菜鸟写Python-Pycharm执行Scrapy项目报:Scrapy-no active project 和(或)Unknown command: crawl错误
菜鸟写Python:Pycharm执行Scrapy项目报:Scrapy-no active project 和(或)Unknown command: crawl错误
Scrapy和寻常的py文件不同,它不能直接在编辑器中通过run来运行,究其原因是因为 Scrapy 是通过 Scrapy 的解释器 scrapy.exe 完成的(通常的python文件是通过python.exe编译的),因而官方出的执行命令是 " scrapy crawl 项目spider名 ".
1.执行scrapy项目的方法
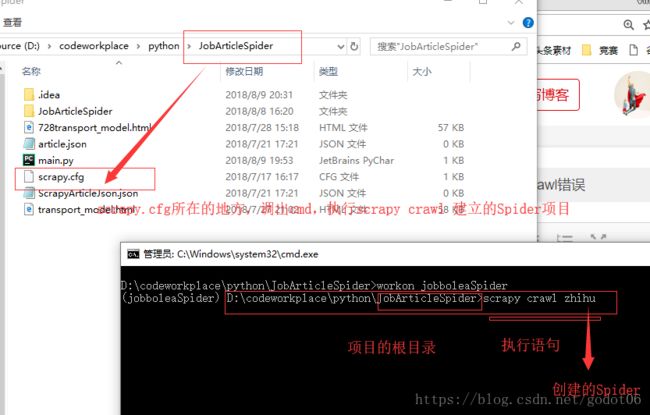
1)命令方式执行:找到项目所在的工作跟目录(根目录下包含爬虫配置文件 scrapy.cfg,即开始通过scrapy startproject 项目,生成项目所在的目录中),通过cmd命令,在命令窗口执行 : scrapy crawl 项目;如:
2)pycharm编辑器执行scrapy项目:(重点)
如前文所述,编辑器Pycharm无法直接的执行scrapy项目,它同样需要借助scrapy crawl spider命令来执行项目,因此,我们就需要借助sys系统包通过execute来执行这条命令(等同于在cmd中执行scrapy crawl spider)。在Pycharm构建执行Scrapy的cmdline通过需要掌握两个关键点:
①保证execute是在项目的根目录执行-----------》因此需要确定文件的地址
②在文件中构建scrapy crawl spider命令
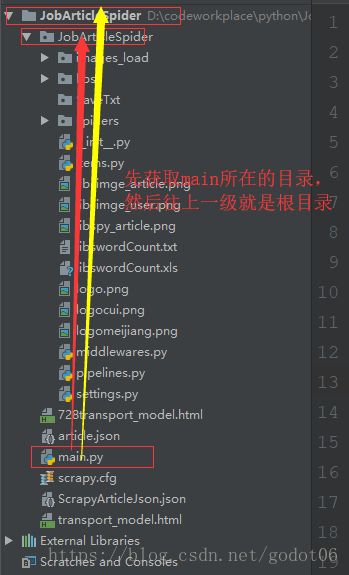
(1)新建main.py文件
掌握上面两个关键点后,我们在scrapy.cfg所在的目录新建一个执行文件,如main.py(命名随意,你也可以命成cmdline.py)。在scrapy.cfg处新建文件是因为,我们的scrapy上一级就是根目录所在的位置,这样方便我们寻址,保证execute在根目录上执行。
(2)导入依赖包:
from scrapy.cmdline import execute
#excute 执行scrapy命令
import os # 用来设置路径
import sys # 调用系统环境,就如同cmd中执行命令一样(3)根据上面的要点1配置执行路径,很关键,我们一定要找到根目录的路径;
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# os.path.abspath(__file__) 获取当前文件所在的路径
# os.path.dirname(os.path.abspath(__file__)) #获取当前路径的上级(父级路径)
# os.path.dirname('D:\codeworkplace\python\JobArticleSpider\main.py')
# sys.path.append() 设置添加项目工程所在的路径,让编译器知道是哪个项目要执行 路径设置两种方法:1.绝对路径 2.相对路径,获取当前项目所在系统的对应目录
(4)通过sys.path.append()添加根目录后,我们就满足了路径的要求,现在我们只需要想cmd中一样执行scrapy crawl spider就行,代码怎么写?通过最开始import的execute包来执行。
execute(["scrapy", "crawl", "zhihu"]) # 这样一行代码就可以了(5)通过写main.py文件后我们就通过run main.py来运行我们的scrapy文件了,如果我们新建了爬虫文件 scrapy genspider jobbole,我们只要在main文件中在新加一个:execute(["scrapy", "crawl", "jobbole"]) 语句即可。
(6)到了这一步,代码部分是已经完成了,但是你执行文件仍有可能保错;
一般报的错误类型是Scrapy-no active project 和(或)Unknown command: crawl错误。这个错误,原因有两个:
一、是可能你设置的路径不是项目的根目录;
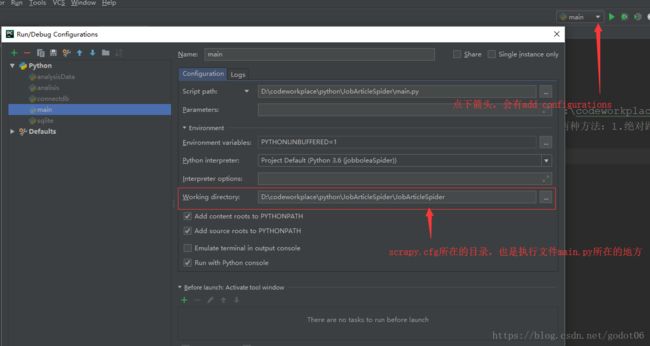
二、编辑器变的工作目录(Work Directory)没有设置好,Work Directory需要设置成scrapy.cfg所在的路径如图。
网上,也有网友说,出现这个错误的原因是没有scrapy.cfg文件,这个情况一般是下面人家的demo丢失了.cfg文件,遇到这个我们在目录下补充这个文件,即可:
