命令已经传到故障服务器,接下来我们看一下,是否会有相关的变化:
故障服务器:
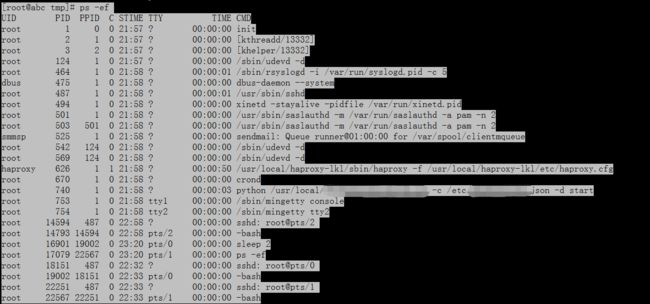
辅助服务器的ps在故障服务器上执行结果:
额,这就很尴尬了。看起来并没有什么问题,两个命令的执行结果,是一致的。这台服务器并没有什么异常的进程,并且负载也没有升高。基本上可以排除被入侵的可能,一般情况下,有问题的命令是会比正常的命令大很多,而这里是稍微小一点点
比较遗憾,当时忘记查看命令的版本了,估计是版本有小差异导致的。
现在故障排查,陷入了迷茫,这种问题还真的是罕见。一定是哪里我们遗漏了相关的信息。忽然想起了那个奇怪的文件系统:simfs
既然没有其他的问题,那有没有可能是文件系统simfs导致的呢?
接下来我查询了相关的资料:发现问题竟然是这样的--You have no own file system. The /dev/simfs is just a fake device name that OpenVZ uses to create it's fake file system. Your real files (as well as the files of all other containers) reside on the host node's /vz filesystem. That filesystem (/vz on the hostnode) is full. There could be many reasons for this, but in most cases this is caused by heavy overselling of the disk space.
说白了,就是因为vps供应商,超额售卖vps虚拟机,宿主机上面已经没有磁盘空间了。导致vps虚拟机的磁盘,也无法使用。至此问题终于被找到,接下来就是让网友自己联系vps供应商更换vps了。
总结:不能放过任何的蛛丝马迹,有的时候故障不一定是自身引起的,要考虑具体的相关环境。
引用:http://www.webhostingtalk.com/showthread.php?t=1083184