Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
- 官方主页: http://www.scrapy.org/
- 中文文档:Scrapy 0.22 文档
- GitHub项目主页:https://github.com/scrapy/scrapy
Scrapy 使用了 Twisted 异步网络库来处理网络通讯。整体架构大致如下(注:图片来自互联网):
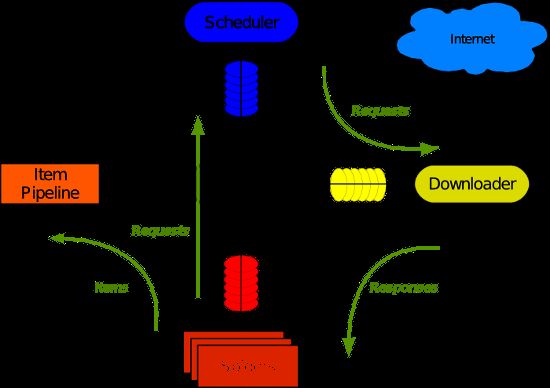
Scrapy主要包括了以下组件:
- 引擎,用来处理整个系统的数据流处理,触发事务。
- 调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
- 项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发。
1. 安装
安装 python
Scrapy 目前最新版本为0.22.2,该版本需要 python 2.7,故需要先安装 python 2.7。这里我使用 centos 服务器来做测试,因为系统自带了 python ,需要先检查 python 版本。
查看python版本:
$ python -V
Python 2.6.6
升级版本到2.7:
$ Python 2.7.6:
$ wget http://python.org/ftp/python/2.7.6/Python-2.7.6.tar.xz
$ tar xf Python-2.7.6.tar.xz
$ cd Python-2.7.6
$ ./configure --prefix=/usr/local --enable-unicode=ucs4 --enable-shared LDFLAGS="-Wl,-rpath /usr/local/lib"
$ make && make altinstall
建立软连接,使系统默认的 python指向 python2.7
$ mv /usr/bin/python /usr/bin/python2.6.6
$ ln -s /usr/local/bin/python2.7 /usr/bin/python
再次查看python版本:
$ python -V
Python 2.7.6
安装
这里使用 wget 的方式来安装 setuptools :
$ wget https://bootstrap.pypa.io/ez_setup.py -O - | python
安装 zope.interface
$ easy_install zope.interface
安装 twisted
Scrapy 使用了 Twisted 异步网络库来处理网络通讯,故需要安装 twisted。
安装 twisted 前,需要先安装 gcc:
$ yum install gcc -y
然后,再通过 easy_install 安装 twisted:
$ easy_install twisted
如果出现下面错误:
$ easy_install twisted
Searching for twisted
Reading https://pypi.python.org/simple/twisted/
Best match: Twisted 14.0.0
Downloading https://pypi.python.org/packages/source/T/Twisted/Twisted-14.0.0.tar.bz2#md5=9625c094e0a18da77faa4627b98c9815
Processing Twisted-14.0.0.tar.bz2
Writing /tmp/easy_install-kYHKjn/Twisted-14.0.0/setup.cfg
Running Twisted-14.0.0/setup.py -q bdist_egg --dist-dir /tmp/easy_install-kYHKjn/Twisted-14.0.0/egg-dist-tmp-vu1n6Y
twisted/runner/portmap.c:10:20: error: Python.h: No such file or directory
twisted/runner/portmap.c:14: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:31: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘*’ token
twisted/runner/portmap.c:45: error: expected ‘=’, ‘,’, ‘;’, ‘asm’ or ‘__attribute__’ before ‘PortmapMethods’
twisted/runner/portmap.c: In function ‘initportmap’:
twisted/runner/portmap.c:55: warning: implicit declaration of function ‘Py_InitModule’
twisted/runner/portmap.c:55: error: ‘PortmapMethods’ undeclared (first use in this function)
twisted/runner/portmap.c:55: error: (Each undeclared identifier is reported only once
twisted/runner/portmap.c:55: error: for each function it appears in.)
请安装 python-devel 然后再次运行:
$ yum install python-devel -y
$ easy_install twisted
如果出现下面异常:
error: Not a recognized archive type: /tmp/easy_install-tVwC5O/Twisted-14.0.0.tar.bz2
请手动下载然后安装,下载地址在这里
$ wget https://pypi.python.org/packages/source/T/Twisted/Twisted-14.0.0.tar.bz2#md5=9625c094e0a18da77faa4627b98c9815
$ tar -vxjf Twisted-14.0.0.tar.bz2
$ cd Twisted-14.0.0
$ python setup.py install
安装 pyOpenSSL
先安装一些依赖:
$ yum install libffi libffi-devel openssl-devel -y
然后,再通过 easy_install 安装 pyOpenSSL:
$ easy_install pyOpenSSL
安装 Scrapy
先安装一些依赖:
$ yum install libxml2 libxslt libxslt-devel -y
最后再来安装 Scrapy :
$ easy_install scrapy
2. 使用 Scrapy
在安装成功之后,你可以了解一些 Scrapy 的基本概念和使用方法,并学习 Scrapy 项目的例子 dirbot 。
Dirbot 项目位于 https://github.com/scrapy/dirbot,该项目包含一个 README 文件,它详细描述了项目的内容。如果你熟悉 git,你可以 checkout 它的源代码。或者你可以通过点击 Downloads 下载 tarball 或 zip 格式的文件。
下面以该例子来描述如何使用 Scrapy 创建一个爬虫项目。
新建工程
在抓取之前,你需要新建一个 Scrapy 工程。进入一个你想用来保存代码的目录,然后执行:
$ scrapy startproject tutorial
这个命令会在当前目录下创建一个新目录 tutorial,它的结构如下:
.
├── scrapy.cfg
└── tutorial
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
这些文件主要是:
- scrapy.cfg: 项目配置文件
- tutorial/: 项目python模块, 呆会代码将从这里导入
- tutorial/items.py: 项目items文件
- tutorial/pipelines.py: 项目管道文件
- tutorial/settings.py: 项目配置文件
- tutorial/spiders: 放置spider的目录
定义Item
Items是将要装载抓取的数据的容器,它工作方式像 python 里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误。
它通过创建一个 scrapy.item.Item 类来声明,定义它的属性为 scrpy.item.Field 对象,就像是一个对象关系映射(ORM).
我们通过将需要的item模型化,来控制从 dmoz.org 获得的站点数据,比如我们要获得站点的名字,url 和网站描述,我们定义这三种属性的域。要做到这点,我们编辑在 tutorial 目录下的 items.py 文件,我们的 Item 类将会是这样
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
刚开始看起来可能会有些困惑,但是定义这些 item 能让你用其他 Scrapy 组件的时候知道你的 items 到底是什么。
编写爬虫(Spider)
Spider 是用户编写的类,用于从一个域(或域组)中抓取信息。们定义了用于下载的URL的初步列表,如何跟踪链接,以及如何来解析这些网页的内容用于提取items。
要建立一个 Spider,你可以为 scrapy.spider.BaseSpider 创建一个子类,并确定三个主要的、强制的属性:
name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字.start_urls:爬虫开始爬的一个 URL 列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些 URLS 开始。其他子 URL 将会从这些起始 URL 中继承性生成。parse():爬虫的方法,调用时候传入从每一个 URL 传回的 Response 对象作为参数,response 将会是 parse 方法的唯一的一个参数,
这个方法负责解析返回的数据、匹配抓取的数据(解析为 item )并跟踪更多的 URL。
在 tutorial/spiders 目录下创建 DmozSpider.py
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
运行项目
$ scrapy crawl dmoz
该命令从 dmoz.org 域启动爬虫,第三个参数为 DmozSpider.py 中的 name 属性值。
xpath选择器
Scrapy 使用一种叫做 XPath selectors 的机制,它基于 XPath 表达式。如果你想了解更多selectors和其他机制你可以查阅资料。
这是一些XPath表达式的例子和他们的含义:
/html/head/title: 选择HTML文档元素下面的</code> 标签。</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">/html/head/title/text()</code>: 选择前面提到的<code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);"><title></code> 元素下面的文本内容</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">//td</code>: 选择所有 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);"><td></code> 元素</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">//div[@class="mine"]</code>: 选择所有包含 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">class="mine"</code> 属性的div 标签元素</li> </ul> <p>这只是几个使用 XPath 的简单例子,但是实际上 XPath 非常强大。如果你想了解更多 XPATH 的内容,我们向你推荐这个XPath 教程</p> <p>为了方便使用 XPaths,Scrapy 提供 Selector 类, 有三种方法</p> <ul> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">xpath()</code>:返回selectors列表, 每一个select表示一个xpath参数表达式选择的节点.</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">extract()</code>:返回一个unicode字符串,该字符串为XPath选择器返回的数据</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">re()</code>: 返回unicode字符串列表,字符串作为参数由正则表达式提取出来</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">css()</code></li> </ul> <h2 id="articleHeader13" style="font-family:inherit;line-height:1.2;color:inherit;font-size:1.42857em;border-bottom-width:1px;border-bottom-style:dotted;border-bottom-color:rgb(204,204,204);"> 提取数据</h2> <p>我们可以通过如下命令选择每个在网站中的 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);"><li></code> 元素:</p> <pre class="hljs bash" style="overflow:auto;font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;line-height:1.3;color:#000000;border:none;background:rgb(246,246,246);"><code class="lang-python" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;">sel.