初探下一代SIEM核心技术发展趋势
1. 引言
本文乃笔者从2005年接触SIEM到现在的一些感触,也算是抛砖引玉希望引起大家更多的讨论。这里所指的核心技术主要指有一定技术壁垒,承载SIEM产品核心能力的技术点。
2. 传统SIEM产品现状
从2000年左右开始有SIEM( Security Information and Event Management,安全信息与事件管理)产品崭露头角,也涌现出Arcsight这家雄霸Gartner SIEM MQ第一象限多年的现象级产品,但ArcSight从2011年开始在Gartner的领导者象限受到Q1 Lab和NitroSecurity的不断挑战,甚至在2012年首次在技术愿景上被Q1 Lab和NitroSecurity超越。回头看Arcsight、IBM、McAfee、LogRhythm等一线SIEM厂商核心技术区别并不大,只有Splunk因底层为NOSQL数据库略有不同。
其主要的核心技术点包括:
2.1 日志采集
主流SIEM厂商都号称支持数百种安全产品日志采集,其中采集接口多样性、采集器性能、日志聚合、过滤、日志知识库、采集器可靠性都是工程化难题,真正能被广泛稳定使用的日志采集器技术壁垒并不低。
2.2 日志归一化
为了能够关联不同产品类型、厂商的日志,SIEM产品基本都会使用一张固定Meta的事件表将异构日志不同字段映射成为统一的数据模型,同时还会补全、转义大量的字段,也是区分SIEM厂商技术能力的重要指标。能够参与事件关联分析的字段越多,分析能力就越强,这对整个产品的性能也是巨大的考验。国外一线SIEM厂商普遍在几百个字段数量级,国内厂商基本低于100个字段,并且在数据结构设计上偏日志管理,缺少描述安全事件的能力。具体的数据结构以Arcsight事件表为例:
Arcsight事件表总计17个类别,四百个固定字段,还有一百多个预留字段,能够基本涵盖常见安全设备日志字段。数据结构也很清晰,能够非常准确表达一个安全事件。
2.3 实时事件关联分析引擎
实时事件关联分析引擎可谓整个SIEM最核心的技术点。还是以Arcsight为例,实时关联分析引擎是其完全自主开发,以内存RETE 2算法为基础。可用于进行关联的信息包括:安全事件、漏洞信息、监控列表、资产信息、网络信息、之前关联分析的结果等。支持基于规则的关联、基于统计的关联,并且通过在规则中调用监控列表这种方式巧妙的实现了长序列事件复杂关联。第一象限的SIEM厂商都采用这种类似的上下文关联分析技术,国内目前只有少数厂商实现部分能力。
下图是ArcSight关联分析规则配置界面,该界面中配置的关联分析规则用于发现这样的攻击:被攻击主机在攻击成功后,转而向其他主机发起同类型的攻击。这条规则在检测蠕虫传播时很有意义。真正在投入实际运营的关联分析规则远比下图复杂,很多时候会达到上百个逻辑条件,这对实时事件关联分析引擎的性能是巨大挑战,单机能达到5000EPS已经非常优秀。
该规则的细节如下:首先制定两个条件:“condition1”是对前一个攻击事件的描述,说明事件的技术分类是起始于“Exploit”,并且事件类型起始于是“Compromise”或等于“Hostile”;“condition2”是对后一个事件的描述,说明攻击者的区域,设备类型是“IDS”,事件技术分类是“Exploit”,以及攻击目标的区域。然后把这两个条件关联起来:第一个事件的目的地址是第二个攻击事件的源地址,并且第一个事件的目标区域是第二个事件源地址所在的区域。

