 平均分 (4个评分)
平均分 (4个评分)
计算机擅长执行快速搜索操作,可以根据给定的搜索词,对大量存储的信息快速进行搜索。但是,拼写检查应用程序所要求的搜索能力,不仅仅是正确的字符串匹配。在这篇文章中,我将介绍搜索算法的一些历史,包括语音匹配算法(比如 Soundex 和 Metaphone ),字符串相似性类型(例如动态编程算法)。我会解释这些算法对于拼写检查来说各自的优势与不足,然后介绍最后一个变种-- Aspell 算法,这个算法是专门为拼写检查应用程序编写的。
Aspell 算法结合了前面搜索与匹配算法的最佳特性,是 Jazzy 的底层框架,是 Java 平台的拼写检查器 API。在这篇文章的后半部分里,您将看到 Jazzy 在 Java 框架里是如何应用 Aspell 算法的。我会向您展示 Jazzy 识别拼写错误的单词并提供合适的修正 。在文章结尾,我会用一个实例,演示在 Jazzy 的帮助下,您可以很容易地把它的拼写检查特性合并到 Java 应用程序中。
语音匹配算法
正确拼出姓氏可能是个挑战。如果一个人的姓不太常见,那么当他们通过电话订购的时候,经常发现名字被弄错。即使是常见的名字也可能因为拼写上的微小差异而拼错,例如 Smith和 Smyth是发音相同的常见名字的两个变体。
特别是在名字拼写上,变化更丰富,这样就形成了一些有趣的拼写检查算法。我要介绍的第一个算法类型是语音匹配算法,它的目标是解决“哪个名字和听起来像 x的名字匹配”这样的问题。在搜索数据库和其他参考应用程序里,这种算法类型相当普遍。例如,在搜索家族历史时,用户应当既能检索到正确匹配,也会得到相似的匹配,这样就有可能找到家族姓氏渊源流传中发生变化或者在某些记录中被拼写错误的历史。
回页首
Soundex 算法
Soundex 算法从 1920 年起就一直被用来为所有美国人口做索引,是家族软件常用的算法。原始 Soundex 算法在 1918 年由 Margaret K. Odell 和 Robert C. Russell 申请专利(请参阅 参考资料),他们当初是想“提供一个索引,按照发音而不是按照名字的字母表输入名字,对名字分组”。
从实际上说,Soundex 算法的运作方式是把某个字母表中的每个字母映射成代表它的语音组的一个数字代码。在这个方案里,像 d和t)这样的字母在同一个组里,因为它们发音相近(实际上每个字母都是用类似的机制发出声音的),而元音则一概忽略。通过对整体单词应用这种映射,就产生了单词的语音“键”。发音相近的单词通常会有相同的键。例如, Smith和 Smyth 的 Soundex 都是 S530 。
Soundex 最常见的一个变体通过 Donald E. Knuth 的 The Art of Computer Programming一书流行开来。您可以在清单 1 中看到这个算法的 Java 实现。请注意该算法使用了 Java 正则表达式,正则表达式只有在 Java 1.4 发行版之后才可用。
清单1. Knuth 的 Soundex
public class KnuthSoundex implements PhoneticEncoder {
// ABCDEFGHIJKLMNOPQRSTUVWXYZ
private static final String SOUNDEX_DIGITS = "01230120022455012623010202";
public String calculateCode(String string) {
String word = string.toUpperCase(); // 01 ASHCROFT
word = word.replaceAll("[^A-Z]", ""); // 02
if (word.length() == 0) { // 03
return ""; // 04
} // 05
char first = word.charAt(0); // 06
word = first + word.substring(1).replaceAll("[HW]", ""); // 07 ASCROFT
StringBuffer sndx = new StringBuffer(); // 08
for (int i = 0; i < word.length(); i++) { // 09
sndx.append(SOUNDEX_DIGITS.charAt((int) (word.charAt(i) - 'A'))); // 10
} // 11
word = sndx.toString().replaceAll("(.)\\1+", "$1"); // 12 026013
word = first + word.substring(1); // 13 A26013
word = word.replaceAll("0", ""); // 14 A2613
return (word + "000").substring(0, 4); // 15 A261