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'//ul/li'</span>) </code></pre> <p>然后是网站描述:</p> <pre class="hljs bash" style="overflow:auto;font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;line-height:1.3;color:#000000;border:none;background:rgb(246,246,246);"><code class="lang-python" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;">sel.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'//ul/li/text()'</span>).extract() </code></pre> <p>网站标题:</p> <pre class="hljs bash" style="overflow:auto;font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;line-height:1.3;color:#000000;border:none;background:rgb(246,246,246);"><code class="lang-python" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;">sel.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'//ul/li/a/text()'</span>).extract() </code></pre> <p>网站链接:</p> <pre class="hljs bash" style="overflow:auto;font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;line-height:1.3;color:#000000;border:none;background:rgb(246,246,246);"><code class="lang-python" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;">sel.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'//ul/li/a/@href'</span>).extract() </code></pre> <p>如前所述,每个 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">xpath()</code> 调用返回一个 selectors 列表,所以我们可以结合 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">xpath()</code> 去挖掘更深的节点。我们将会用到这些特性,所以:</p> <pre class="hljs perl" style="overflow:auto;font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;line-height:1.3;color:#000000;border:none;background:rgb(246,246,246);"><code class="lang-python" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;">sites = sel.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'//ul/li'</span>) <span class="hljs-keyword" style="font-weight:bold;">for</span> site in sites: title = site.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'a/text()'</span>).extract() <span class="hljs-keyword" style="font-weight:bold;">link</span> = site.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'a/@href'</span>).extract() desc = site.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'text()'</span>).extract() <span class="hljs-keyword" style="font-weight:bold;">print</span> title, <span class="hljs-keyword" style="font-weight:bold;">link</span>, desc </code></pre> <h2 id="articleHeader14" style="font-family:inherit;line-height:1.2;color:inherit;font-size:1.42857em;border-bottom-width:1px;border-bottom-style:dotted;border-bottom-color:rgb(204,204,204);"> 使用Item</h2> <p><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">scrapy.item.Item</code> 的调用接口类似于 python 的 dict ,Item 包含多个 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">scrapy.item.Field</code>。这跟 django 的 Model 与</p> <p>Item 通常是在 Spider 的 parse 方法里使用,它用来保存解析到的数据。</p> <p>最后修改爬虫类,使用 Item 来保存数据,代码如下:</p> <pre><code class="language-python"><code class="lang-python" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;"><span class="hljs-keyword" style="font-weight:bold;">from</span> scrapy.spider <span class="hljs-keyword" style="font-weight:bold;">import</span> Spider <span class="hljs-keyword" style="font-weight:bold;">from</span> scrapy.selector <span class="hljs-keyword" style="font-weight:bold;">import</span> Selector <span class="hljs-keyword" style="font-weight:bold;">from</span> dirbot.items <span class="hljs-keyword" style="font-weight:bold;">import</span> Website <span class="hljs-class"><span class="hljs-keyword" style="font-weight:bold;">class</span> <span class="hljs-title" style="color:rgb(136,0,0);font-weight:bold;">DmozSpider</span><span class="hljs-params">(Spider)</span>:</span> name = <span class="hljs-string" style="color:rgb(136,0,0);">"dmoz"</span> allowed_domains = [<span class="hljs-string" style="color:rgb(136,0,0);">"dmoz.org"</span>] start_urls = [ <span class="hljs-string" style="color:rgb(136,0,0);">"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"</span>, <span class="hljs-string" style="color:rgb(136,0,0);">"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"</span>, ] <span class="hljs-function"><span class="hljs-keyword" style="font-weight:bold;">def</span> <span class="hljs-title" style="color:rgb(136,0,0);font-weight:bold;">parse</span><span class="hljs-params">(self, response)</span>:</span> <span class="hljs-string" style="color:rgb(136,0,0);">""" The lines below is a spider contract. For more info see: http://doc.scrapy.org/en/latest/topics/contracts.html @url http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/ @scrapes name """</span> sel = Selector(response) sites = sel.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'//ul[@class="directory-url"]/li'</span>) items = [] <span class="hljs-keyword" style="font-weight:bold;">for</span> site <span class="hljs-keyword" style="font-weight:bold;">in</span> sites: item = Website() item[<span class="hljs-string" style="color:rgb(136,0,0);">'name'</span>] = site.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'a/text()'</span>).extract() item[<span class="hljs-string" style="color:rgb(136,0,0);">'url'</span>] = site.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'a/@href'</span>).extract() item[<span class="hljs-string" style="color:rgb(136,0,0);">'description'</span>] = site.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'text()'</span>).re(<span class="hljs-string" style="color:rgb(136,0,0);">'-\s([^\n]*?)\\n'</span>) items.append(item) <span class="hljs-keyword" style="font-weight:bold;">return</span> items </code></code></pre> <p>现在,可以再次运行该项目查看运行结果:</p> <pre><code class="language-ruby"><code class="lang-bash" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;"><span class="hljs-variable">$ </span>scrapy crawl dmoz </code></code></pre> <h2 id="articleHeader15" style="font-family:inherit;line-height:1.2;color:inherit;font-size:1.42857em;border-bottom-width:1px;border-bottom-style:dotted;border-bottom-color:rgb(204,204,204);"> 使用Item Pipeline</h2> <p>在 settings.py 中设置 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">ITEM_PIPELINES</code>,其默认为<code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">[]</code>,与 django 的 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">MIDDLEWARE_CLASSES</code> 等相似。<br> 从 Spider 的 parse 返回的 Item 数据将依次被 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">ITEM_PIPELINES</code> 列表中的 Pipeline 类处理。</p> <p>一个 Item Pipeline 类必须实现以下方法:</p> <ul> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">process_item(item, spider)</code> 为每个 item pipeline 组件调用,并且需要返回一个 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">scrapy.item.Item</code> 实例对象或者抛出一个 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">scrapy.exceptions.DropItem</code> 异常。当抛出异常后该 item 将不会被之后的 pipeline 处理。