语言模型涉及的相关概念
1 什么是语言模型:
语言模型其实就是看一句话是不是正常人说出来的(判断自然语言上下文相关的特性)。在很多NLP任务中都会用到,比如机器翻译、语音识别得到若干候选之后。
语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率 P(w1,w2,…,wt)。
W依次表示这句话中的各个词。有个很简单的推论
![]()
常用的语言模型都是在近似地求 ![]() 比如 n-gram 模型就是用 P(wt|wt−n+1,…,wt−1)
比如 n-gram 模型就是用 P(wt|wt−n+1,…,wt−1)
近似表示。
2 涉及的相关概念
2.1马尔科夫假设
假设一个词wiwi在某个位置出现的概率只与它前面的一个词wi−1wi−1有关, 这就是马尔可夫假设.
基于此假设, 得到
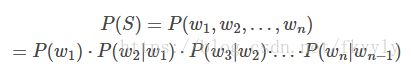
2.2n-gram model
上式对应的统计语言模型就是bi-gram model, 二元模型.类似地, 假设一个词wiwi在某个位置出现的概率只与它前面的两个词wi−1,wi−2wi−1,wi−2有关, 那么就得到了三元模型.
2.3词袋模型 Bag of words.对于一个文本,忽略其词法, 语法, 语义, 仅将其看做是一个词的集合, 文本中每个词的出现都是独立的, 那么就得到了词袋模型. 一个语料库由若干文本组成, 先计算出语料库的词袋, 然后就可以用词向量来表示每个文本.
2.4词向量
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国
然后使用one hot对每段话提取特征向量:
 ;
; ;
;
因此我们得到了最终的特征向量为
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 -> 1,1,1,1,0
爸爸妈妈爱中国 -> 0,1,1,1,1
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
https://www.cnblogs.com/lianyingteng/p/7755545.html
2.4.2 distributed representation
对词典中的每一个词语都用固定长度的向量来表示, 不同于one-hot, 它形如
![]()
在word2vec中, 这个向量的维度是自定义的, 默认是100维
对词向量的介绍请看https://blog.csdn.net/fkyyly/article/details/79011789