Kafka Streams实战-KTable API
本文会介绍:
- 流和表的关系
- 数据更新和KTable的配置
- 聚合、窗口和流表连接
- 全局KTable
1. 流和表的关系
1.1 数据更新流
假设我们有一个股票价格的数据流,每个数据包含股票的ID,timestamp和股价,要把这些数据写入到关系型数据库的表格里,如果使用股票的ID作为主键,那么具有相同ID的数据会被更新,我们可以把这种用于更新数据的流视为更新流。如下图所示:

这类似于changelog,具有相同key的数据只会保留最新的数据。而要保留每个key的最新数据,可以使用之前介绍过的compaction功能,旧的key/value会被删除,如下图所示:

对于changelog或更新流,我们会使用一个被称为KTable的抽象概念。
1.2 数据流和更新流的比较
我们会使用KStream和KTable来比较数据流和更新流。我们会通过运行一个简单的股票行情应用程序来说明,该应用程序会为三个虚构的公司生成三次股票报价,总共九条数据。KStream和KTable将读取这些数据并通过print()方法把它们输出打印到控制台。下图是打印的结果,KStream打印了所有九条数据,这是我们希望看到的结果,因为KStream视每一个数据都是独立的。而KTable只打印了三条数据,因为KTable视每一个数据都是对以前的更新。

注意:使用KTable时,数据必须要有key值,没有key是无法更新数据的。
从KTable的角度来看,它没有接收到9条单独的数据,它接收到的是三条原始数据和两轮的更新,它只打印最后一轮的更新。KTable的数据与KStream最后三条的数据是一样的,在后续部分会讲述KTable是如何仅仅输出更新数据的机制。
下面是上述应用程序的示例代码:
StreamsBuilder builder = new StreamsBuilder();
// 创建KTable实例
KTable stockTickerTable = builder.table("stock-ticker-table");
// 创建KStream实例
KStream stockTickerStream = builder.stream("stock-ticker-stream");
// 打印结果到控制台
stockTickerTable.toStream().print(Printed.toSysOut().withLabel("Stocks-KTable"));
stockTickerStream.print(Printed.toSysOut().withLabel("Stocks-KStream")); 注意:在创建KTable和KStream实例时没有指定任何serdes,之所以可以不指定是因为我们可以在配置里面先注册默认的serdes,例如:
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,
StreamsSerdes.StockTickerSerde().getClass().getName());如果要使用不同类型则需要通过Consumed
这里要说的是,在数据流中具有相同key的数据是更新。更新流是KTable背后的主要概念。
2. 数据更新和KTable的配置
要弄清楚KTable的功能,我们应该知道:
- 数据是存储在哪里?
- KTable是如何确定输出数据?
当调用StreamsBuilder.table(final String topic)创建KTable实例的同时,内部会创建一个StateStore来跟踪流的状态,但它不可用于交互式查询。StreamsBuilder.table有个重载的方法,第二个参数是Materialized的实例,允许自定义存储的类型并提供查询,在后续部分会讲述交互式查询。因此,KTable是使用与Kafka Streams集成的本地状态存储数据的。
要回答第二个问题,我们需要考虑以下几个因素:
- 应用程序的数据量,数据速率越快会增加输出更新数据的速度
- 数据中有多少个不同的key,越多数量的不同key会导致向下游发送更多更新数据
- 配置参数cache.max.bytes.buffering和commit.interval.ms的设置
从上述因素里面,我们只能控制配置参数的设置,所以本文只会介绍cache.max.bytes.buffering和commit.interval.ms。
2.1 设置缓存缓冲大小
KTable缓存用于对具有相同key的数据进行重复数据删除。此重复数据删除允许子节点仅接收最新更新而不是所有更新,从而减少处理的数据量。此外,只有最新的更新才会保存在状态存储中,这在使用持久状态存储时可以显著地提高性能。
下图是缓存操作的说明,当启用缓存后,并非所有数据更新都会发送到下游,缓存仅保存任何key的最新数据。

较大的缓存可以减少输出更新的次数,此外,缓存减少了持久存储(RocksDB)写入磁盘的数据量和(如果启用了日志)发送到changelog topic的数据量。缓存大小是由cache.max.bytes.buffering(默认是10485760=10MB)配置设置,它指定用于所有线程缓存的最大内存字节数,该内存量是平均分配给所有的流线程。流线程的数量是通过StreamsConfig.NUM_STREAM_THREADS_CONFIG配置指定,默认是1。
