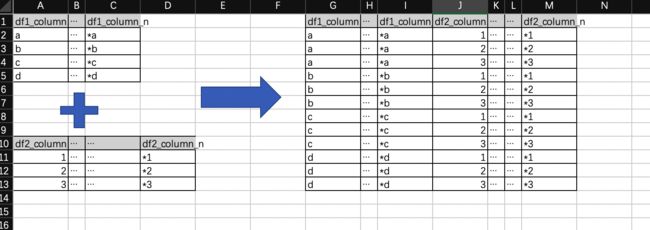
合并两个没有共同列的dataframe,相当于按行号求笛卡尔积。
最终效果如下
以下代码是参考别人的代码修改的:
def cartesian_df(A,B):
new_df = pd.DataFrame(columns=list(A).extend(list(B)))
for _,A_row in A.iterrows():
for _,B_row in B.iterrows():
row = A_row.append(B_row)
new_df = new_df.append(row,ignore_index=True)
return new_df
#这个方法,如果两张表列名重复会出错
这段代码的思路是对两个表的每一行进行循环,运行速度比较慢,复杂度应该是O(m*n),m是A表的行数,n是B表的行数。
因为我用到的合并表行数比较多,时间太慢,所以针对上面的代码进行了优化。
思路是利用dataframe的merge功能,先循环复制A表,将循环次数添加为列,直接使用merge合并,复杂度应该为O(n)(n是B表的行数),代码如下:
def cartesian_df(df_a,df_b):
'求两个dataframe的笛卡尔积'
#df_a 复制n次,索引用复制次数
new_df_a = pd.DataFrame(columns=list(df_a))
for i in range(0,df_b.shape[0]):
df_a['merge_index'] = i
new_df_a = new_df_a.append(df_a,ignore_index=True)
#df_b 设置索引为行数
df_b.reset_index(inplace = True, drop =True)
df_b['merge_index'] = df_b.index
#merge
new_df = pd.merge(new_df_a,df_b,on=['merge_index'],how='left').drop(['merge_index'],axis = 1)
return new_df
#两个原始表中不能有列名'merge_index'
使用一张8行的表和一张142行的表进行测试,优化前的方法用时:5.560689926147461秒
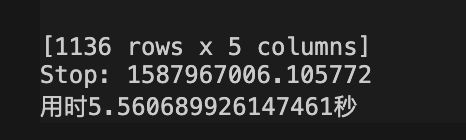
优化后的方法用时:0.1296539306640625秒(142行的表作为b表)
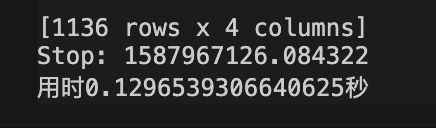
根据计算原理,将行数少的表放在b表可以更快,测试用时:0.021603107452392578秒(8行的表作为b表)
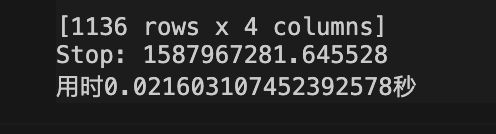
这个速度已经达到预期,基本感觉不到等待,优化完成。