RDD、DataFrame、DateSet基本操作
一,RDD,DataFrame和DataSet
DataFrame参照了Pandas的思想,在RDD基础上增加了schma,能够获取列名信息。
DataSet在DataFrame基础上进一步增加了数据类型信息,可以在编译时发现类型错误。
DataFrame可以看成DataSet[Row],两者的API接口完全相同。
DataFrame和DataSet都支持SQL交互式查询,可以和 Hive无缝衔接。
DataSet只有在Scala语言和Java语言的Spark接口中才支持,在Python和R语言接口只支持DataFrame,不支持DataSet。


二,创建DataFrame
1,通过toDF方法创建
可以将Seq,List或者 RDD转换成DataFrame。



2,通过CreateDataFrame方法动态创建DataFrame
可以通过createDataFrame的方法指定rdd和schema创建DataFrame。
这种方法比较繁琐,但是可以在预先不知道schema和数据类型的情况下在代码中动态创建DataFrame。

3,通过读取文件创建
可以读取json文件,csv文件,hive数据表或者mysql数据表得到DataFrame。





三,创建DataSet
DataSet主要通过toDS方法从Seq,List或者RDD数据类型转换得到,或者从DataFrame通过as方法转换得到。
1,通过toDS方法创建
可以将Seq,List或者 RDD转换成DataFrame。


2,通过DataFrame的as转换方法得到DataSet

四,RDD,DataFrame和DataSet的相互转换
Spark的RDD,DataFrame和DataSet三种数据结构之间可以相互转换。





五,DataFrame/DataSet保存成文件
可以保存成csv文件,json文件,parquet文件或者保存成hive数据表。

六,DataFrame的API交互
DataFrame和DataSet具有完全相同的API,此处演示DataFrame常用的一些API使用。
1,Action操作
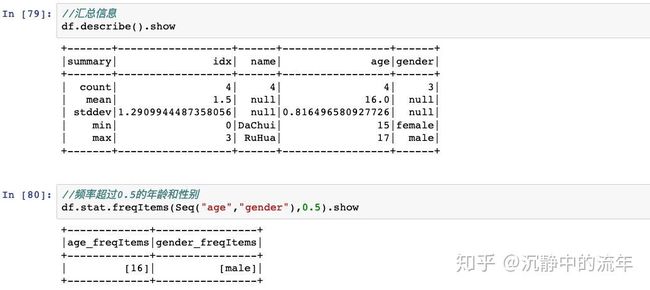
DataFrame的Action操作包括show,count,collect,collectAsList,describe,take,takeAsList,head,first等。




2,类RDD操作
DataFrame支持RDD常用的map,flatMap,filter,reduce,distinct,cache,sample,mapPartitions,foreach,intersect,except等操作。
可以把DataFrame当做数据类型为Row的RDD来进行操作。







3,类Excel操作
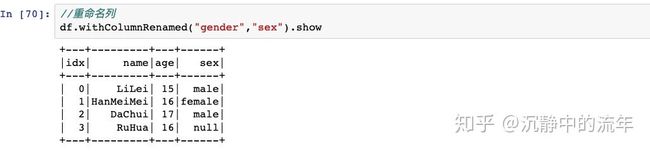
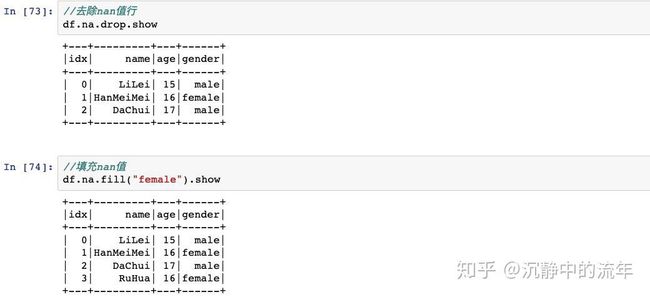
可以对DataFrame进行增加列,删除列,重命名列,排序等操作,去除重复行,去除空行,就跟操作Excel表格一样。






4,类SQL表操作
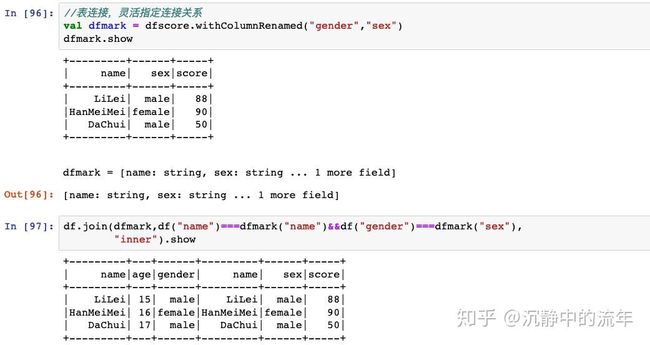
类SQL表操作包括表查询(select,selectExpr,where,filter),表连接(join,union,unionAll),表分组聚合(groupby,agg,pivot)等操作。












七,DataFrame的SQL交互
将DataFrame/DataSet注册为临时表视图或者全局表视图后,可以使用sql语句对DataFrame进行交互。
以下为示范代码。




八,用户自定义函数
SparkSQL的用户自定义函数包括二种类型,UDF和UDAF,即普通用户自定义函数和用户自定义聚合函数。
其中UDAF由分为弱类型UDAF和强类型UDAF,前者可以在DataFrame,DataSet,以及SQL语句中使用,后者仅可以在DataSet中使用。
1,普通UDF


2,弱类型UDAF
弱类型UDAF需要继承UserDefinedAggregateFunction。




3,强类型UDAF
强类型UDAF需要继承自Aggregator,不可注册。