要关闭缓存,可以把cache.max.bytes.buffering设置为0,但会导致每个KTable的更新都会发送到下游,意味着更新流会变为事件流。此外,没有缓存会增加I/O消耗,因为持久存储会把每个更新写入磁盘而不是仅写入最新更新。
2.2 设置提交间隔时间
提交间隔时间配置commit.interval.ms指定保存处理器状态的频率。当处理器的状态被保存(提交)时,它会强制执行缓存刷新,向下游发送最新更新的去重数据。在下面完整的缓存工作流程图中,提交或缓存到达最大设定值都会向下游发送数据。
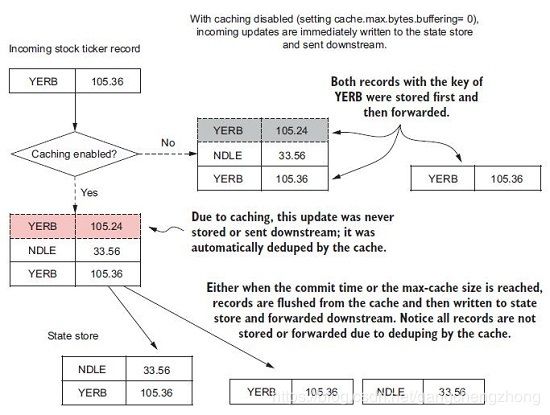
因此,我们需要权衡提交间隔时间和缓存大小的配置。较短的提交间隔时间和大的缓存仍然会导致频繁的更新,较长的提交间隔时间可以导致更少的更新(取决于缓存大小设置)。这里没有硬性规则,只有反复测试才能确定哪种配置是最适合的,最好从默认值(commit.interval.ms=30000)30秒和10MB开始。
3. 聚合和窗口操作
3.1 统计股票交易量
在处理流数据时,聚合和分组是必不可少的工具。在本例中,我们将统计股票的交易量。要进行此统计,从较高的层面来说,需要以下几个步骤:
- 从一个发布原始股票交易信息的topic创建数据源。
- 需要把股票对象映射为股票交易量对象,因为我们只需要统计交易中涉及的股票交易量。
- 按股票代码分组,一旦分组后,就可以计算出一个滚动更新的股票交易总量。
下图是对应的处理拓扑:
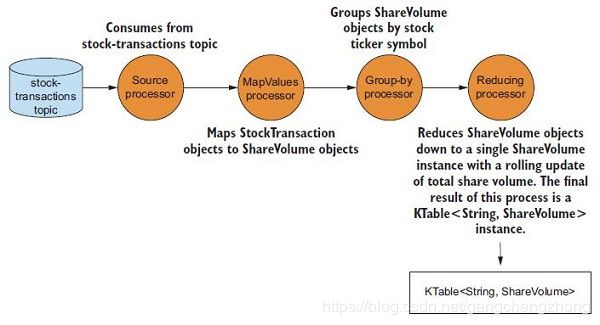
上述的StockTransaction是股票对象,包含有关交易的元数据,ShareVolume是股票交易量对象,包含股票交易量。通过MapValues处理器把StockTransaction映射为ShareVolume,然后通过Group-by处理器按股票代码分组,最后通过Reducing处理器计算出一个滚动更新的股票交易总量,输出KTable
下面是对应的示例代码:
StreamsBuilder builder = new StreamsBuilder();
Serde stringSerde = Serdes.String();
// 通过StreamsSerdes创建序列化类
Serde stockTransactionSerde = StreamsSerdes.StockTransactionSerde();
Serde shareVolumeSerde = StreamsSerdes.ShareVolumeSerde();
KTable shareVolume = builder
.stream("stock-transactions",
Consumed.with(stringSerde, stockTransactionSerde)
// 指定offset重置策略
.withOffsetResetPolicy(AutoOffsetReset.EARLIEST))
.mapValues(stockTransaction -> ShareVolume.newBuilder(stockTransaction).build())
// 按股票代码分组
.groupBy((k, v) -> v.getSymbol(), Serialized.with(stringSerde, shareVolumeSerde))
// 计算滚动更新的股票交易总量
.reduce(ShareVolume::sum); 调用KStream.groupBy方法会返回一个KGroupedStream实例,它是按keys分组之后数据流的中间表示,但永远不能直接使用,而是需要先执行聚合操作,例如reduce,返回KTable实例才能使用。因为聚合操作返回KTable并使用了状态存储,所以并非所有更新都会向下游发送数据。另外,KTable.groupBy方法返回类似的KGroupedTable,它是按key重新分组后更新流的中间表示。
GroupByKey和GroupBy的区别
KStream有两个分组的方法:GroupByKey和GroupBy,两者都是返回KGroupedTable。
- GroupByKey方法适用于KStream已经有非空的keys,更重要的是,它不会设置重新分区的flag。
- GroupBy方法假定你已经修改了keys,因此重新分区的flag会设为true。在调用GroupBy、joins、聚合等方法时会导致自动重新分区。
- 一般来说,应该尽可能优先选择GroupByKey而不是GroupBy。
3.2 窗口操作
在Kafka Streams中,有以下三种窗口类型:
- Session windows(会话窗口)
- Tumbling windows(翻滚窗口)
- Sliding/hopping windows(滑动/跳动窗口)