}
}
|
代码说明
上面的代码相当简洁,所以我逐行来说明它的功能:
- 行 01 到 05 对输入进行规范化,把输入变成大写字母,去掉其他字符。
- 行 06 保证单词的第一个字母不变。
- 行 07 去掉后续的
H或W字母。 - 行 08 到 11 用字母的语音代码替换单词里的每个字母。
- 行 12 删除相邻的相同语音代码。(请注意:这意味着,与元音的处理方式不同,插在中间的字符
H和W不会对组合相同代码的字母形成障碍。) - 与行 06 类似,行 13 保证单词的第一个字母不变。
- 行 14 消除所有元音。
- 行 15 通过把单词裁剪成 4 个字母,形成 Soundex (可能要用字符
0来填充)。
为了真正理解算法,手工地逐行执行算法会很有帮助。代码右手边的列用于跟踪 word 变量的值,从输入的名字 Ashcroft开始。对于算法来说,这是个很好的测试用例,因为 s和 c组合,没有理睬插在中间的 h。(在同类 Web 站点上可以找到的许多 Soundex 实现都没有正确地实现这一规则。)
Soundex 用于拼写检查
不幸的是,Soundex 算法是一个差劲的拼写检查备选方案。首先来说,发音不同的单词可能有相同的 soundex。例如, White和Wood 的 soundex 码相同,同为 W300 。这并不奇怪,因为 Soundex 算法的设计,就是为了把发音 相似的名字组合在一起,而不是严格地按照发音 相同组合。虽然这个特性对于某些应用程序来说可能是理想的 -- 例如用来帮助电话操作员识别用不同重音说出的名字的应用程序 -- 但是它对拼写检查应用程序没有用,因为它会产生太多的匹配。例如,拼错的 algorithum一词会与我的示例字典中的下列单词匹配:
alacritous, alacrity, alcheringa, alcoran, algeria, algerian, algerians, algiers, algor, algorism, algorithm, algorithmic, algorithmically, algorithms, alizarin, alizarine, alkoran, alleger, allegers, allegoric, allegorical, allegorically, allegories, allegorist, allegorists, allegorizes, allegory, allegretto, allegrettos, allegro, allegros, allocheiria, allochiria, allocortex, allograft, allograph, allographic, allographs
即使考虑到同一单词的变体( allegoric、 allegorical、 allegorically)造成的额外匹配,您通常也应当要求拼写检查算法提供更加严格的匹配。 您应当还记得, Soundex 算法也会把每个 soundex 代码裁剪成 4 个字符,这样就疏忽了长单词的尾部,因此也就进一步增加了匹配的数量。而且麻烦还不止于此。
同音问题
正如发音不同的单词有可能有相同的 soundex,反过来的情况也有可能发生:发音相同的单词,叫做 同音词(homophone),可能有不同的代码。这是由于某些字母可能不发音,例如在 Thompson ( T512 )中的 p 造成它发音与 Thomson( T525 )相同,但代码不同,还有 Leigh ( L200 )中的 gh与 Lee ( L000 ) ,也有同样的问题。与此类似,单词的开始字母可能不同,但是不影响它的发音,例如 Carr( C600 )中的 c与 Karr( K600 )中的 k。Soundex 算法本身造成了这个问题,因为它无法把每个单词中的原始字母映射成语音数字。
所谓同音的问题,实际上产生于这样一个现实:英语语言有不规范拼写(可能比其他语言更甚)。虽然 Soundex 算法有许多小的变体,但是他们都缺少对英语拼写规则的认识,更不用说这些规则的例外了。这种不规范的后果就是, Soundex 不太适合做英语中的拼写检查。例如, Soundex 对于拼写错误的 lam ( L500 ),提供了一个正确拼写形式 lamb( L510 )不同的语音编码。这样,基于 Soundex 的拼写检查应用程序就无法把 lamb作为拼写错误的 lam的修改建议。正是这个问题,引领着 Lawrence Phillips 找到了 Soundex 算法的替代品,叫做 Metaphone。
回页首
Metaphone 算法
Metaphone 算法背后的想法,首先发表在 1990 年的 Computer Language杂志上(请参阅 参考资料),这个算法明确地对英语发音的公共规则进行了编码,而这正是 Soundex 没有解决的问题。例如, Metaphone 算法包含一个明确的规则:在字母 b在单词末尾出现在字母 m后面时,就删除它。这个规则保证了 lam和 lamb 会有相同的编码( LM ),这样就使拼写检查应用程序能够为 lam提供正确的替换。