3. 下一代SIEM
从上述几点可以看出传统SIEM产品数据大部分来源于第三方安全产品日志,完全依赖安全分析师对安全日志的理解和攻击行为的认知,这也是传统SIEM产品实施周期长,使用复杂的主要原因。
随着近几年底层计算平台的不断发展,机器学习、UEBA等技术的兴起,SIEM产品也到了该变革的风口。下面笔者将从以下三点阐述对下一代SIEM产品技术发展趋势的判断。
3.1 SIEM将融合更多安全产品直接采集核心安全数据
从IBM Qradar和LogRhythm自带流量采集分析器开始,SIEM厂商就开始意识到与其花费大力气去适配不怎么样的安全设备日志不如找到安全分析真正所需要的数据,直接采集效率更高、效果更好。如果大家实际做过安全数据分析取证都会有个感受,安全日志中真正有价值的数据并不多。总结起来基本包括这几大类数据:网络活动、主机活动、数据活动、账号活动、邮件活动、漏洞信息、资产信息,能覆盖绝大多数分析场景。其中网络和主机活动信息是传统安全产品难以提供的,也是最有价值的,新一代的SIEM很可能就融合NTA、EDR等产品技术,形成采集、分析一体化的模式。这已经在Interset、Awake、Darktrace这些新兴安全厂商身上得到了体现。
3.2 全新的底层计算平台
如果哪家SIEM厂商计算平台还仅仅是在开源平台上修修补补,那只能说明其工程能力有限。真正有野心的厂商一定会针对安全分析场景需求对底层计算平台进行深度开发,以适应海量数据快速搜索、实时机器学习、图计算等需求,并需要平衡客户复杂环境、水平扩展、成本、性能、售后维护等多方面的要求。假设甲厂商部署一套软件最小化都需要10台硬件服务器,Hadoop、ES、Spark一应俱全。而乙厂商最小化部署只需要一台硬件服务器或虚拟主机即可,技术栈完全掌握在自己手中,可根据性能要求纵向切分功能、横向水平扩展。这两个厂商初次投入和后期维护成本一目了然,在很多项目中这也许就是影响客户决策的决定性因素。
3.3 动态数据模型代替静态数据模型
传统SIEM产品成也”日志归一化”,败也“日志归一化”。因为使用日志归一化技术使得异构安全产品日志关联分析有了可能性,但也为了适配各种日志增加了产品实施复杂度,并且不论事件表设计得再“宽”也难百分之百匹配日志,还可能存在大量冗余空白字段。分析能力都被限制在固定的数据模型中,忽略了针对不同安全场景化应用的计算模型探索,所以在新的技术体系下,我们需要来重新思考这些问题。
利用现在新的一些计算平台,比如Hive可支持Schema on read模式。收集到的各种异构数据可不做任何处理直接存储在分布式文件系统中,作为第一层原始数据存储。第二个存储层称为模型存储层,每个关联数据模型都包括实体-关系-标签和相关算法。每个模型都是为了描述实体和关系的集合而构建的,实体用于描述某个客观的对象,如IP、域名、URL、证书、QQ账号、电话号码、实人等,关系是表示对象和对象之间的联系、事件、行为,一般对应原始数据存储层中的各种日志,如登录成功、访问域名、访问URL、攻击某个IP等。模型中的每个实体和关系都来自一个或多个日志中抽取的数据,模型能够将不同的数据源聚合成一个逻辑视图。实体关系模型中的数据往往是面向知识的,其中实体或关系的每个实例都被指定其意义和上下文聚合信息。
