Pandas各种骚操作
stack()、unstack()、pivot()、pivot_table()
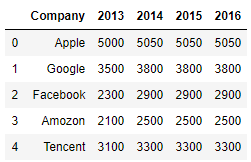
假如以下数据是5个公司4年分别的销售额:
import pandas as pd
df = pd.DataFrame({
"Company": ["Apple", "Google", "Facebook", "Amozon", "Tencent"],
"2013": [5000, 3500, 2300, 2100, 3100],
"2014": [5050, 3800, 2900, 2500, 3300],
"2015": [5050, 3800, 2900, 2500, 3300],
"2016": [5050, 3800, 2900, 2500, 3300]
})
melt()函数
df_melt = df.melt(id_vars=['Company'], var_name='Year', value_name='Sale')

pivot()函数
df_pivot = df_melt.pivot(index="Company", columns=["Year"], values=["Sale"])
df_pivot.index # Index(['Amozon', 'Apple', 'Facebook', 'Google', 'Tencent'], dtype='object', name='Company')
df_pivot.columns # Index(['2013', '2014', '2015', '2016'], dtype='object', name='Year')

pivot_table()函数
pivot_table()函数和pivot()函数类似,但功能更为强大。
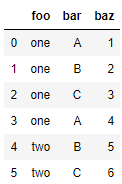
例如如下数据:
df = pd.DataFrame({'foo': ['one','one','one','one','two','two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6]})
df_pivot_table = df.pivot_table(index='foo', columns='bar', values='baz')
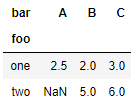
A在one中重复了两次,被默认取了平均值,A在two中不存在,值为NaN。这个聚合函数功能和填充功能可以通过aggfunc和fill_value参数控制,比如:
df_pivot_table = df.pivot_table(index='foo', columns='bar', values='baz', aggfunc=np.sum, fill_value=0)

以上功能如果使用pivot()函数会报错,因为限制了唯一性。此外,pivot_table()的index参数支持列表,而pivot()则会报错。
所以,通常,melt()通常和pivot_table()搭配使用。
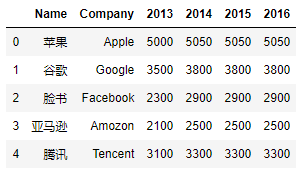
import pandas as pd
df = pd.DataFrame({
"Name": ["苹果", "谷歌", "脸书", "亚马逊", "腾讯"],
"Company": ["Apple", "Google", "Facebook", "Amozon", "Tencent"],
"2013": [5000, 3500, 2300, 2100, 3100],
"2014": [5050, 3800, 2900, 2500, 3300],
"2015": [5050, 3800, 2900, 2500, 3300],
"2016": [5050, 3800, 2900, 2500, 3300]
})
df_melt = df.melt(id_vars=['Name','Company'],var_name='Year',value_name='Sale')
df_pivot_table = df_melt.pivot_table(index=["Name", "Company"], columns=["Year"], values=["Sale"])
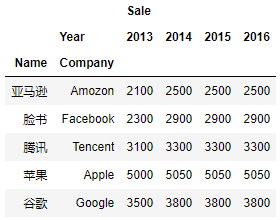
注意的是转换后的index和columns,是一个多维的:
df_pivot_table.index
MultiIndex([('亚马逊', 'Amozon'),
( '脸书', 'Facebook'),
( '腾讯', 'Tencent'),
( '苹果', 'Apple'),
( '谷歌', 'Google')],
names=['Name', 'Company'])
df_pivot_table.columns
MultiIndex([('Sale', '2013'),
('Sale', '2014'),
('Sale', '2015'),
('Sale', '2016')],
names=[None, 'Year'])
可以通过以下方法还原:
df_pivot_table.reset_index(inplace=True, col_level=1)
df_pivot_table.columns = df_pivot_table.columns.get_level_values(1).array
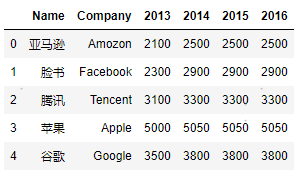
col_level参数表示index放在多重列的哪一列。
找出存在NaN的数据:
df[df.isnull().values==True]
找出NaN值的位置:
df.isnull().stack()[lambda x: x].index.tolist()
删除存在NaN值数据:
df.dropna(axis=0, how='any', inplace=True)
DataFrame的遍历:iterrows(), iteritems(), itertuples()
将Datetime列表转换为字符串类型的日期列表:
df_per_unit[‘date’]是Series对象,里面元素是datetime64[ns]类型。
list(pd.to_datetime(df_per_unit[‘date’].unique()).strftime("%Y-%m-%d"))
df[‘date’].unique():ndarray对象
df.reset_index()
df.set_index()
df.reindex(idx,fill_value=0)
显示不全问题
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示所有列
pd.set_option('display.max_columns', None)
# 整体显示宽度
pd.set_option('display.width', 1000)
# 列显示宽度,默认为50
pd.set_option('max_colwidth', 1000)