Metaphone 算法使用了 16 个辅音类,由下列字符代表:
B X S K J T F H L M N P R 0 W Y |
字符 0 是零,用来代表 th 的声音。就像在 Soundex 算法里一样,第一个字母被保留,最后的代码被裁剪成四个字符,但是如果短于四个字符,也并不填充。重复的字母和元音通常被删除,与元音的处理一样。Metaphone 算法整体上是一套规则集,可以把字母组合映射成辅音类。这个算法的 Java 实现需要几百行代码,具体可以参阅 Apache Jakarta Commons Codec 项目中的 Metaphone 代码(请参阅 参考资料)。在清单 2 中,您可以看到当您把 Apache 的 Metaphone 类用作 JUnit 的测试用例,检查单词 lamb的代码时发生的情况:
清单2. 使用 Apache Metaphone 类
import junit.framework.TestCase;
import org.apache.commons.codec.language.Metaphone;
public class ApacheMetaphoneTest extends TestCase {
public void test() {
Metaphone metaphone = new Metaphone();
assertEquals("LM", metaphone.encode("lam"));
assertEquals("LM", metaphone.metaphone("lam"));
assertEquals(metaphone.encode("lamb"), metaphone.encode("lam"));
assertTrue(metaphone.isMetaphoneEqual("lamb", "lam"));
}
}
|
虽然在规则里仍然有一些缺陷,但 Metaphone 算法在 Soundex 上有了提高。例如,Metaphone 的作者 Phillips 指出, Bryan(BRYN )和 Brian) BRN )应当有相同的代码。 Phillips 在 2000 年 6 月出版的 C/C++ Users Journal 上发表了他对 Metaphone 的模糊匹配(是这么叫的)改进的尝试。 DoubleMetaphone 算法对原来的辅音类做了一些修正,它把所有的开始元音都编码成 A ,所以不再使用 Soundex 算法。更加根本的变化是,DoubleMetaphone 被编写成可以为多音词返回不同的代码。例如, hegemony中的 g 可以发轻声,也可以发重音,所以算法既返回 HJMN ,也可以返回 HKMN 。除了这些例子之外,Metaphone 算法中的多数单词还是返回单一键。您可以参见清单 3 中摘录的 Apache 的 DoubleMetaphone 类的代码。
清单3. 使用 Apache DoubleMetaphone 类
import junit.framework.TestCase;
import org.apache.commons.codec.language.DoubleMetaphone;
public class ApacheDoubleMetaphoneTest extends TestCase {
public void test() {
DoubleMetaphone metaphone = new DoubleMetaphone();
assertEquals("HJMN", metaphone.encode("hegemony"));
assertEquals("HJMN", metaphone.doubleMetaphone("hegemony"));
assertEquals("HJMN", metaphone.doubleMetaphone("hegemony", false));
assertEquals("HKMN", metaphone.doubleMetaphone("hegemony", true));
}
}
|
虽然 Soundex 和 Metaphone 算法都很好地解决了语音模糊的匹配问题,但是如果不能纠正打字错误,那么拼写检查应用程序是不完整的。 当您的手指在键盘上滑过,打的是 labm ( LBM )而不是 lamb( LM ), 打字错误就出现了。语音匹配算法不能用它的替换来匹配这种拼写错误,因为两个单词听起来是不同的。为了解决这类问题,您的拼写检查应用程序必须包括字符串相似性算法。
回页首
字符串相似性算法