这样所有异构数据都通过一个关联数据模型(STIX就是对威胁进行建模的数据模型)将其集成在一起,以实现利用一个线索扩展调查整个事件。这个关联数据模型不再是完全固定的,而是可以根据不同的场景和业务需求设定不同的关联数据模型。
通过这种全新的分析方法可以建立起一个非常灵活和强有力的安全事件分析平台,分析模型完全与底层数据解耦,并且实体关系是一种业务视角出发的数据建模方法,为分析师提供了一种以安全业务视角的数据发现、模型探索的工具,便于分析师追踪攻击者。
在建立起一个统一的关联数据库后,除了手工检索各种信息以外,还可以通过很多算法来进行更广泛的知识探索来发现隐藏在多层关系后的问题。比如给定几个IP地址或域名寻找这些实体存在的共同路径,这种模式将极大的提升威胁溯源的效率。
此外还可利用关联数据模型中的关系(行为)数据可以对各类实体定义一些高度提炼的特征标识。如受害者实体,标签:已攻陷、SQL注入漏洞,位置标签:北京,业务标签:门户前置。标签呈现出两个重要特征:语义化,人能很方便地理解每个标签含义。这也使得用攻击者和受害者画像模型具备实际意义。能够较好的满足业务需求。每个标签通常只表示一种含义,标签本身无需再做过多文本分析等预处理工作,这为利用机器提取标准化信息提供了便利。
如果厂商还能提供易用的动态数据模型建模工具将大大降低产品实施成本,在保证源数据质量的前提下,有望将原有几个月的日志范式化工作缩短到1-2周内完成。并让安全分析师可以迅速的理解数据,应用数据,支撑安全分析Case快速开发。
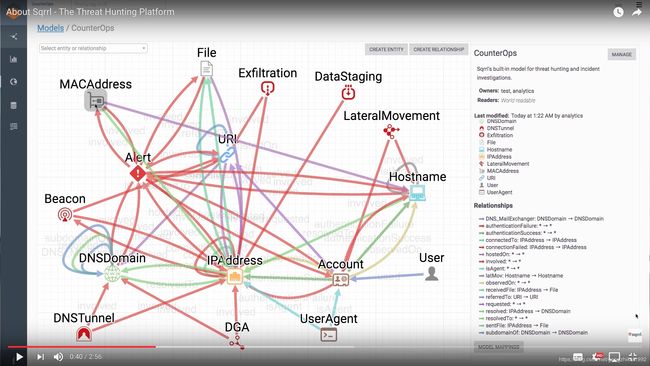
AWS刚4000万美元收购的Sqrrl就是安全厂商中此模式的先行者,下图可见实体、关系集合而构建的模型与传统SIEM以事件为中心的模型有非常大的区别,更贴近安全业务,更符合人的认知。
3.4 AI在SIEM产品中得到广泛应用,但不仅仅是机器学习
笔者最早了解机器学习在安全领域的应用是思睿嘉得的DLP产品,通过机器学习算法一举解决了DLP产品实施中的最痛点-文档内容自动识别分类。之后接触到利用机器学习识别恶意域名、深度学习检测恶意文件等更多的应用,但从SIEM产品对AI的应用来看大部分都集中在某些单点异常活动的检测,像前文所提到的长序列事件复杂关联还未涉及,继续依赖规则引擎。
涉及到多个实体相互作用且关联的复杂安全事件成因复杂、重复率,难以通过大量的重复数据学习来训练算法,需要另辟新路不仅仅研究学习类算法,还可以尝试推理类算法。利用知识图谱、图计算、数据语义化等技术突破复杂安全事件检测的瓶颈。前文所提到的动态数据模型就是基于本体理论设计,非常适合应用这些技术。
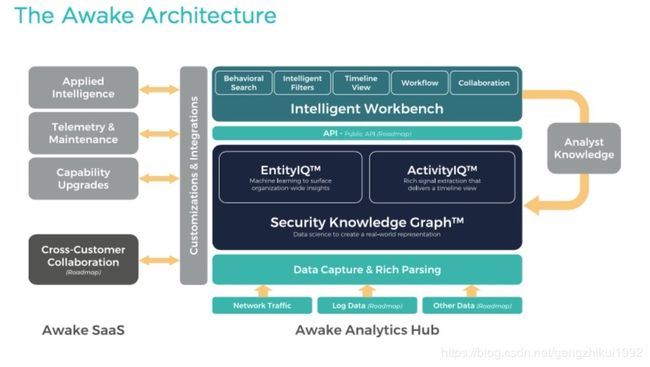
新入围RSA创新沙盒的Awake公司已经将知识图谱技术应用在产品中,自动识别和跟踪真实世界的实体、设备、用户及其属性、关系、行为和活动,观察不寻常行为模式活动的实体聚合。对态势的感知已经从活动识别上升到认知阶段。
4. 参考
转载自https://zhuanlan.zhihu.com/p/38010936,by SecUN安全村