选择哪种类型取决于业务需求,翻滚和滑动窗口是有时间限制的,而会话窗口更多地是关于用户活动的,其长度仅取决于用户的活跃程度。需要注意的是,它们都是基于数据的timestamps而不是时钟时间。接下来,我们会使用每种窗口类型来举例说明:
3.2.1 会话窗口
会话窗口与其它窗口非常不同,它不是严格地受时间限制,而是与用户活动有关。下图显示了如何查看会话窗口,较小的会话将与左边的会话合并。但右边的会话将会是一个新的会话,因为它在一个大的非活动间隔后面。会话窗口是基于用户活动,但它们使用数据的timestamps来决定数据属于哪个会话。

下面是使用会话窗口统计股票交易的示例代码:
Serde stringSerde = Serdes.String();
// 通过StreamsSerdes创建序列化类
Serde transactionSerde = StreamsSerdes.StockTransactionSerde();
Serde transactionKeySerde = StreamsSerdes.TransactionSummarySerde();
StreamsBuilder builder = new StreamsBuilder();
// 20秒
long twentySeconds = 1000 * 20;
// 15分钟
long fifteenMinutes = 1000 * 60 * 15;
KTable, Long> customerTransactionCounts = builder
.stream("stock-transactions",
Consumed.with(stringSerde, transactionSerde)
// 指定offset重置策略
.withOffsetResetPolicy(AutoOffsetReset.LATEST))
.groupBy((noKey, transaction) -> TransactionSummary.from(transaction),
Serialized.with(transactionKeySerde, transactionSerde))
.windowedBy(SessionWindows.with(twentySeconds).until(fifteenMinutes)).count();
customerTransactionCounts.toStream().print(
Printed.,
Long>toSysOut().withLabel("Customer Transactions Counts")); 调用KGroupedStream.windowedBy方法会返回一个窗口化流,以便执行某种窗口化聚合。根据提供的窗口类型,可以获得TimeWindowedKStream或SessionWindowedKStream。调用windowedBy(SessionWindows.with(twentySeconds).until(fifteenMinutes))方法会创建一个会话窗口,其非活动间隔为20秒,保留时间为15分钟。非活动间隔为20秒表示应用程序包含在当前会话结束或开始时间20秒内到达的任何数据。然后,在会话窗口中指定聚合操作(这里是计数)。如果数据在非活动间隔外,应用程序会创建一个新的会话。此外,当会话被合并时,新创建的会话分别使用最早的和最晚的timestamp来表示新会话的开始和结束。如下表所示:

当数据到达时会查找具有相同key、结束时间要小于(当前timestamp - 非活动间隔)并且开始时间要大于(当前timestamp + 非活动间隔)的会话。根据这个规则,下面是上表的四个数据最终被合并到二个会话中的方式:
- 数据1是第一个,所以开始和结束时间都是00:00:00。
- 数据2到达时,查找最早结束时间为23:59:55且最晚开始时间为00:00:35的会话。会找到数据1,因此合并会话1和2。保留会话1的开始时间(最早)和会话2的结束时间(最晚),因此得到一个新的会话从00:00:00开始到00:00:15结束。
- 数据3到达时,查找00:00:30和00:01:10之间的会话,但找不到。因此为key 123-345-654添加第二个会话,开始和结束时间都是00:00:50。
- 数据4到达时,查找23:59:45和00:00:25之间的会话。会找到会话1和2,因此合并它们,得到一个开始时间为00:00:00,结束时间为00:00:15的会话。
3.2.2 翻滚窗口
固定或翻滚窗口用于统计给定时间内的事件,例如,每20秒统计一家公司的所有股票交易。在20秒的时间结束后,窗口将“翻滚”到一个新的20秒窗口,如下图所示:

事件是没有重叠的,第一个事件窗口包含[100,200,500,400],第二个事件窗口包含[350,600,50,2500]。
下面是使用翻滚窗口统计每20秒股票交易的代码:
// 翻滚窗口使用TimeWindows
.windowedBy(TimeWindows.of(twentySeconds)).count();没有调用until方法默认的保留时间是24小时。
3.2.3 滑动/跳动窗口