您还记得这样的字谜么--每次只允许修改单词的一个字母,就能把它变换成另外一个单词?例如, ship可以通过逐步修改变成 crow,通过中间单词 shop、 chop和 crop。这种游戏为您提供了一条路,可以清楚地理解两个单词之间的距离这一概念。 距离是从一个单词变换成另外一个单词所需要的步数,要求是每次只能改变一个字母,而且每步都要使用字典中实际存在的单词。我把这叫做 字谜距离(puzzle distance)。在这个示例里, ship和 crow之间的字谜距离是 4。
虽然我们经常把距离当作是空间中二点之间的物理度量,但是数学家则用更具一般性的概念把它定义为 度量(metric)。这个定义让您可以在不同的应用程序中使用距离的概念;在这里,您感兴趣的是两个字符串或两个单词之间的距离。它的意义在于,对于拼写错误的单词,您应当查找和它“接近”(这就使用了距离的定义)的单词。距离度量的任何定义都必须满足一些可以度量的属性;例如,距离永远不可能为负。
虽然顺序比较有许多方面(请参阅 参考资料),但是您的目的是找到距离的定义,使距离有助于实现良好的拼写校正。前面定义的字谜距离至少有一个理由不适合做这项工作:拼写错误的单词比起正确拼写的单词来说,通常不止错了一个字母。例如,对于拼错的puzzel,找不到“路碑”可以到达拼写正确的英文单词。幸运的是,已经设计了大量适用于拼写检查的度量方式。
回页首
动态编程算法
动态编程算法从本质上看是一种穷举方法,它会考虑到把源单词转换成目标单词的所有不同方法,从而找到成本最小、或者单词间距离最短的方法。 Levenshtein 距离算法是动态编程算法的一个具体实现,它允许进行三类操作,把源单词 x转换成目标单词 y:
- 把单词 x中的一个字符 替换成单词 y中的一个字符
- 把单词 x中的一个字符 删除
- 在单词 y中 插入一个字符
每个操作都会有一定的成本,而总距离就是从单词 x变换到单词 y 的最小成本。从直观上看,基于这些操作的算法应当可以很好地进行拼写校正,因为打字错误无外乎是这些操作所涉及的键入错误。(实际上, Levenshtein 距离也称作 编辑距离。)例如,当我把单词 wrong打成 wromg(按了 m键,而不是 n 键)的时候,就是一个替换错误;当我打成 wromng(按了 m键,还有 n键)的时候,就是一个删除错误;而当我打成 wrog(遗漏了 n 键),就是一个插入错误。
计算距离
为了更好地理解动态编程算法,可以画一个表格,它的行对应源单词的字母,它的列对应目标单词的字母。处在 (i, j)位置的单元格代表从源单词的 i字母到目标单词的 j字母的最小距离。
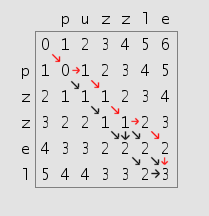
对于 Levenshtein 距离,删除和插入的成本为 1。如果字符有差异,那么替换的成本为 1,否则为 0。开始算法的时候,您先填充第一行,第一行对应着空的源单词,这样它就是插入 0,1,..., j个字母的成本。同样,第一列对应着空的目标单词,所以它就是删除 0, 1, ..., i个字母的成本。如果您以 pzzel到 puzzle 的转换为例,那么您会得到如 图 1 所示的网格。
图1. Levenshtein 算法的第一阶段

接下来,您要计算余下的每个单元格的值,通过考虑它的三个邻居来计算:上、左、对角上和左。图 2 显示了这个计算方案。
图2:如何计算单元格的成本
| 对角 | 上 |
| 左 | Min( 对角+ 替换成本, 上+ 删除成本, 左+ 插入成本 ) |
例子结果网格如图 3 如示。右下角单元格的成本是 3,是 pzzel和 puzzle之间的 Levenshtein 成本。
图3. Levenshtein 算法的最后阶段
Levenshtein 算法的属性
作为额外优点, Levenshtein 算法还为您提供了一系列操作,也叫做 校准(alignment),它构成了转换。一对单词通常有不止一次校准。校准对应着沿图表的箭头从左上角单元格到右下角单元格的最小成本路径。例如, 清单 4表示的校准(在 图 3中以红色箭头表示),可以按照下面的操作顺序,一个字母一个字母地读成:
- 把 p替换成 p(成本为 0)
- 插入 u(成本为 1)
- 把 z替换成 z(成本为 0)
- 把 z替换成 z(成本为 0)
- 插入 l(成本为 1)
- 把 e替换成 e(成本为 0)
- 删除 l(成本为 1)
清单4. pzzel 和 puzzle 之间的校准
p-zz-el puzzle- |
Levenshtein 算法的 Java 实现
清单 5 列出了 Levenshtein 算法的一个简单而直观的 Java 实现。 LevenshteinDistanceMetric 类有些类似于 Apache Jakarta Commons 项目的 StringUtils 类。这些实现的限制是:它们不能处理大型字符串,因为它们的存储需求为 O(mn), 其中 m和 n 分别是源单词和目标单词的长度。如果您只需要计算距离,不需要校准,就像通常情况那样,那么可以很容易地把空间需求降到 O(n),因为计算下一行只需要前面一行。针对 Apache 版本已经提出了一个修正建议(请参阅 参考资料),但是它在本文写作的时候还没有被合并进来(2.0版)。
