suricata架构——数据结构和代码流程图解
Suricata是一款高性能网络入侵检测防御引擎。该引擎基于多线程,充分利用多核优势。
数据结构
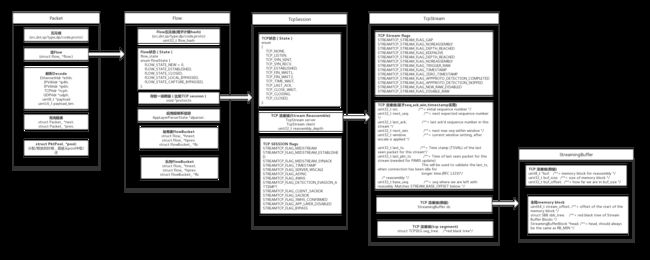
流程
行锁
表锁哈希表,只有一把锁,内存少,实现简单,但是在并发访问时,效率极其低下;
行级锁哈希表则每一行都有一把锁,内存开销大,实现复杂,但是在大并发,高效率的后台服务程序中使用非常广泛。suricata就声称自己可以处理万兆网络,这和多线程架构和更细粒度的锁的机制是分不开的。
先解释一下为什么suricata为什么会使用到行锁,suricata针对snort单线程处理数据包,无法很好利用多核cpu的劣势,开发了多线程架构方式并发处理数据包,而很多数据是线程间共享,所以在很多地方使用行级锁哈希表等其他高效数据结构。第一个行锁使用的地方就是连接管理模块(哈希表,检索速度O(1))
typedef struct FlowBucket_ {
Flow *head; /* 链表头*/
Flow *tail;/* 链表尾*/
/* 行锁类型*/
#ifdef FBLOCK_MUTEX
SCMutex m;
#elif defined FBLOCK_SPIN
SCSpinlock s;
#else
#error Enable FBLOCK_SPIN or FBLOCK_MUTEX
#endif
} __attribute__((aligned(CLS))) FlowBucket;
typedef struct Flow_
{
...
/* 节点锁,提高并发*/
#ifdef FLOWLOCK_RWLOCK
SCRWLock r;
#elif defined FLOWLOCK_MUTEX
SCMutex m;
#else
#error Enable FLOWLOCK_RWLOCK or FLOWLOCK_MUTEX
#endif
...
/* 由hnext hprev 构成双向链表 */
/** hash list pointers, protected by fb->s */
struct Flow_ *hnext; /* hash list */
struct Flow_ *hprev;
...
} Flow;
flow_hash是一个数组,每个FlowBucket 元素由 head 、tail和flow的hnext、hprev 构成一个双向链表,也就是所谓的行。
nf_conntrack_lock
对比linux内核网络协议栈。
nfconntrack中一个最重要的锁,就是全局的nf_conntrack_lock。这个锁的作用是保护全局会话表。当CPU尝试用当前数据包skb进行会话匹配,或者准备插入新的会话时,都需要对nf_conntrack_lock进行上锁。试想,在大流量的环境中,每个经过设备的数据包都要进行会话匹配,在多核的情况下,对这个锁的竞争是非常激烈的。
现在要减小锁的粒度,最直观的想法是,将以前的全局锁,变成基于桶的锁,一个hash桶就使用一个锁。这个想法,从思路上是没有问题的,但是对于会话表来说,其桶的个数一般很大。如果每个桶一个锁的话,会消耗掉不少内存。
一个折中的办法是:每个锁负责保障多个桶的安全,这样就不需要一个桶对应一个锁了,这样既提高了并发性,又没有增加太多内存消耗。这个方法在3.18版本才被引入到linux内核。
参考:
https://suricata.readthedocs.io
http://www.hyuuhit.com/categories/suricata/
https://blog.csdn.net/weixin_34253126/article/details/86442134
https://www.jianshu.com/p/46db186014e0
suricata 源码分析之行锁