参数:<br> <ul> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">item (Item object)</code> – 由 parse 方法返回的 Item 对象</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">spider (BaseSpider object)</code> – 抓取到这个 Item 对象对应的爬虫对象</li> </ul></li> </ul> <p>也可额外的实现以下两个方法:</p> <ul> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">open_spider(spider)</code> 当爬虫打开之后被调用。参数: <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">spider (BaseSpider object)</code> – 已经运行的爬虫</li> <li><code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">close_spider(spider)</code> 当爬虫关闭之后被调用。参数: <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">spider (BaseSpider object)</code> – 已经关闭的爬虫</li> </ul> <h2 id="articleHeader16" style="font-family:inherit;line-height:1.2;color:inherit;font-size:1.42857em;border-bottom-width:1px;border-bottom-style:dotted;border-bottom-color:rgb(204,204,204);"> 保存抓取的数据</h2> <p>保存信息的最简单的方法是通过 Feed exports,命令如下:</p> <pre><code class="language-ruby"><code class="lang-bash" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;"><span class="hljs-variable">$ </span>scrapy crawl dmoz -o items.json -t json </code></code></pre> <p>除了 json 格式之外,还支持 JSON lines、CSV、XML格式,你也可以通过接口扩展一些格式。</p> <p>对于小项目用这种方法也足够了。如果是比较复杂的数据的话可能就需要编写一个 Item Pipeline 进行处理了。</p> <p>所有抓取的 items 将以 JSON 格式被保存在新生成的 items.json 文件中</p> <h2 id="articleHeader17" style="font-family:inherit;line-height:1.2;color:inherit;font-size:1.42857em;border-bottom-width:1px;border-bottom-style:dotted;border-bottom-color:rgb(204,204,204);"> 总结</h2> <p>上面描述了如何创建一个爬虫项目的过程,你可以参照上面过程联系一遍。作为学习的例子,你还可以参考这篇文章:scrapy 中文教程(爬cnbeta实例) 。</p> <p>这篇文章中的爬虫类代码如下:</p> <pre><code class="language-python"><code class="lang-python" style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:1em;color:inherit;"><span class="hljs-keyword" style="font-weight:bold;">from</span> scrapy.contrib.spiders <span class="hljs-keyword" style="font-weight:bold;">import</span> CrawlSpider, Rule <span class="hljs-keyword" style="font-weight:bold;">from</span> scrapy.contrib.linkextractors.sgml <span class="hljs-keyword" style="font-weight:bold;">import</span> SgmlLinkExtractor <span class="hljs-keyword" style="font-weight:bold;">from</span> scrapy.selector <span class="hljs-keyword" style="font-weight:bold;">import</span> Selector <span class="hljs-keyword" style="font-weight:bold;">from</span> cnbeta.items <span class="hljs-keyword" style="font-weight:bold;">import</span> CnbetaItem <span class="hljs-class"><span class="hljs-keyword" style="font-weight:bold;">class</span> <span class="hljs-title" style="color:rgb(136,0,0);font-weight:bold;">CBSpider</span><span class="hljs-params">(CrawlSpider)</span>:</span> name = <span class="hljs-string" style="color:rgb(136,0,0);">'cnbeta'</span> allowed_domains = [<span class="hljs-string" style="color:rgb(136,0,0);">'cnbeta.com'</span>] start_urls = [<span class="hljs-string" style="color:rgb(136,0,0);">'http://www.cnbeta.com'</span>] rules = ( Rule(SgmlLinkExtractor(allow=(<span class="hljs-string" style="color:rgb(136,0,0);">'/articles/.*\.htm'</span>, )), callback=<span class="hljs-string" style="color:rgb(136,0,0);">'parse_page'</span>, follow=<span class="hljs-keyword" style="font-weight:bold;">True</span>), ) <span class="hljs-function"><span class="hljs-keyword" style="font-weight:bold;">def</span> <span class="hljs-title" style="color:rgb(136,0,0);font-weight:bold;">parse_page</span><span class="hljs-params">(self, response)</span>:</span> item = CnbetaItem() sel = Selector(response) item[<span class="hljs-string" style="color:rgb(136,0,0);">'title'</span>] = sel.xpath(<span class="hljs-string" style="color:rgb(136,0,0);">'//title/text()'</span>).extract() item[<span class="hljs-string" style="color:rgb(136,0,0);">'url'</span>] = response.url <span class="hljs-keyword" style="font-weight:bold;">return</span> item </code></code></pre> <p>需要说明的是:</p> <ul> <li>该爬虫类继承的是 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">CrawlSpider</code> 类,并且定义规则,rules指定了含有 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">/articles/.*\.htm</code> 的链接都会被匹配。</li> <li>该类并没有实现parse方法,并且规则中定义了回调函数 <code style="font-family:Consolas, Menlo, Monaco, 'Courier New', monospace;font-size:.92857em;color:rgb(199,37,78);">parse_page</code>,你可以参考更多资料了解 CrawlSpider 的用法</li> </ul> <h1 id="articleHeader18" style="font-size:1.71429em;font-family:inherit;line-height:1.2;color:inherit;border-bottom-width:2px;border-bottom-style:solid;border-bottom-color:rgb(221,221,221);"> 3. 学习资料</h1> <p>接触 Scrapy,是因为想爬取一些知乎的数据,最开始的时候搜索了一些相关的资料和别人的实现方式。</p> <p>Github 上已经有人或多或少的实现了对知乎数据的爬取,我搜索到的有以下几个仓库:</p> <ul> <li>https://github.com/KeithYue/Zhihu_Spider 实现先通过用户名和密码登陆再爬取数据,代码见 zhihu_spider.py。</li> <li>https://github.com/immzz/zhihu-scrapy 使用 selenium 下载和执行 javascript 代码。</li> <li>https://github.com/tangerinewhite32/zhihu-stat-py</li> <li>https://github.com/Zcc/zhihu 主要是爬指定话题的topanswers,还有用户个人资料,添加了登录代码。</li> <li>https://github.com/pelick/VerticleSearchEngine 基于爬取的学术资源,提供搜索、推荐、可视化、分享四块。使用了 Scrapy、MongoDB、Apache Lucene/Solr、Apache Tika等技术。</li> <li>https://github.com/geekan/scrapy-examples scrapy的一些例子,包括获取豆瓣数据、linkedin、腾讯招聘数据等例子。</li> <li>https://github.com/owengbs/deeplearning 实现分页获取话题。</li> <li>https://github.com/gnemoug/distribute_crawler 使用scrapy、redis、mongodb、graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现</li> <li>https://github.com/weizetao/spider-roach 一个分布式定向抓取集群的简单实现。</li> </ul> <p>其他资料:</p> <ul> <li>http://www.52ml.net/tags/Scrapy 收集了很多关于 Scrapy 的文章,<span>推荐阅读</span></li> <li>用Python Requests抓取知乎用户信息</li> <li>使用scrapy框架爬取自己的博文</li> <li>Scrapy 深入一点点</li> <li>使用python,scrapy写(定制)爬虫的经验,资料,杂。</li> <li>Scrapy 轻松定制网络爬虫</li> <li>在scrapy中怎么让Spider自动去抓取豆瓣小组页面</li> </ul> <p>scrapy 和 javascript 交互例子:</p> <ul> <li>用scrapy框架爬取js交互式表格数据</li> <li>scrapy + selenium 解析javascript 实例</li> </ul> <p>还有一些待整理的知识点:</p> <ul> <li><span>如何先登陆再爬数据</span></li> <li><span>如何使用规则做过滤</span></li> <li><span>如何递归爬取数据</span></li> <li><span>scrapy的参数设置和优化</span></li> <li><span>如何实现分布式爬取</span></li> </ul> <h1 id="articleHeader19" style="font-size:1.71429em;font-family:inherit;line-height:1.2;color:inherit;border-bottom-width:2px;border-bottom-style:solid;border-bottom-color:rgb(221,221,221);"> 4. 总结</h1> <p>以上就是最近几天学习 Scrapy 的一个笔记和知识整理,参考了一些网上的文章才写成此文,对此表示感谢,也希望这篇文章能够对你有所帮助。如果你有什么想法,欢迎留言;如果喜欢此文,请帮忙分享,谢谢!</p> <p><span style="line-height:22.3999996185303px;">原文发表于:</span>http://blog.javachen.com/2014/05/24/using-scrapy-to-cralw-data/</p> </div> </div> </div> </div> </div> </div> <!--PC和WAP自适应版--> <div id="SOHUCS" sid="1275238086510395392"></div> <script type="text/javascript" src="/views/front/js/chanyan.js"></script> <!-- 文章页-底部 动态广告位 --> <div class="youdao-fixed-ad" id="detail_ad_bottom"></div> </div> <div class="col-md-3"> <div class="row" id="ad"> <!-- 文章页-右侧1 动态广告位 --> <div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_1"> </div> </div> <!