请注意: Levenshtein 算法的运行时间总是 O(mn)。所以,如果在非常大的字典里查找拼写错误的最相近匹配,这个算法就太慢了。
清单 5. Levenshtein 距离算法的实现
public class LevenshteinDistanceMetric implements SequenceMetric {
/**
* Calculates the distance between Strings x and y using the
* Dynamic Programming algorithm.
*/
public final int distance(String x, String y) {
int m = x.length();
int n = y.length();
int[][] T = new int[m + 1][n + 1];
T[0][0] = 0;
for (int j = 0; j < n; j++) {
T[0][j + 1] = T[0][j] + ins(y, j);
}
for (int i = 0; i < m; i++) {
T[i + 1][0] = T[i][0] + del(x, i);
for (int j = 0; j < n; j++) {
T[i + 1][j + 1] = min(
T[i][j] + sub(x, i, y, j),
T[i][j + 1] + del(x, i),
T[i + 1][j] + ins(y, j)
);
}
}
return T[m][n];
}
private int sub(String x, int xi, String y, int yi) {
return x.charAt(xi) == y.charAt(yi) ? 0 : 1;
}
private int ins(String x, int xi) {
return 1;
}
private int del(String x, int xi) {
return 1;
}
private int min(int a, int b, int c) {
return Math.min(Math.min(a, b), c);
}
}
|
回页首
介绍 Jazzy
迄今为止,我已经介绍了两种拼写检查方法:语音匹配和顺序比较。由于它们各自都没有提供完整的解决方案,所以编写了一个把它们组合起来的算法。下面是从 GNU Aspell 手册中引用的内容:
[Aspell] 背后的秘密来自于整合了 Lawrence Philips 优秀的 metaphone 算法和 Ispell 的靠近遗漏(near miss)策略,它会插入空格或连字符,交换两个相邻字母,改变一个字母,删除一个字母,或者增加一个字母。
Jazzy 是 GPL/LGPL 协议下的基于 Java 的拼写检查器 API,它基于 Aspell 算法,该算法最初是用 C++ 编写的。
Aspell 算法和 Jazzy
如果进行拼写检查的单词不在字典里,那么 Aspell 算法就会假定它是拼写错误的。在这种情况下,算法用以下步骤来建立一个经过排序的修正建议列表:
- 加入拼写错误靠近的语音匹配:加入字典中所有与拼写错误单词语音编码相同的单词, 以及与拼写错误单词的编辑距离小于指定阈值的所有单词。
- 加入与拼写错误单词的“靠近遗漏”(near miss)接近的语音匹配:加入与拼写错误单词只差一个编辑操作的所有单词的语音代码。对于这些代码,加入字典中所有与拼写错误单词语音编码相同的单词, 以及 与拼写错误单词的编辑距离小于指定阈值的单词。
- 最佳猜测:如果没有找到建议,就加入字典中所有与拼写错误的单词的语音代码相同的单词, 以及与拼写错误的单词编辑距离最小的单词。
- 排序:按照编辑距离排序单词,把每一步骤中找到的单词放在一起。
Aspell 算法的优势在于它利用编辑距离的方式,它在单词级别上和语音代码级别上都使用编辑距离。在实践中,这可以形成足够的模糊匹配,从而为拼写错误单词形成良好的修正建议。
编辑距离说明
在 Jazzy 中使用的编辑距离与以前在 Levenshtein 距离中的定义不同。除了替代、删除、插入之外,Jazzy 还包括了交换相邻字母、改变字母大小写的操作。操作的成本是可配置的。缺省的语音编码方式是 Metaphone,但是也可以使用一个语音转换规则文件(请参阅 参考资料),文件以表格的方式定义了像 Metaphone 这样的转换规则。表格驱动的方式使得可以很容易地把基于 Jazzy 的检查器配置为支持其他语言。
回页首
建立拼写检查器
从现在开始,我要把精力放在描述用 Jazzy API 实际建立一个拼写检查器上。清单 6 演示了如何用 Jazzy 编写一个 Java 拼写检查器。
清单6. 一个简单的拼写检查器
