爬虫之刃----简化爬虫程序之滚轮子实战(系列三)
前言
这是一些准备工作:
- 了解整个系列的安排
- 了解系列二中的爬虫架构
If you have done, that’s cool !
这篇主要是:
- 介绍需要的技术栈,需要补的东西请戳官方文档。官贴是专业的!
- 推荐个人使用的一些库和轮子
OK!Let’s get a new start!
技术栈合集
提示:所用技术选型均是基于Python语言和Mac操作系统。具体技术细节实现可能稍有不同。
不愿看小编瞎BB的同鞋拿下面的单子走开吧,如下:
- Requests和lxml(主要是tree函数)。Requests用于发送HTTP请求,lxml用于源码的DOM化。同时,有些异常的处理,记得扒官方文档。
- Xpath语法及Google的Xpath Helper工具。XPath可以很方便的拿到源码的文本及标签(name,tag name,id,class)值。写XPath时,使用google的helper会很方便。
- re模块。老生常谈了。但是,我却不怎么用。当需要从文本(多数是字符串)中匹配数据时才使用。写过Xpath的人一般是不喜欢用re的,除了没办法啦。
- selenium和phantomJS。组合使用,解决动态数据爬取(Ajax数据请求的问题)的问题。selenium是模仿浏览器的行为去访问,支持多种浏览器引擎,如Firefox,chrome等。phantomJS不是一个浏览器引擎,但支持同浏览器一样的操作;如,构建DOM模型。
- pymongo模块。写爬虫,还是用NoSQL来存比较好。推荐MongoDB,我就安利一下。
- 代理IP。不加代理,对于快速访问有反爬虫策略的站点而言,会很不利。所以,找个不错的代理商,很重要。我司(新三板上市)给搞的代理IP,每次请求400个代理,能用的就23-45个不等。自己再做代理优化,也很重要。
概括地说完了,下面详述。
Request和lxml
再次声明,学会他们不是本篇的使命。So,去戳官方文档,没有比他们更全更权威的存在了。
Go on !
有些URL直接使用:
import requests
URL = "http://xxxxxxXXXXXX.html"
req = requests.get(URL)
print(req.text)但是,后续加了代理、超时、header等参数时,需要使用类似如下代码:
req = requests.get(url, proxies=proxies, headers=hea, timeout=3)至于,lxml,可以将req.text这样的源码变成DOM树,方便XPath获取元素或文本。例如:
from lxml import etree
import requests
URL = "http://xxxxxxXXXXXX.html"
req = requests.get(URL)
# 将源码变成utf-8格式
req.encoding = "utf-8"
# DOM化
tree = etree.HTML(req.text)
# 获取title,xpath()函数里放的是xpath
title_text = tree.xpath('//html/head/title')
# 循环打印。注意:xpath()的返回值是一个list,里面是DOM节点。记得用title_text[0].text(改数)或者循环打印
for node in title_title:
print(node.text)关于requests和lxml就说这些,其实很简单。Next!
xpath语法及XPath Helper
给出几个xpath语法的例子:
'.//dd[@class="pub-time"]/text()',
'.//dt/a/@puid',
'//dt/a/@company_id',
'//span[@class="icon-pp"]/@class',
'//span[@class="cat-type"]/@class',加点与不加点的结果是不同的,这些语法问题不值得在这里浪费篇幅了。
写的时候一般是需要借助工具—-google Chrome的copy XPath。如下:
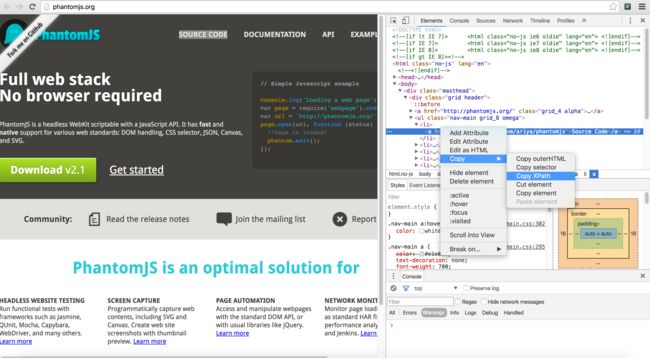
然后,打开XPath Helper【请提前安装】,进行修改调试:
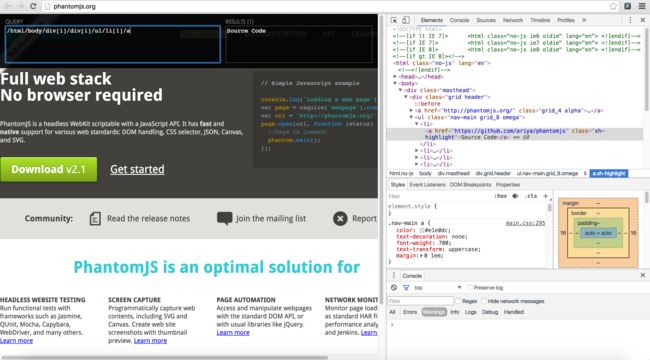
so easy! 如果刚入门,请不要着急,慢慢积累就好!
re模块
这个模块我是最没有发言权的,毕竟用到的不多。但是,写爬虫,re模块不可或缺。
我用它在一堆文本中匹配电话号码。仅此而已。不过,re的价值远比这个大。
之前有个应用场景。我需要判断title里有没有一个词“赶集”,没有便不是我需要的页面,有则是正确的页面。这个时候,没有re模块是真的不行。
骚年,需要用的时候,去找官方文档吧。Next!
selenium和phantomJs
在多数网站中,数据是通过浏览器加载JavaScript后,执行Ajax请求代码获取的。这部分数据是动态加载的,需要用户触发动态加载的条件:如下拉刷新,点击“查看”按钮等等。
使用selenium和phantomJs的好处,如下:
- 不必考虑Ajax的具体执行过程
- 快速获得网页动态加载的数据
对于这两个轮子,皆有各自的官方文档。引一下phantomjs的官方介绍:
PhantomJS is a headless WebKit scriptable with a JavaScript API. It has fast and native support for various web standards: DOM handling, CSS selector, JSON, Canvas, and SVG.
简单的使用,如下:
from selenium import webdriver
# 告知selenium,phantomjs的安装路径/执行路径
PATH = "/Users/tanishindaira/Desktop/spider/ClassifiedSearch/phantomjs-2.1.1-macosx/bin/phantomjs"
# 获取电话的xpath语法。假设:phone是通过javascript动态加载的
phone_xpath = '//*[@id="detail_info"]/div[8]/table/tbody/tr[1]'
# 加载phantomJs,初始化webdriver
req = webdriver.PhantomJS(PATH)
# 进行http的get请求
req.get(link)
# 通过find_element_by_xpath()函数获取动态数据
data = req.find_element_by_xpath(hire_postition_numbers_xpath).text
# 打印
print(data)So, that’s very easy. 这个过程中,还需要学会设置超时,毕竟有些网站的加载速度较慢,而且并不是所有数据都会需要爬取。
对于多数人而言,利用selenium+phantomJs爬取数据,会觉得慢。因为这种方式,是包含了JavaScript脚本加载和执行的时间,也有浏览器引擎初始化和关闭的时间。
慢,是有好处的。
大多数时候,你会主动降低爬虫的爬取效率。因为过快地访问目标站点的服务器会导致:
- 触发对方已有的反爬虫策略
- 占用服务器资源,影响营业时,对方不得不研发反爬虫【大量而长时间爬取】
- 有一定的法律风险
曾有一些前辈说,需要在get请求前加一段代码,如下:
# 设置爬取间隔
time.sleep(random.randint(3, 6))Anyway, 就说到这里。
pymongo
使用MongoDB,在爬取数据时很有必要。特别当你做去重的时候,大量数据检索是比较快的。
Mongo的相关特性,自行官网刷经验吧。只能说,不难。而且需要使用的部分不多。
简单使用如下:
import pymongo
# 建立连接
def conn(self):
# 连接本地. or 连接到云服务器上,带上用户名和密码
# client = pymongo.MongoClient(host="127.0.0.1", port=27017)
# 判断是否有错
if client is None:
logger.warning("mongodb连接失败...")