-- 文章页-右侧2 动态广告位 --> <div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_2"></div> </div> <!-- 文章页-右侧3 动态广告位 --> <div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_3"></div> </div> </div> </div> </div> </div> </div> <div class="container"> <h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(分布式采集)</h4> <div id="paradigm-article-related"> <div class="recommend-post mb30"> <ul class="widget-links"> <li><a href="/article/1947099756517978112.htm" title="数据并表技术全面指南:从基础JOIN到分布式数据融合" target="_blank">数据并表技术全面指南:从基础JOIN到分布式数据融合</a> <span class="text-muted">熊猫钓鱼>_></span> <a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a> <div>引言在现代数据处理和分析领域,数据并表(TableJoin)技术是连接不同数据源、整合分散信息的核心技术。随着企业数据规模的爆炸式增长和数据源的日益多样化,传统的数据并表方法面临着前所未有的挑战:性能瓶颈、内存限制、数据倾斜、一致性问题等。如何高效、准确地进行大规模数据并表,已成为数据工程师和架构师必须掌握的关键技能。数据并表不仅仅是简单的SQLJOIN操作,它涉及数据建模、算法优化、分布式计算、</div> </li> <li><a href="/article/1947094084153831424.htm" title="filebeat改造支持rocketmq" target="_blank">filebeat改造支持rocketmq</a> <span class="text-muted">余很多之很多</span> <a class="tag" taget="_blank" href="/search/go/1.htm">go</a><a class="tag" taget="_blank" href="/search/Java/1.htm">Java</a><a class="tag" taget="_blank" href="/search/rocketmq/1.htm">rocketmq</a> <div>继续分享下以前在gitchat上发布的文章:filebeat改造支持rocketmq1.概述1.1问题概述现在越来越多的日志采集使用FileBeat,FileBeat是个轻量型日志采集器,采用Go语言实现,性能稳健,占用资源少。FileBeat现在支持采集的日志内容发送到Redis、Elasticsearch、Kafka、Logstash。那么我们如果想通过FileBeat采集日志到RocketM</div> </li> <li><a href="/article/1947074417339199488.htm" title="手持激光雷达单木分割——以河南工程学院杰出校友杨靖宇将军雕塑背后树林为例" target="_blank">手持激光雷达单木分割——以河南工程学院杰出校友杨靖宇将军雕塑背后树林为例</a> <span class="text-muted">河工点云智绘WangG</span> <a class="tag" taget="_blank" href="/search/%E6%B2%B3%E5%B7%A5%E7%82%B9%E4%BA%91%E6%99%BA%E7%BB%98/1.htm">河工点云智绘</a><a class="tag" taget="_blank" href="/search/%E6%95%99%E8%82%B2%E5%9F%B9%E8%AE%AD/1.htm">教育培训</a> <div>教学相长,最近带学生激光雷达实习,采集了河南工程学院校园机载、车载和手持激光雷达数据,针对手持激光雷达,也来玩玩单木分割。一、手持激光雷达单木分割概念单木分割(IndividualTreeSegmentation)是从激光雷达(LiDAR)点云数据中识别并分离出单棵树木的过程,是林业资源调查、森林碳汇估算、生物多样性研究的关键技术。二、关键技术步骤详解1.点云预处理去噪:移除飞点、鸟群等非地表物体</div> </li> <li><a href="/article/1947073658837069824.htm" title="Apache Kafka 学习笔记" target="_blank">Apache Kafka 学习笔记</a> <span class="text-muted"></span> <div>一、Kafka简介1.1Kafka是什么?Kafka是一个高吞吐、可扩展、分布式的消息发布-订阅系统,主要用于:日志收集与处理流式数据处理事件驱动架构实时分析管道最初由LinkedIn开发,后捐赠给Apache基金会。1.2Kafka的核心特性特性描述高吞吐每秒百万级消息处理能力,依赖顺序写磁盘、批量处理分布式支持水平扩展,多个Broker组成集群持久化消息写入磁盘(通过segmentfiles+</div> </li> <li><a href="/article/1947071385750794240.htm" title="Git remote 远程仓库链接管理" target="_blank">Git remote 远程仓库链接管理</a> <span class="text-muted">迹忆客</span> <a class="tag" taget="_blank" href="/search/Linux/1.htm">Linux</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E7%AB%AF/1.htm">服务端</a><a class="tag" taget="_blank" href="/search/git/1.htm">git</a> <div>SVN使用单个集中仓库作为开发人员的通信枢纽,通过在开发人员的工作副本和中央仓库之间传递变更集来进行协作。这与Git的分布式协作模型不同,后者为每个开发人员提供了自己的仓库副本,并具有自己的本地历史记录和分支结构。用户通常需要共享一系列提交而不是单个变更集。Git允许我们在仓库之间共享整个分支,而不是将变更集从工作副本提交到中央仓库。gitremote命令是负责同步更改的更广泛系统的一部分。通过g</div> </li> <li><a href="/article/1947052316045668352.htm" title="【im】如何解决消息的实时到达问题?" target="_blank">【im】如何解决消息的实时到达问题?</a> <span class="text-muted">Bogon</span> <div>TCP长连接的方式是怎么实现“当有消息需要发送给某个用户时,能够准确找到这个用户对应的网络连接”?首先用户有一个登陆的过程:(1)tcp客户端与服务端通过三次握手建立tcp连接;(2)基于该连接客户端发送登陆请求;(3)服务端对登陆请求进行解析和判断,如果合法,就将当前用户的uid和标识当前tcp连接的socket描述符(也就是fd)建立映射关系;(4)这个映射关系一般是保存在本地缓存或分布式缓存</div> </li> <li><a href="/article/1947046037310992384.htm" title="大模型算法工程师技术路线全解析:从基础到资深的能力跃迁" target="_blank">大模型算法工程师技术路线全解析:从基础到资深的能力跃迁</a> <span class="text-muted">Mr.小海</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%A8%A1%E5%9E%8B/1.htm">大模型</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98/1.htm">数据挖掘</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E7%BF%BB%E8%AF%91/1.htm">机器翻译</a><a class="tag" taget="_blank" href="/search/web3/1.htm">web3</a> <div>文章目录大模型算法工程师技术路线全解析:从基础到资深的能力跃迁一、基础阶段(0-2年经验):构建核心知识体系与工程入门数学与机器学习基础编程与深度学习框架NLP与Transformer入门二、进阶阶段(2-4年经验):深化模型技术与工程落地能力大模型预训练与微调技术预训练原理:数据与任务的协同设计微调工具:参数高效适配与工程优化对齐实践:价值观优化与实证效果分布式训练与框架工具并行策略:多维度协同</div> </li> <li><a href="/article/1947042003808219136.htm" title="Python爬虫实战:从新浪财经爬取股票新闻的完整实现" target="_blank">Python爬虫实战:从新浪财经爬取股票新闻的完整实现</a> <span class="text-muted">Python爬虫项目</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90/1.htm">数据分析</a><a class="tag" taget="_blank" href="/search/php/1.htm">php</a> <div>第一部分:爬虫概述1.1什么是爬虫?爬虫是指通过程序模拟浏览器的行为,自动化地抓取网络上的数据。通过爬虫技术,能够从各种网站上提取信息,广泛应用于数据采集、数据分析、机器学习等领域。1.2新浪财经简介新浪财经是中国最大的财经信息平台之一,提供股票、基金、债券、外汇等多方面的财经新闻和数据。在股票领域,新浪财经提供了大量的股票行情、实时数据、新闻报道等信息,因此爬取新浪财经的股票新闻对于投资分析和决</div> </li> <li><a href="/article/1947039231469744128.htm" title="AI 智能运维,重塑大型企业软件运维:从自动化到智能化的进阶实践" target="_blank">AI 智能运维,重塑大型企业软件运维:从自动化到智能化的进阶实践</a> <span class="text-muted">AI、少年郎</span> <a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E5%8A%A8%E5%8C%96/1.htm">自动化</a> <div>一、引言:企业软件运维的智能化转型浪潮在数字化转型加速的背景下,大型企业软件架构日益复杂,微服务、多云环境、分布式系统的普及导致传统运维模式面临效率瓶颈。AI技术的渗透催生了智能运维(AIOps)的落地,通过机器学习、大模型、智能Agent等技术,实现从"人工救火"到"智能预防"的范式转变。本文结合头部企业实践,解析AI在运维领域的核心应用场景、技术架构及未来趋势,特别针对基础运维中流程重构、技术</div> </li> <li><a href="/article/1947031538021494784.htm" title="前端面试专栏-工程化:28.团队协作与版本控制(Git)" target="_blank">前端面试专栏-工程化:28.团队协作与版本控制(Git)</a> <span class="text-muted">爱分享的程序员</span> <a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF%E9%9D%A2%E8%AF%95%E9%80%9A%E5%85%B3%E6%8C%87%E5%8D%97/1.htm">前端面试通关指南</a><a class="tag" taget="_blank" href="/search/node.js/1.htm">node.js</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a> <div>欢迎来到前端面试通关指南专栏!从js精讲到框架到实战,渐进系统化学习,坚持解锁新技能,祝你轻松拿下心仪offer。前端面试通关指南专栏主页前端面试专栏规划详情项目实战与工程化模块-团队协作与版本控制(Git)在多人协作的项目中,代码的版本管理是保障开发效率与代码质量的核心环节。Git作为目前最流行的分布式版本控制系统,不仅能追踪代码变更历史,更能通过分支策略、协作流程规范团队工作方式。本文从实战角</div> </li> <li><a href="/article/1947029770957025280.htm" title="Windows平台下的Git版本控制实践:msysGit安装与使用" target="_blank">Windows平台下的Git版本控制实践:msysGit安装与使用</a> <span class="text-muted"></span> <div>本文还有配套的精品资源,点击获取简介:msysGit是为Windows系统打造的Git版本控制系统,它允许用户在本地环境中方便地使用Git进行源代码管理和版本控制。Git是一个分布式版本控制系统,以其快速、高效和灵活性著称。msysGit通过模拟Unix-like环境来兼容Git命令,并提供图形界面工具和与Windows集成的特性,极大地提升了Windows用户的操作体验。本文将详细介绍msysG</div> </li> <li><a href="/article/1947027627025952768.htm" title="Kafka 集群架构与高可用方案设计(一)" target="_blank">Kafka 集群架构与高可用方案设计(一)</a> <span class="text-muted">计算机毕设定制辅导-无忧</span> <a class="tag" taget="_blank" href="/search/%23/1.htm">#</a><a class="tag" taget="_blank" href="/search/Kafka/1.htm">Kafka</a><a class="tag" taget="_blank" href="/search/kafka/1.htm">kafka</a><a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a> <div>Kafka集群架构与高可用方案设计的重要性在大数据和分布式系统的广阔领域中,Kafka已然成为了一个中流砥柱般的存在。它最初由LinkedIn开发,后捐赠给Apache软件基金会并成为顶级项目,凭借其卓越的高吞吐量、可扩展性以及持久性,被广泛应用于日志收集、实时数据处理、流计算、数据集成等诸多关键领域。