PyTorch学习笔记(18) ——基于pytorch 1.1.0编写cuda扩展
0. 前言
对于一些特殊的算子, 我们需要进行定制其前向和反向的过程, 从而使得其能够获得更快的速度, 加速模型的训练. 这样, 我们自然会想到使用PyTorch的cuda扩展来实现, 这里, 我将以一个简单且易于理解的例子出发, 详细的介绍如何构造一个属于你的cuda扩展.
1. 为什么需要写cuda扩展?
由于我们的一些特殊结构可以由基础的pytorch提供的算子进行组合而形成, 但是, 其问题是[1]:
虽然已经使用了NVIDIA cuDNN、Intel MKL和NNPACK这些底层来加快训练速度,但是在某些情况下,比如我们要实现一些特定算法,光靠组合pytorch已有的操作是不够的。这是因为pytorch虽然在特定操作上经过了很好的优化,但是对于pytorch已经写好的这些操作,假如我们组合起来,组成我们的新的算法,pytorch才不管你的算法的具体执行流程,一般pytorch只会按照设计好的操作去使用GPU的通道,然后通道不能充分利用或者直接超负载,然后python解释器也不能对此进行优化,导致程序执行速度反而变慢了。
即由于一些自定义的操作是多个基础算子的组集, 这不可避免的导致吞吐量变小, 中间步骤变的繁多, 并没有充分利用硬件性能. 因此, 较好的方式是将复杂的操作进行fuse(也就是算子融合), 然后减少数据在多个操作之间流转,增强数据的本地性(locality), 从而提升GPU利用效率和计算速度.
这就是为什么我们需要写cuda扩展的原因: 对复杂逻辑的定制化加速处理
2. 写一个最基础的cuda扩展需要什么内容?
一个最简单的cuda扩展, 我们以传入一个4维的Tensor为例, 对其加N进行说明(注: 本例将在下文展开).
文件结构(the simplest cuda extension for pytorch 1.x):
- – setup.py 安装文件
- – cuda_ext/ cuda扩展所在文件夹
- ---- test_cuda.cpp cuda扩展声明&python binding
- ---- test_cuda_kernel.cu cuda扩展实际代码
当我们写好test_cuda.cpp, test_cuda_kernel.cu(cuda扩展的实际内容), 最后写好setup.py这个表示安装的文件, 即可进行安装并在pytorch1.1.0中使用你写的扩展啦~
3. 简单的例子: 对4维张量逐元素加N(N是自己指定的值)
3.1 环境说明
由于gcc版本和cuda的不兼容, 如果你使用的是gcc 6.x以上的版本, 那么务必需要将你的cuda和cudnn升级, 其中: cuda需要升级到10.0, cudnn也做对应升级. 如果你使用的cuda为9.0, 会出现错误[2].
本文使用的环境如下:
- Ubuntu18.04
- gcc 7.4.0
- cuda 10.0
- cudnn 7.6.4
- torch == 1.1.0
- pybind11
3.2 声明文件: cuda_ext/test_cuda.cpp
这里, 我们定义了① test1 ② test1_cuda 2个函数, 其中test1是调用test1_cuda的, 而test1_cuda就是我们即将在3.3中介绍的cuda实现的声明文件, 即cuda_ext/test_cuda.cpp在这里如同一个声明文件, 具体的定义在cuda_ext/test_cuda_kernel.cu中.
#include 需要注意的是, 我们在cuda_ext/test_cuda.cpp要把刚才写的test1函数绑定到module(这里的module在下面的setup.py定义, 为add_one_cuda)上,这里, 在cuda_ext/test_cuda.cpp文件最下面加上如下代码即可
// m是module的意思,不是method哦~, 这里的含义是, 为TORCH_EXTENSION_NAME模块绑定了名为test1的方法.
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("test1", &test1, "test1 (CUDA)");
}
3.3 定义文件: cuda_ext/test_cuda_kernel.cu
这个部分是需要我们实现的具体的cuda编码内容, 由于我们的目的很简单: 对4维张量逐元素加N(N是自己指定的值), 所以其实现如下:
#include 需要说明的点:
- ①
template的目的是为了泛化类型, 使得传入的pytorch tensor (cuda) 可以是单精度, 双精度 (int不行). - ② cuda部分的核心在于并行, 这块不展开, 看
test1_cuda_kernel的内容.