# 数据库名称
db = client["ganji_zhaopin_proxy"]
# 数据表(collection)名称
collection = db["ganji_proxy_data"]
return collection
# 插入数据
def data_insert(self, data):
# 获得连接
collection = self.conn()
# 防止出错
try:
collection.insert(data)
logger.info("ip不存在,已插入数据...")
except Exception as e:
check_data = self.data_find(data)
# 假设data【map类型】里有ip这个key
if check_data['ip'] == data["ip"]:
logger.info("ip已存在,执行更新操作...")
self.data_update(data)
else:
logger.error("插入数据时,出错:{}".format(e))
def data_find(self, data):
# 获得连接
collection = self.conn()
_id = data['ip']
# 防止出错
try:
result = collection.find_one({'_id': _id})
except Exception as e:
logger.error("查询数据时,出错:{}".format(e))
return None
return result
# 更新数据
def data_update(self, data):
# 获得连接
collection = self.conn()
_id = data['ip']
update_data = {'$set': data}
# 防止出错
try:
collection.update({'_id': _id}, update_data)
except Exception as e:
logger.error("更新数据时,出错:{}".format(e))以上函数,做的是:当用户调用data_insert()函数时,会执行mongo的插入操作。失败的话,检查mongodb中是否已存在。存在话就进行更新操作。
其实,写mongo的代码量不长。就如同mysql一样,有增删改查4个基本功能。
这里当然也会涉及到表结构的设计:
- 不放:当你需要的时候,把不同的的东西放在不同的篮子里,别堆在一起
- 放:相同属性和类目的东西放在一起
其他的没有什么好建议的。当你有了需求,就自然而然有了那个表。而对于有经验的人来说,这些他都提前得知。
代理IP
使用代理IP是必要的。至少这样会保证你的访问次数,除非你使用了劣质代理。使用代理并没有什么诀窍可言,让每次HTTP请求都使用一个有效且不同的代理IP是基本的准则。
原因:
- 代理IP大部分是无法使用的。比如不能访问百度,当然也不能访问你要去的站点
- 代理IP即使有效,可能在过一会儿就失效,有效时间不定
- 每次从服务器请求的代理IP数据可能是相同的,但是不能让http请求每次都用同一个ip。这样会让有效可用的代理ip被目标站点封掉,保证间隔使用。
针对以上的问题,这里有一个不完整的解决方案,仅供参考:
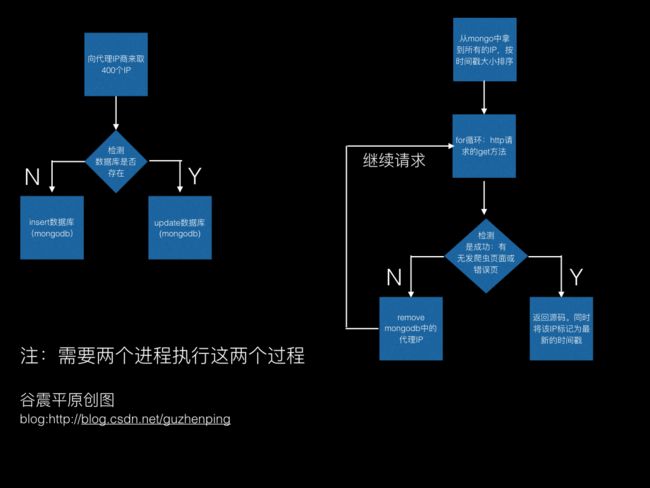
希望,不吝赐教,给出其他的解决方案,谢谢。
结语
系列三告一段落。主要是介绍了需要使用的技术栈,给出一些仅供参考的经验。
接下来,进入系列四—-赶集网爬取案例,需要使用以上所有的技术栈。
OK,让我们翻开一个新的篇章!
欢迎大家关注我的微信公众号“谷震平的专栏”,获取更多技术分享资料!
打开微信,扫一扫吧!