在日志收集场景下,以大型互联网公司为例,每天都会产生海量的日志数据,如用户的访问记录、系统操作日</div> </li> <li><a href="/article/1947017904859967488.htm" title="2024 年度分布式电力推进(DEP)系统发展探究" target="_blank">2024 年度分布式电力推进(DEP)系统发展探究</a> <span class="text-muted">北京航通天下科技有限公司</span> <a class="tag" taget="_blank" href="/search/%E6%97%A0%E4%BA%BA%E6%9C%BA%E6%B5%8B%E8%AF%95%E6%95%99%E5%AD%A6%E5%9F%B9%E8%AE%AD/1.htm">无人机测试教学培训</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F%E7%94%B5%E6%8E%A8%E8%BF%9B%28DEP%29%E5%8A%A8%E5%8A%9B%E7%B3%BB%E7%BB%9F/1.htm">分布式电推进(DEP)动力系统</a><a class="tag" taget="_blank" href="/search/%E6%97%A0%E4%BA%BA%E6%9C%BA%E5%8A%A8%E5%8A%9B%E6%B5%8B%E8%AF%95%E7%B3%BB%E7%BB%9F/1.htm">无人机动力测试系统</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F%E7%94%B5%E6%8E%A8%E8%BF%9B%E6%8A%80%E6%9C%AF/1.htm">分布式电推进技术</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F%E5%8A%A8%E5%8A%9B%E7%B3%BB%E7%BB%9F%E6%B5%8B%E8%AF%95%E5%B9%B3%E5%8F%B0/1.htm">分布式动力系统测试平台</a><a class="tag" taget="_blank" href="/search/DEP/1.htm">DEP</a> <div>分布式电力推进(DEP)的发明是为了尝试和改进现代飞机:我们如何提高飞机的效率?提高它的机动性?缩短它的起飞和着陆距离?DEP概念有望在提高性能的同时减少燃料消耗,在我们孜孜不倦地努力使航空业更具可持续性的时代,这是一个有吸引力的前景。在本文中,我们将介绍DEP的工作原理、优缺点以及值得关注的DEP飞机。此外,我们还提供用于测试DEP系统的解决方案。所有内容都包括在下面。目录什么是分布式电力推进(</div> </li> <li><a href="/article/1947009837644705792.htm" title="eVTOL分布式电推进(DEP)适航审定探究" target="_blank">eVTOL分布式电推进(DEP)适航审定探究</a> <span class="text-muted">北京航通天下科技有限公司</span> <a class="tag" taget="_blank" href="/search/%E4%BD%8E%E7%A9%BA%E7%BB%8F%E6%B5%8E/1.htm">低空经济</a><a class="tag" taget="_blank" href="/search/eVTOL%E6%B5%8B%E8%AF%95%E9%85%8D%E5%A5%97/1.htm">eVTOL测试配套</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a> <div>从适航认证的角度来看,eVTOL动力系统采用分布式电推进(DEP)技术进行测试具有以下显著优势:一、提升系统冗余性与故障容限分布式电推进系统通过多个独立电机协同工作,即使部分电机失效,剩余电机仍能维持推力,保障飞行安全。这种冗余设计是适航认证中对关键系统可靠性要求的核心指标之一。例如,测试平台可模拟单个或多个电机故障场景,验证系统能否通过动态推力分配维持稳定飞行,从而满足适航对“故障安全”原则的要</div> </li> <li><a href="/article/1947005426516160512.htm" title="灰度发布实战:在生产环境中安全迭代功能" target="_blank">灰度发布实战:在生产环境中安全迭代功能</a> <span class="text-muted">荣华富贵8</span> <a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9A%84%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%872/1.htm">程序员的知识储备2</a><a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98%E7%9A%84%E7%9F%A5%E8%AF%86%E5%82%A8%E5%A4%873/1.htm">程序员的知识储备3</a><a class="tag" taget="_blank" href="/search/consul/1.htm">consul</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%8F%91%E7%8E%B0/1.htm">服务发现</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/wpf/1.htm">wpf</a> <div>摘要随着互联网服务规模的不断扩大,如何在保证系统稳定性和用户体验的前提下快速迭代新功能,已经成为大型分布式系统运维和开发团队面临的核心挑战。灰度发布(GreyRelease或CanaryRelease)作为一种渐进式发布策略,通过对少量用户或流量进行新版本试运行,实时监控关键指标、收集用户反馈,从而在生产环境中实现安全的功能迭代和风险管控。本文以某大型电商平台灰度发布实战为例,深入探讨技术原理、系</div> </li> <li><a href="/article/1947005298862518272.htm" title="电阻信号的含义与采集" target="_blank">电阻信号的含义与采集</a> <span class="text-muted">、我是男生。</span> <a class="tag" taget="_blank" href="/search/%E5%8D%95%E7%89%87%E6%9C%BA/1.htm">单片机</a><a class="tag" taget="_blank" href="/search/%E5%B5%8C%E5%85%A5%E5%BC%8F%E7%A1%AC%E4%BB%B6/1.htm">嵌入式硬件</a> <div>一、什么是“电阻信号”?严谨性探讨严格定义:在传感器与测量领域,“电阻信号”特指一个物理量(如温度、压力、应变、光照)的变化,导致某个敏感元件的电阻值(R)发生可测量的改变。这个变化的电阻值ΔR(或R)本身就是待测物理量的载体。为什么说“信号”?因为这个变化的电阻值ΔR包含了我们需要的信息(如压力多大、温度多高)。严谨性点评:你使用“电阻信号”一词完全准确且专业。这是传感器领域的标准术语(例如:R</div> </li> <li><a href="/article/1946996477180047360.htm" title="基于STM32单片机车牌识别系统摄像头图像处理设计的论文" target="_blank">基于STM32单片机车牌识别系统摄像头图像处理设计的论文</a> <span class="text-muted">weixin_112233</span> <a class="tag" taget="_blank" href="/search/%E5%8D%95%E7%89%87%E6%9C%BA/1.htm">单片机</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E7%89%87%E6%9C%BA/1.htm">单片机</a><a class="tag" taget="_blank" href="/search/stm32/1.htm">stm32</a><a class="tag" taget="_blank" href="/search/%E5%9B%BE%E5%83%8F%E5%A4%84%E7%90%86/1.htm">图像处理</a> <div>摘要本设计提出了一种基于32单片机的车牌识别系统摄像头图像处理方案。该系统主要由STM32F103RCT6单片机核心板、2.8寸TFT液晶屏显示、摄像头图像采集OV7670、蜂鸣器以及LED电路组成。在车牌识别过程中,STM32F103RCT6单片机核心板发挥着关键的控制作用。摄像头图像采集OV7670负责获取车辆的图像信息,能够清晰地捕捉车牌区域。采集到的图像数据传输至单片机进行处理,通过一系列</div> </li> <li><a href="/article/1946989291984973824.htm" title="基于Python的Google Patents专利数据爬取实战:从入门到精通" target="_blank">基于Python的Google Patents专利数据爬取实战:从入门到精通</a> <span class="text-muted">Python爬虫项目</span> <a class="tag" taget="_blank" href="/search/2025%E5%B9%B4%E7%88%AC%E8%99%AB%E5%AE%9E%E6%88%98%E9%A1%B9%E7%9B%AE/1.htm">2025年爬虫实战项目</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/scrapy/1.htm">scrapy</a><a class="tag" taget="_blank" href="/search/selenium/1.htm">selenium</a> <div>摘要本文将详细介绍如何使用Python构建一个高效的GooglePatents专利爬虫,涵盖最新技术如Playwright浏览器自动化、异步请求处理、反反爬策略等。文章包含完整的代码实现、性能优化技巧以及数据处理方法,帮助读者全面掌握专利数据采集技术。1.引言在当今知识经济时代,专利数据已成为企业技术研发、市场竞争分析的重要资源。GooglePatents作为全球最大的专利数据库之一,收录了来自全</div> </li> <li><a href="/article/1946966099799109632.htm" title="《[系统底层攻坚] 张冬〈大话存储终极版〉精读计划启动——存储架构原理深度拆解之旅》-系统性学习笔记(适合小白与IT工作人员)" target="_blank">《[系统底层攻坚] 张冬〈大话存储终极版〉精读计划启动——存储架构原理深度拆解之旅》-系统性学习笔记(适合小白与IT工作人员)</a> <span class="text-muted">谢郎Kobe</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%B4%BB%E5%AD%98%E5%82%A8/1.htm">大活存储</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a><a class="tag" taget="_blank" href="/search/%E4%BA%91%E8%AE%A1%E7%AE%97/1.htm">云计算</a><a class="tag" taget="_blank" href="/search/%E7%A1%AC%E4%BB%B6%E6%9E%B6%E6%9E%84/1.htm">硬件架构</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a> <div>致所有存储技术探索者笔者近期将系统攻克存储领域经典巨作——张冬老师编著的《大话存储终极版》。这部近千页的存储系统圣经,以庖丁解牛的方式剖析了:存储硬件底层架构、分布式存储核心算法、超融合系统设计哲学等等。喜欢研究数据存储或者工作应用到存储的小伙伴,可以学习这本书。如果想利用碎片时间学习,也可以持续关注一下笔者不定期的章节解析。现在本人将此书的目录结构整理如下,未来笔者将按照顺序不定期更新【学习笔记</div> </li> <li><a href="/article/1946956138884952064.htm" title="Java 大视界 -- Java 大数据机器学习模型在金融市场情绪分析与投资策略制定中的应用" target="_blank">Java 大视界 -- Java 大数据机器学习模型在金融市场情绪分析与投资策略制定中的应用</a> <span class="text-muted">青云交</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%96%B0%E8%A7%86%E7%95%8C/1.htm">大数据新视界</a><a class="tag" taget="_blank" href="/search/Java/1.htm">Java</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E8%A7%86%E7%95%8C/1.htm">大视界</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/%E6%83%85%E7%BB%AA%E5%88%86%E6%9E%90/1.htm">情绪分析</a><a class="tag" taget="_blank" href="/search/%E6%99%BA%E8%83%BD%E6%8A%95%E8%B5%84/1.htm">智能投资</a><a class="tag" taget="_blank" href="/search/%E5%A4%9A%E6%BA%90%E6%95%B0%E6%8D%AE/1.htm">多源数据</a> <div>Java大视界--Java大数据机器学习模型在金融市场情绪分析与投资策略制定中的应用)引言:正文:一、金融情绪数据的立体化采集与治理1.1多模态数据采集架构1.2数据治理与特征工程二、Java机器学习模型的工程化实践2.1情感分析模型的深度优化2.2强化学习驱动的动态投资策略三、顶级机构实战:Java系统的金融炼金术四、技术前沿:Java与金融科技的未来融合4.1量子机器学习集成4.2联邦学习在合</div> </li> <li><a href="/article/1946956136779411456.htm" title="Java 大视界 -- 基于 Java 的大数据分布式文件系统在科研数据存储与共享中的应用优化(187)" target="_blank">Java 大视界 -- 基于 Java 的大数据分布式文件系统在科研数据存储与共享中的应用优化(187)</a> <span class="text-muted">青云交</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%96%B0%E8%A7%86%E7%95%8C/1.htm">大数据新视界</a><a