滑动/跳动窗户和翻滚窗户只有很小的差别,前者在启动另一个窗口来处理最新事件之前,是不会等待整个窗口的持续时间,而是会在等待小于整个窗口的持续时间间隔之后执行一个新的计算。为了说明滑动窗口和翻滚窗口的区别,让我们重新设计统计股票交易的例子。现在仍然希望计算交易次数,但不希望在更新计数之前等待整个持续时间,而是希望每5秒更新一次,如下图所示:

这次是有三个结果窗口,左侧的框是第一个20秒的窗口,然后“滑动”,每5秒后更新形成新的窗口,这时事件是有重叠的。窗口1包含[100,200,500,400],窗口2包含[500,400,350,600],窗口3包含[350,600,50,2500]。
下面是使用滑动窗口统计股票交易的代码:
.windowedBy(TimeWindows.of(twentySeconds)
.advanceBy(fiveSeconds).until(fifteenMinutes)).count();通过调用advanceBy方法,可以将翻滚窗口转换为跳动窗口,此例是每5秒滑动一次,指定保留时间为15分钟。
3.3 流表连接
有时候我们需要连接数据流KStream和更新流KTable,那么要用到流表连接,例如关联股票交易数量和相关行业的财经新闻。下面是使用现有代码实现此目的的步骤:
- 将股票交易计数的KTable转换为KStream
- 创建一个从财经新闻topic读取的KTable,它将按行业分类
- 按行业连接股票交易数量和财经新闻
3.3.1 把KTable转换为KStream
要执行KTable-to-KStream转换,可以采用以下步骤:
- 调用KTable.toStream()方法
- 调用KStream.map方法把key更改为行业名称,并从Windowed实例中获取TransactionSummary对象
下面是对应的示例代码:
KStream countStream = customerTransactionCounts.toStream().map((window, count) -> {
// 从Windowed实例中获取TransactionSummary对象
TransactionSummary transactionSummary = window.key();
// 使用行业名称作为新的key
String newKey = transactionSummary.getIndustry();
// 更新交易量
transactionSummary.setSummaryCount(count);
// 返回新的KeyValue
return KeyValue.pair(newKey, transactionSummary);
}); 因为调用了KStream.map操作,所以返回的KStream实例在使用连接时会自动重新分区。
3.3.2 创建财经新闻的KTable
KTable financialNews = builder
.table("financial-news", Consumed.with(AutoOffsetReset.EARLIEST)); 3.3.3 连接股票交易量和财经新闻
在之前的流和状态一文里已经介绍过,连接两个流需要先创建连接器,实现其接口方法apply。连接流和表也一样,下面是示例代码:
// 使用Lambda表达式创建连接器
ValueJoiner valueJoiner = (txnct, news) -> String.format(
"%d shares purchased %s related news [%s]", txnct.getSummaryCount(), txnct.getStockTicker(), news);
// 左连接
KStream joined = countStream.leftJoin(financialNews, valueJoiner,
Joined.with(stringSerde, transactionKeySerde, stringSerde));
joined.print(Printed.toSysOut().withLabel("Transactions and News")); 这里不需要使用JoinWindow,因为在KTable中每个key只对应一条数据,连接和时间是没有关系的,KTable中要么有数据,要么没有。这里的关键点是,使用KTables可以提供不常更新的数据来丰富KStream的数据。
3.4 GlobalKTable
在之前介绍过的例子里面,当把key映射为新类型或值时,数据流需要被重新分区。有时是你明确地进行重新分区,有时是Kafka Streams自动进行。
3.4.1 重新分区是有代价的
重新分区是有代价的,此过程还有额外的开销:创建中间的topics,把重复的数据保存在另外一个topic,以及由于写入和读取其它topic而导致的延时增加。此外,如果需要连接多个方面或维度,则需要链式连接(chain joins),使用新keys映射数据,并重复重新分区的过程。
3.4.2 连接小的数据集