3.4 安装文件setup.py
好了, 现在, 我们把cuda_ext/下面的2个文件写好了, 那么我们需要按照第2部分所说的文件结构, 写一个setup.py, 其内容如下:
可以看出, 我们将写好的cuda扩展, 按照一定的方式, 用CUDAExtension进行封装, 然后扔进ext_modules里面作为setup函数的参数传入.
from setuptools import setup, find_packages
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
CUDA_FLAGS = []
ext_modules = [
# add_one_cuda 为 python调用的包名, 切记!
CUDAExtension('add_one_cuda', [
'cuda_ext/test1_cuda.cpp',
'cuda_ext/test1_cuda_kernel.cu',
])
]
INSTALL_REQUIREMENTS = ['numpy', 'torch', 'torchvision', 'scikit-image']
# https://pytorch.org/docs/master/cpp_extension.html
setup(
description='PyTorch implementation of ' ,
author='samuel ko', # 包的作者
author_email='[email protected]', # 包作者的邮箱
license='MIT License', # License类型
version='1.3.0', # 版本
name='add_one', # 包的名称
install_requires=INSTALL_REQUIREMENTS, # 预先需要的python依赖: numpy, torch等
ext_modules=ext_modules, # 这里指向我们的CUDAExtension.
cmdclass={'build_ext': BuildExtension}
)
写好之后, 我们就可以进行安装并验证了~
3.5 进行安装
安装的逻辑很简单, 进入你所想要的使用的虚拟环境, 然后执行
python3 setup.py install
即可, 但这里会出现一系列的问题, 我们把问题总结了一下,放在第4部分, 有需要的同学可以参考.
正确安装成功后, 会显示类似如下的信息:
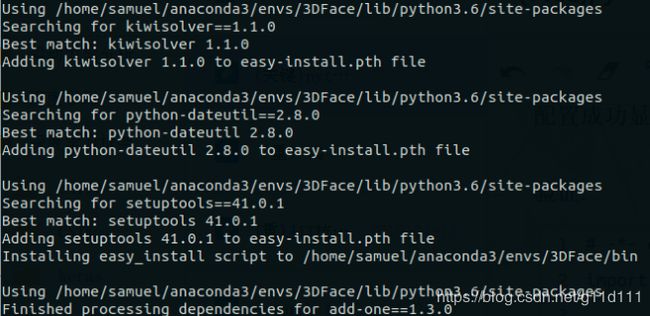
3.6 进行验证
好了, 安装完之后, 我们可以验证自己写的这个扩展能否正常使用(这里有一点要强调的是: 引入的包的名字要和CUDAExtension中的名字一致, 而非setup函数里传的名字一致!):
# -*- coding: utf-8 -*-
import torch
import add_one_cuda
a = torch.randn(1, 3, 2, 2).cuda()
print(a)
# 调用我们写好的, 绑定到add_one_cuda模块上的cuda函数test1
print(add_one_cuda.test1(a, 5))
结果如下, 成功的对a逐元素的加5:
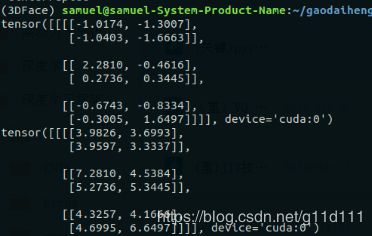
好了, 到这一步, 验证就全部通过了!
项目代码放在这里: github 地址, 大家可以直接拉下来跑一下.
4. 安装出现问题
4.1 error identifier __builtin_addressof is undefined
参考内容: https://blog.csdn.net/sophia_xw/article/details/100087061
解决方案:
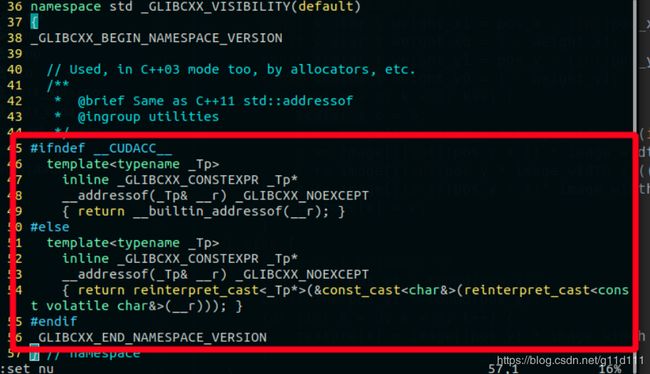
- sudo vim /usr/include/c++/7/bits/move.h (修改
move.h) - 在第44行开始添加如下内容:
4.2 RuntimeError: Ninja is required to load C++ extension
解决方案: 按顺序执行如下3条命令即可
wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip
sudo unzip ninja-linux.zip -d /usr/local/bin/
sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force
4.3 /usr/include/c++/6/tuple:495:244: error: wrong number of template arguments (4, should be 2)
原因: cuda版本过低 我当前的cuda版本是9.0,无法编译这套代码
解决: gcc版本与cuda9.0不兼容, 需要将cuda版本升级到10.0 [2]
cuda版本升级, 参考[3]
参考资料
[1] Pytorch拓展进阶(二):Pytorch结合C++以及Cuda拓展
[2] [SOLVED] Error in cuda-extension compilation from pytorch advanced tutorial
[3] Ubuntu下cuda版本升级
[4] TORCH.UTILS.CPP_EXTENSION
[5] Python包管理工具setuptools之setup函数参数详解