class="tag" taget="_blank" href="/search/Java/1.htm">Java</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E8%A7%86%E7%95%8C/1.htm">大视界</a><a class="tag" taget="_blank" href="/search/Java%2BPython/1.htm">Java+Python</a><a class="tag" taget="_blank" href="/search/%E5%8F%8C%E5%89%91%E5%90%88%E7%92%A7%EF%BC%9AAI/1.htm">双剑合璧:AI</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AE%9E%E6%88%98%E9%80%9A%E5%85%B3%E7%A7%98%E7%B1%8D/1.htm">大数据实战通关秘籍</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%88%86%E5%B8%83%E5%BC%8F%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F/1.htm">大数据分布式文件系统</a><a class="tag" taget="_blank" href="/search/%E7%A7%91%E7%A0%94%E6%95%B0%E6%8D%AE%E5%AD%98%E5%82%A8/1.htm">科研数据存储</a><a class="tag" taget="_blank" href="/search/%E7%A7%91%E7%A0%94%E6%95%B0%E6%8D%AE%E5%85%B1%E4%BA%AB/1.htm">科研数据共享</a><a class="tag" taget="_blank" href="/search/%E5%BA%94%E7%94%A8%E4%BC%98%E5%8C%96/1.htm">应用优化</a><a class="tag" taget="_blank" href="/search/HDFS/1.htm">HDFS</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%88%86%E5%8C%BA/1.htm">数据分区</a> <div>亲爱的朋友们,热烈欢迎来到青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而我的博客正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!全网(微信公众号/CSDN/抖音/华为/支付宝/微博):青云交一、欢迎加入【福利社群】点击快速加入1:青云交技术圈福利社群(NEW)点击快速加入2:CSDN博客</div> </li> <li><a href="/article/1946953613163163648.htm" title="Python爬虫【二十四章】分布式爬虫架构实战:Scrapy-Redis亿级数据抓取方案设计" target="_blank">Python爬虫【二十四章】分布式爬虫架构实战:Scrapy-Redis亿级数据抓取方案设计</a> <span class="text-muted">程序员_CLUB</span> <a class="tag" taget="_blank" href="/search/Python%E5%85%A5%E9%97%A8%E5%88%B0%E8%BF%9B%E9%98%B6/1.htm">Python入门到进阶</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a> <div>目录一、背景:单机爬虫的五大瓶颈二、Scrapy-Redis架构深度解析1.架构拓扑图2.核心组件对比三、环境搭建与核心配置1.基础环境部署2.Scrapy项目配置四、分布式爬虫核心实现1.改造原生Spider2.布隆过滤器集成五、五大性能优化策略1.动态优先级调整2.智能限速策略3.连接池优化4.数据分片存储5.心跳监控系统六、实战:新闻聚合平台数据抓取1.集群架构2.性能指标七、总结1.核心收</div> </li> <li><a href="/article/1946951088544477184.htm" title="分布式爬虫:设计一个分布式爬虫架构来抓取大规模数据" target="_blank">分布式爬虫:设计一个分布式爬虫架构来抓取大规模数据</a> <span class="text-muted">Python爬虫项目</span> <a class="tag" taget="_blank" href="/search/2025%E5%B9%B4%E7%88%AC%E8%99%AB%E5%AE%9E%E6%88%98%E9%A1%B9%E7%9B%AE/1.htm">2025年爬虫实战项目</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/%E6%B5%8B%E8%AF%95%E5%B7%A5%E5%85%B7/1.htm">测试工具</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>✨引言随着互联网信息的爆炸式增长,单机爬虫面对大规模网站数据抓取显得力不从心。特别是爬取新闻、商品、社交平台等网站时,经常遇到响应慢、IP被封等问题。为了解决这些问题,分布式爬虫系统应运而生。在本文中,我们将手把手带你打造一个基于Scrapy+Redis+Celery+FastAPI+Docker的现代分布式爬虫架构,实现任务调度、去重控制、分布式抓取与结果存储。本文代码均基于Python3.10</div> </li> <li><a href="/article/1946951089626607616.htm" title="Python医疗大数据实战:基于Scrapy-Redis的医院评价数据分布式爬虫设计与实现" target="_blank">Python医疗大数据实战:基于Scrapy-Redis的医院评价数据分布式爬虫设计与实现</a> <span class="text-muted">Python爬虫项目</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/selenium/1.htm">selenium</a><a class="tag" taget="_blank" href="/search/scrapy/1.htm">scrapy</a> <div>摘要本文将详细介绍如何使用Python构建一个高效的医院评价数据爬虫系统。我们将从爬虫基础讲起,逐步深入到分布式爬虫架构设计,使用Scrapy框架结合Redis实现分布式爬取,并采用最新的反反爬技术确保数据采集的稳定性。文章包含完整的代码实现、性能优化方案以及数据处理方法,帮助读者掌握医疗大数据采集的核心技术。关键词:Python爬虫、Scrapy-Redis、分布式爬虫、医疗大数据、反反爬技术1</div> </li> <li><a href="/article/1946950773388668928.htm" title="互联网架构“高并发”" target="_blank">互联网架构“高并发”</a> <span class="text-muted">极课编程</span> <div>一、什么是高并发高并发(HighConcurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。高并发相关常用的一些指标有响应时间(ResponseTime),吞吐量(Throughput),每秒查询率QPS(QueryPerSecond),并发用户数等。响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这</div> </li> <li><a href="/article/1946950457867956224.htm" title="分布式爬虫架构:Scrapy-Redis+Redis集群实现百万级数据采集" target="_blank">分布式爬虫架构:Scrapy-Redis+Redis集群实现百万级数据采集</a> <span class="text-muted">傻啦嘿哟</span> <a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a> <div>目录当单机爬虫遇到百万数据量架构设计核心原理分布式任务调度弹性去重机制Redis集群部署实践集群规模计算高可用配置Scrapy项目改造分布式爬虫编写百万级数据优化策略流量控制机制动态IP代理数据存储优化实战案例分析监控与维护集群健康检查日志分析架构演进方向当单机爬虫遇到百万数据量想象你正在搭建一个电商价格监控系统,需要每天抓取十万条商品数据。使用传统Scrapy框架时,单台服务器每天最多只能处理3</div> </li> <li><a href="/article/1946934030347857920.htm" title="Kafka面试问题1" target="_blank">Kafka面试问题1</a> <span class="text-muted">小小少年Boy</span> <div>1请说明什么是ApacheKafka?Kafka是分布式发布-订阅消息系统。Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。它可以同时用于在线消息数据处理,和离线的数据文件处理。2、请说明什么是传统的消息传递方法?传统的消息传递方法包括两种:排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。发布-订阅:在这个模型中,消息被广播</div> </li> <li><a href="/article/1946928928266448896.htm" title="组件分享之后端组件——基于Java的分布式系统的延迟和容错组件(熔断组件)Hystrix" target="_blank">组件分享之后端组件——基于Java的分布式系统的延迟和容错组件(熔断组件)Hystrix</a> <span class="text-muted">cn華少</span> <div>组件分享之后端组件——基于Java的分布式系统的延迟和容错组件(熔断组件)Hystrix背景近期正在探索前端、后端、系统端各类常用组件与工具,对其一些常见的组件进行再次整理一下,形成标准化组件专题,后续该专题将包含各类语言中的一些常用组件。欢迎大家进行持续关注。组件基本信息组件:Hystrix开源协议:LICENSE内容本节我们分享一个基于Java的分布式系统的延迟和容错组件(熔断组件)Hystr</div> </li> <li><a href="/article/1946922847838466048.htm" title="人脸识别:AI 如何精准 “认人”?" target="_blank">人脸识别:AI 如何精准 “认人”?</a> <span class="text-muted">田园Coder</span> <a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E7%A7%91%E6%99%AE/1.htm">人工智能科普</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E7%A7%91%E6%99%AE/1.htm">科普</a> <div>1.人脸识别的基本原理:从“看到脸”到“认出人”1.1什么是人脸识别技术人脸识别是基于人的面部特征信息进行身份认证的生物识别技术。它通过摄像头采集人脸图像,利用AI算法提取面部特征(如眼距、鼻梁高度、下颌轮廓等),再与数据库中的模板比对,最终判断“是否为同一个人”。与指纹识别、虹膜识别等生物识别技术相比,人脸识别的优势在于“非接触性”(无需触碰设备)和“自然性”(符合人类习惯,如刷脸支付无需额外操</div> </li> <li><a href="/article/1946909603497308160.htm" title="我的架构梦:(五十三) 分库分表实战及中间件之ShardingSphere实战" target="_blank">我的架构梦:(五十三) 分库分表实战及中间件之ShardingSphere实战</a> <span class="text-muted">老周聊架构</span> <a class="tag" taget="_blank" href="/search/%E6%88%91%E7%9A%84%E6%9E%B6%E6%9E%84%E6%A2%A6/1.htm">我的架构梦</a> <div>上一篇:我的架构梦:(五十二)分库分表实战及中间件之实战背景分库分表实战及中间件之ShardingSphere实战二、ShardingSphere实战1、ShardingSphere2、Sharding-JDBC3、数据分片剖析实战5、强制路由剖析实战6、数据脱敏剖析实战7、分布式事务剖析实战8、SPI加载剖析9、编排治理剖析10、Sharding-Proxy实战二、ShardingSphere实</div> </li> <li><a href="/article/84.htm" title="继之前的线程循环加到窗口中运行" target="_blank">继之前的线程循环加到窗口中运行</a> <span class="text-muted">3213213333332132</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/thread/1.htm">thread</a><a class="tag" taget="_blank" href="/search/JFrame/1.htm">JFrame</a><a class="tag" taget="_blank" href="/search/JPanel/1.htm">JPanel</a> <div>之前写了有关java线程的循环执行和结束,因为想制作成exe文件,想把执行的效果加到窗口上,所以就结合了JFrame和JPanel写了这个程序,这里直接贴出代码,在窗口上运行的效果下面有附图。 package thread; import java.awt.Graphics; import java.text.SimpleDateFormat; import java.util</div> </li> <li><a href="/article/211.htm" title="linux 常用命令" target="_blank">linux 常用命令</a> <span class="text-muted">BlueSkator</span> <a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E5%91%BD%E4%BB%A4/1.htm">命令</a> <div>1.grep 相信这个命令可以说是大家最常用的命令之一了。尤其是查询生产环境的日志,这个命令绝对是必不可少的。 但之前总是习惯于使用 (grep -n 关键字 文件名 )查出关键字以及该关键字所在的行数,然后再用 (sed -n '100,200p' 文件名),去查出该关键字之后的日志内容。 