在某些情况下,你想连接的数据是相对较小的,整个查询数据的副本可以保存在每个节点的本地存储。对于这种情况,Kafka Streams提供了GlobalKTable。它是唯一的,因为应用程序会把所有数据都复制到每个节点,所以数据流不需要通过查找数据的key进行分区。GlobalKTables还允许你进行non-key连接,以下让我们重新回顾之前的其中一个例子来说明这个功能。
3.4.3 使用GlobalKTable连接KStream
如果为每个客户执行一个窗口化的股票交易统计,输出的结果会类似如下:
{customerId='074-09-3705', stockTicker='GUTM'}, 17
{customerId='037-34-5184', stockTicker='CORK'}, 16这样的输出虽然实现了需求,但如果可以显示客户名和公司名会更直观。你可以执行常规的连接来添加客户名和公司名,但需要执行两个key的映射和重新分区。使用GlobalKTable,可以避免这些麻烦。下面是实现的步骤:
先定义会话窗口统计股票交易的流程:
// 使用Lambda表达式创建映射
KeyValueMapper, Long, KeyValue> transactionMapper = (
window, count) -> {
TransactionSummary transactionSummary = window.key();
String newKey = transactionSummary.getIndustry();
transactionSummary.setSummaryCount(count);
return KeyValue.pair(newKey, transactionSummary);
};
// 使用会话窗口计算股票交易量,然后转换为KeyValue
KStream countStream = builder
.stream("stock-transactions",
Consumed.with(stringSerde, transactionSerde)
.withOffsetResetPolicy(AutoOffsetReset.LATEST))
.groupBy((noKey, transaction) -> TransactionSummary.from(transaction),
Serialized.with(transactionSummarySerde, transactionSerde))
.windowedBy(SessionWindows.with(twentySeconds))
.count()
.toStream()
.map(transactionMapper); 然后创建GlobalKTable:
// 从companies的topic创建股票代码/公司名的GlobalKTable
GlobalKTable companies = builder.globalTable("companies");
// 从clients的topic创建客户ID/客户名的GlobalKTable
GlobalKTable clients = builder.globalTable("clients"); 上述代码会从指定的topic读取数据,创建GlobalKTable实例,默认使用配置中的key和value反序列化器,key为null的数据会被丢弃,返回的GlobalKTable将会使用本地的KeyValueStore保存数据。我们先要把股票代码/公司名和客户ID/客户名的数据分别写入companies和clients的topic。
最后使用两个GlobalKTable连接KStream:
countStream
// 连接KStream和companies的GlobalKTable,连接key是股票代码
// 输出的TransactionSummary会添加公司名
.leftJoin(companies, (key, txn) -> txn.getStockTicker(),
(txn, companyName) -> txn.withCompanyName(companyName))
// 连接KStream和clients的GlobalKTable,连接key是客户ID
// 输出的TransactionSummary会添加客户名
.leftJoin(clients, (key, txn) -> txn.getCustomerId(),
(txn, customerName) -> txn.withCustomerName(customerName))
.print(Printed.toSysOut()
.withLabel("Resolved Transaction Summaries")); 上面链式调用了leftJoin方法,输出的结果会类似如下,更加直观地显示了客户名和公司名:
{customer='Barney, Smith' company="Exxon", transactions= 17}总之,需要记住的是你可以使用本地状态来连接数据流KStream和更新流KTable。此外,当数据集较小时,可以使用GlobalKTables把所有数据都复制到每个节点,不需要通过查找数据的key进行分区。
END O(∩_∩)O