import java.io.BufferedReader;
import java.io.File;
import java.io.InputStreamReader;
import java.util.Iterator;
import java.util.List;
import com.swabunga.spell.engine.SpellDictionary;
import com.swabunga.spell.engine.SpellDictionaryHashMap;
import com.swabunga.spell.event.SpellCheckEvent;
import com.swabunga.spell.event.SpellCheckListener;
import com.swabunga.spell.event.SpellChecker;
import com.swabunga.spell.event.StringWordTokenizer;
public class Suggest {
public static class SuggestionListener implements SpellCheckListener {
public void spellingError(SpellCheckEvent event) {
System.out.println("Misspelling: " + event.getInvalidWord());
List suggestions = event.getSuggestions();
if (suggestions.isEmpty()) {
System.out.println("No suggestions found.");
} else {
System.out.print("Suggestions: ");
for (Iterator i = suggestions.iterator(); i.hasNext();) {
System.out.print(i.next());
if (i.hasNext()) {
System.out.print(", ");
}
}
System.out.println();
}
}
}
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: Suggest |
main() 方法用命令行指定的文件建立了一个 SpellDictionary 。 SpellDictionaryHashMap 实现在内存中保存单词,这样比较快,但是对于大型字典不适合。 (对于容易引起内存不足的应用程序,还提供了基于磁盘的实现。) SpellDictionary 被用来构造SpellChecker 对象,在用标准输入填充之前,先用它注册 SpellCheckListener 。拼写检查器通常内嵌在用户驱动的应用程序里,而事件驱动的设计本身就适合这类程序。在这个例子里,侦听器( SuggestionListener )只是在接收到 SpellCheckEvent 事件时,向标准输出写出拼写错误和建议列表。清单 7 显示了一个运行示例。
清单7. 用 Jazzy 进行拼写检查
Enter line to spell check (return to exit): choklut biskit Misspelling: choklut Suggestions: chocolate Misspelling: biskit Suggestions: biscuit Enter line to spell check (return to exit): |
这个例子非常简单,更复杂的应用程序可以利用 Jazzy 对用户字典管理的支持,执行向字典增加单词、忽略单词、用选中的修正自动替换重复错误拼写等任务。要获得详细信息,请参阅 SpellCheckEvent (在 参考资料中)的 API 文档。
回页首
结束语
在撰写这篇文章的时候,Jazzy API 仍然是一个 alpha 软件,版本号为 0.5。作为一个相对年轻的 API,Jazzy 的改进和扩展是公开的。对于初学者,Jazzy 更多地表现出相对于它的近亲 Aspell 所做的一些改进。如果更进一步的话,Jazzy 对于设计上下文感知或语法感知的拼写检查器来说,会是一个理想的框架(使用自然语言处理的一些特性而不是简单的单词列表)。
事实上,Jazzy 是稳固的。虽然对于在 Java 平台上开发拼写检查软件来说仍然是个相对简单的 API,但是因为 Jazzy 是开放源代码的,所以任何人都可对它未来的发展做出贡献。而 API 也可以被用作框架,对其进行扩展后用于内部应用程序开发。请参阅 参考资料一节,了解更多本文所讨论的算法,以及 Java 平台的新拼写检查器 API--Jazzy。
回页首
下载
| 名字 | 大小 | 下载方法 |
|---|---|---|
| j-jazzy.zip | HTTP |