但其实还有更简便的办法,就是用(grep -B n、-A n、-C n 关键</div> </li> <li><a href="/article/338.htm" title="php heredoc原文档和nowdoc语法" target="_blank">php heredoc原文档和nowdoc语法</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/heredoc/1.htm">heredoc</a><a class="tag" taget="_blank" href="/search/nowdoc/1.htm">nowdoc</a> <div><!doctype html> <html lang="en"> <head> <meta charset="utf-8"> <title>Current To-Do List</title> </head> <body> <?</div> </li> <li><a href="/article/465.htm" title="overflow的属性" target="_blank">overflow的属性</a> <span class="text-muted">周华华</span> <a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a> <div><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml&q</div> </li> <li><a href="/article/592.htm" title="《我所了解的Java》——总体目录" target="_blank">《我所了解的Java》——总体目录</a> <span class="text-muted">g21121</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a> <div> 准备用一年左右时间写一个系列的文章《我所了解的Java》,目录及内容会不断完善及调整。 在编写相关内容时难免出现笔误、代码无法执行、名词理解错误等,请大家及时指出,我会第一时间更正。 &n</div> </li> <li><a href="/article/719.htm" title="[简单]docx4j常用方法小结" target="_blank">[简单]docx4j常用方法小结</a> <span class="text-muted">53873039oycg</span> <a class="tag" taget="_blank" href="/search/docx/1.htm">docx</a> <div> 本代码基于docx4j-3.2.0,在office word 2007上测试通过。代码如下: import java.io.File; import java.io.FileInputStream; import ja</div> </li> <li><a href="/article/846.htm" title="Spring配置学习" target="_blank">Spring配置学习</a> <span class="text-muted">云端月影</span> <a class="tag" taget="_blank" href="/search/spring%E9%85%8D%E7%BD%AE/1.htm">spring配置</a> <div> 首先来看一个标准的Spring配置文件 applicationContext.xml <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi=&q</div> </li> <li><a href="/article/973.htm" title="Java新手入门的30个基本概念三" target="_blank">Java新手入门的30个基本概念三</a> <span class="text-muted">aijuans</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%96%B0%E6%89%8B/1.htm">新手</a><a class="tag" taget="_blank" href="/search/java+%E5%85%A5%E9%97%A8/1.htm">java 入门</a> <div>17.Java中的每一个类都是从Object类扩展而来的。 18.object类中的equal和toString方法。 equal用于测试一个对象是否同另一个对象相等。 toString返回一个代表该对象的字符串,几乎每一个类都会重载该方法,以便返回当前状态的正确表示.(toString 方法是一个很重要的方法) 19.通用编程:任何类类型的所有值都可以同object类性的变量来代替。 </div> </li> <li><a href="/article/1100.htm" title="《2008 IBM Rational 软件开发高峰论坛会议》小记" target="_blank">《2008 IBM Rational 软件开发高峰论坛会议》小记</a> <span class="text-muted">antonyup_2006</span> <a class="tag" taget="_blank" href="/search/%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95/1.htm">软件测试</a><a class="tag" taget="_blank" href="/search/%E6%95%8F%E6%8D%B7%E5%BC%80%E5%8F%91/1.htm">敏捷开发</a><a class="tag" taget="_blank" href="/search/%E9%A1%B9%E7%9B%AE%E7%AE%A1%E7%90%86/1.htm">项目管理</a><a class="tag" taget="_blank" href="/search/IBM/1.htm">IBM</a><a class="tag" taget="_blank" href="/search/%E6%B4%BB%E5%8A%A8/1.htm">活动</a> <div>我一直想写些总结,用于交流和备忘,然都没提笔,今以一篇参加活动的感受小记开个头,呵呵! 其实参加《2008 IBM Rational 软件开发高峰论坛会议》是9月4号,那天刚好调休.但接着项目颇为忙,所以今天在中秋佳节的假期里整理了下. 参加这次活动是一个朋友给的一个邀请书,才知道有这样的一个活动,虽然现在项目暂时没用到IBM的解决方案,但觉的参与这样一个活动可以拓宽下视野和相关知识.</div> </li> <li><a href="/article/1227.htm" title="PL/SQL的过程编程,异常,声明变量,PL/SQL块" target="_blank">PL/SQL的过程编程,异常,声明变量,PL/SQL块</a> <span class="text-muted">百合不是茶</span> <a class="tag" taget="_blank" href="/search/PL%2FSQL%E7%9A%84%E8%BF%87%E7%A8%8B%E7%BC%96%E7%A8%8B/1.htm">PL/SQL的过程编程</a><a class="tag" taget="_blank" href="/search/%E5%BC%82%E5%B8%B8/1.htm">异常</a><a class="tag" taget="_blank" href="/search/PL%2FSQL%E5%9D%97/1.htm">PL/SQL块</a><a class="tag" taget="_blank" href="/search/%E5%A3%B0%E6%98%8E%E5%8F%98%E9%87%8F/1.htm">声明变量</a> <div>PL/SQL; 过程; 符号; 变量; PL/SQL块; 输出; 异常; PL/SQL 是过程语言(Procedural Language)与结构化查询语言(SQL)结合而成的编程语言PL/SQL 是对 SQL 的扩展,sql的执行时每次都要写操作</div> </li> <li><a href="/article/1354.htm" title="Mockito(三)--完整功能介绍" target="_blank">Mockito(三)--完整功能介绍</a> <span class="text-muted">bijian1013</span> <a class="tag" taget="_blank" href="/search/%E6%8C%81%E7%BB%AD%E9%9B%86%E6%88%90/1.htm">持续集成</a><a class="tag" taget="_blank" href="/search/mockito/1.htm">mockito</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95/1.htm">单元测试</a> <div> mockito官网:http://code.google.com/p/mockito/,打开documentation可以看到官方最新的文档资料。 一.使用mockito验证行为 //首先要import Mockito import static org.mockito.Mockito.*; //mo</div> </li> <li><a href="/article/1481.htm" title="精通Oracle10编程SQL(8)使用复合数据类型" target="_blank">精通Oracle10编程SQL(8)使用复合数据类型</a> <span class="text-muted">bijian1013</span> <a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/plsql/1.htm">plsql</a> <div>/* *使用复合数据类型 */ --PL/SQL记录 --定义PL/SQL记录 --自定义PL/SQL记录 DECLARE TYPE emp_record_type IS RECORD( name emp.ename%TYPE, salary emp.sal%TYPE, dno emp.deptno%TYPE ); emp_</div> </li> <li><a href="/article/1608.htm" title="【Linux常用命令一】grep命令" target="_blank">【Linux常用命令一】grep命令</a> <span class="text-muted">bit1129</span> <a class="tag" taget="_blank" href="/search/Linux%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4/1.htm">Linux常用命令</a> <div>grep命令格式 grep [option] pattern [file-list] grep命令用于在指定的文件(一个或者多个,file-list)中查找包含模式串(pattern)的行,[option]用于控制grep命令的查找方式。 pattern可以是普通字符串,也可以是正则表达式,当查找的字符串包含正则表达式字符或者特</div> </li> <li><a href="/article/1735.htm" title="mybatis3入门学习笔记" target="_blank">mybatis3入门学习笔记</a> <span class="text-muted">白糖_</span> <a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/ibatis/1.htm">ibatis</a><a class="tag" taget="_blank" href="/search/qq/1.htm">qq</a><a class="tag" taget="_blank" href="/search/jdbc/1.htm">jdbc</a><a class="tag" taget="_blank" href="/search/%E9%85%8D%E7%BD%AE%E7%AE%A1%E7%90%86/1.htm">配置管理</a> <div>MyBatis 的前身就是iBatis,是一个数据持久层(ORM)框架。 MyBatis 是支持普通 SQL 查询,存储过程和高级映射的优秀持久层框架。MyBatis对JDBC进行了一次很浅的封装。 以前也学过iBatis,因为MyBatis是iBatis的升级版本,最初以为改动应该不大,实际结果是MyBatis对配置文件进行了一些大的改动,使整个框架更加方便人性化。</div> </li> <li><a href="/article/1862.htm" title="Linux 命令神器:lsof 入门" target="_blank">Linux 命令神器:lsof 入门</a> <span class="text-muted">ronin47</span> <a class="tag" taget="_blank" href="/search/lsof/1.htm">lsof</a> <div> lsof是系统管理/安全的尤伯工具。我大多数时候用它来从系统获得与网络连接相关的信息,但那只是这个强大而又鲜为人知的应用的第一步。将这个工具称之为lsof真实名副其实,因为它是指“列出打开文件(lists openfiles)”。而有一点要切记,在Unix中一切(包括网络套接口)都是文件。 有趣的是,lsof也是有着最多</div> </li> <li><a href="/article/1989.htm" title="java实现两个大数相加,可能存在溢出。" target="_blank">java实现两个大数相加,可能存在溢出。</a> <span class="text-muted">bylijinnan</span> <a class="tag" taget="_blank" href="/search/java%E5%AE%9E%E7%8E%B0/1.htm">java实现</a> <div> import java.math.BigInteger; import java.util.regex.Matcher; import java.util.regex.Pattern; public class BigIntegerAddition { /** * 题目:java实现两个大数相加,可能存在溢出。 * 如123456789 + 987654321</div> </li> <li><a href="/article/2116.htm" title="Kettle学习资料分享,附大神用Kettle的一套流程完成对整个数据库迁移方法" target="_blank">Kettle学习资料分享,附大神用Kettle的一套流程完成对整个数据库迁移方法</a> <span class="text-muted">Kai_Ge</span> <a class="tag" taget="_blank" href="/search/Kettle/1.htm">Kettle</a> <div>Kettle学习资料分享 Kettle 3.2 使用说明书 目录 概述..........................................................................................................................................7 1.Kettle 资源库管</div> </li> <li><a href="/article/2243.htm" title="[货币与金融]钢之炼金术士" target="_blank">[货币与金融]钢之炼金术士</a> <span class="text-muted">comsci</span> <a class="tag" taget="_blank" href="/search/%E9%87%91%E8%9E%8D/1.htm">金融</a> <div> 自古以来,都有一些人在从事炼金术的工作.........但是很少有成功的 那么随着人类在理论物理和工程物理上面取得的一些突破性进展...... 炼金术这个古老</div> </li> <li><a href="/article/2370.htm" title="Toast原来也可以多样化" target="_blank">Toast原来也可以多样化</a> <span class="text-muted">dai_lm</span> <a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/toast/1.htm">toast</a> <div>Style 1: 默认 Toast def = Toast.makeText(this, "default", Toast.LENGTH_SHORT); def.show(); Style 2: 顶部显示 Toast top = Toast.makeText(this, "top", Toast.LENGTH_SHORT); t</div> </li> <li><a href="/article/2497.htm" title="java数据计算的几种解决方法3" target="_blank">java数据计算的几种解决方法3</a> <span class="text-muted">datamachine</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a><a class="tag" taget="_blank" href="/search/ibatis/1.htm">ibatis</a><a class="tag" taget="_blank" href="/search/r-langue/1.htm">r-langue</a><a class="tag" taget="_blank" href="/search/r/1.htm">r</a> <div>4、iBatis 简单敏捷因此强大的数据计算层。和Hibernate不同,它鼓励写SQL,所以学习成本最低。同时它用最小的代价实现了计算脚本和JAVA代码的解耦,只用20%的代价就实现了hibernate 80%的功能,没实现的20%是计算脚本和数据库的解耦。 复杂计算环境是它的弱项,比如:分布式计算、复杂计算、非数据</div> </li> <li><a href="/article/2624.htm" title="向网页中插入透明Flash的方法和技巧" target="_blank">向网页中插入透明Flash的方法和技巧</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/Flash/1.htm">Flash</a> <div>将 Flash 作品插入网页的时候,我们有时候会需要将它设为透明,有时候我们需要在Flash的背面插入一些漂亮的图片,搭配出漂亮的效果……下面我们介绍一些将Flash插入网页中的一些透明的设置技巧。 一、Swf透明、无坐标控制 首先教大家最简单的插入Flash的代码,透明,无坐标控制: 注意wmode="transparent"是控制Flash是否透明</div> </li> <li><a href="/article/2751.htm" title="ios UICollectionView的使用" target="_blank">ios UICollectionView的使用</a> <span class="text-muted">dcj3sjt126com</span> <div>UICollectionView的使用有两种方法,一种是继承UICollectionViewController,这个Controller会自带一个UICollectionView;另外一种是作为一个视图放在普通的UIViewController里面。 个人更喜欢第二种。下面采用第二种方式简单介绍一下UICollectionView的使用。 1.UIViewController实现委托,代码如</div> </li> <li><a href="/article/2878.htm" title="Eos平台java公共逻辑" target="_blank">Eos平台java公共逻辑</a> <span class="text-muted">蕃薯耀</span> <a class="tag" taget="_blank" href="/search/Eos%E5%B9%B3%E5%8F%B0java%E5%85%AC%E5%85%B1%E9%80%BB%E8%BE%91/1.htm">Eos平台java公共逻辑</a><a class="tag" taget="_blank" href="/search/Eos%E5%B9%B3%E5%8F%B0/1.htm">Eos平台</a><a class="tag" taget="_blank" href="/search/java%E5%85%AC%E5%85%B1%E9%80%BB%E8%BE%91/1.htm">java公共逻辑</a> <div> Eos平台java公共逻辑 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> 蕃薯耀 2015年6月1日 17:20:4</div> </li> <li><a href="/article/3005.htm" title="SpringMVC4零配置--Web上下文配置【MvcConfig】" target="_blank">SpringMVC4零配置--Web上下文配置【MvcConfig】</a> <span class="text-muted">hanqunfeng</span> <a class="tag" taget="_blank" href="/search/springmvc4/1.htm">springmvc4</a> <div>与SpringSecurity的配置类似,spring同样为我们提供了一个实现类WebMvcConfigurationSupport和一个注解@EnableWebMvc以帮助我们减少bean的声明。 applicationContext-MvcConfig.xml <!-- 启用注解,并定义组件查找规则 ,mvc层只负责扫描@Controller --> <</div> </li> <li><a href="/article/3132.htm" title="解决ie和其他浏览器poi下载excel文件名乱码" target="_blank">解决ie和其他浏览器poi下载excel文件名乱码</a> <span class="text-muted">jackyrong</span> <a class="tag" taget="_blank" href="/search/Excel/1.htm">Excel</a> <div> 使用poi,做传统的excel导出,然后想在浏览器中,让用户选择另存为,保存用户下载的xls文件,这个时候,可能的是在ie下出现乱码(ie,9,10,11),但在firefox,chrome下没乱码, 因此必须综合判断,编写一个工具类: /** * * @Title: pro</div> </li> <li><a href="/article/3259.htm" title="挥洒泪水的青春" target="_blank">挥洒泪水的青春</a> <span class="text-muted">lampcy</span> <a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/%E7%94%9F%E6%B4%BB/1.htm">生活</a><a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98/1.htm">程序员</a> <div>2015年2月28日,我辞职了,离开了相处一年的触控,转过身--挥洒掉泪水,毅然来到了兄弟连,背负着许多的不解、质疑——”你一个零基础、脑子又不聪明的人,还敢跨行业,选择Unity3D?“,”真是不自量力••••••“,”真是初生牛犊不怕虎•••••“,••••••我只是淡淡一笑,拎着行李----坐上了通向挥洒泪水的青春之地——兄弟连! 这就是我青春的分割线,不后悔,只会去用泪水浇灌——已经来到</div> </li> <li><a href="/article/3386.htm" title="稳增长之中国股市两点意见-----严控做空,建立涨跌停版停牌重组机制" target="_blank">稳增长之中国股市两点意见-----严控做空,建立涨跌停版停牌重组机制</a> <span class="text-muted">nannan408</span> <div> 对于股市,我们国家的监管还是有点拼的,但始终拼不过飞流直下的恐慌,为什么呢? 笔者首先支持股市的监管。对于股市越管越荡的现象,笔者认为首先是做空力量超过了股市自身的升力,并且对于跌停停牌重组的快速反应还没建立好,上市公司对于股价下跌没有很好的利好支撑。 我们来看美国和香港是怎么应对股灾的。美国是靠禁止重要股票做空,在</div> </li> <li><a href="/article/3513.htm" title="动态设置iframe高度(iframe高度自适应)" target="_blank">动态设置iframe高度(iframe高度自适应)</a> <span class="text-muted">Rainbow702</span> <a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/iframe/1.htm">iframe</a><a class="tag" taget="_blank" href="/search/contentDocument/1.htm">contentDocument</a><a class="tag" taget="_blank" href="/search/%E9%AB%98%E5%BA%A6%E8%87%AA%E9%80%82%E5%BA%94/1.htm">高度自适应</a><a class="tag" taget="_blank" href="/search/%E5%B1%80%E9%83%A8%E5%88%B7%E6%96%B0/1.htm">局部刷新</a> <div>如果需要对画面中的部分区域作局部刷新,大家可能都会想到使用ajax。 但有些情况下,须使用在页面中嵌入一个iframe来作局部刷新。 对于使用iframe的情况,发现有一个问题,就是iframe中的页面的高度可能会很高,但是外面页面并不会被iframe内部页面给撑开,如下面的结构: <div id="content"> <div id=&quo</div> </li> <li><a href="/article/3640.htm" title="用Rapael做图表" target="_blank">用Rapael做图表</a> <span class="text-muted">tntxia</span> <a class="tag" taget="_blank" href="/search/rap/1.htm">rap</a> <div>function drawReport(paper,attr,data){ var width = attr.width; var height = attr.height; var max = 0; &nbs</div> </li> <li><a href="/article/3767.htm" title="HTML5 bootstrap2网页兼容(支持IE10以下)" target="_blank">HTML5 bootstrap2网页兼容(支持IE10以下)</a> <span class="text-muted">xiaoluode</span> <a class="tag" taget="_blank" href="/search/html5/1.htm">html5</a><a class="tag" taget="_blank" href="/search/bootstrap/1.htm">bootstrap</a> <div><!DOCTYPE html> <html> <head lang="zh-CN"> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"></div> </li> </ul> </div> </div> </div> <div> <div class="container"> <div class="indexes"> <strong>按字母分类:</strong> <a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a> </div> </div> </div> <footer id="footer" class="mb30 mt30"> <div class="container"> <div class="footBglm"> <a target="_blank" href="/">首页</a> - <a target="_blank" href="/custom/about.htm">关于我们</a> - <a target="_blank" href="/search/Java/1.htm">站内搜索</a> - <a target="_blank" href="/sitemap.txt">Sitemap</a> - <a target="_blank" href="/custom/delete.htm">侵权投诉</a> </div> <div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved. <!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>--> </div> </div> </footer> <!-- 代码高亮 --> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script> <link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/> <script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script> </body> </html>