可狱可囚的爬虫系列课程 09:通过 API 接口抓取数据
前面已经讲解过 Requests 结合 BeautifulSoup4 库抓取数据,这种方式在抓取数据时还是比较方便快捷的,但是这并不意味着所有的网站都适合这种方式,并且这也不是抓取数据的最快方式,今天我们来讲一种更快速的获取数据的方式,通过 API 接口抓取数据。
一、API接口概述
API 接口是负责传递数据的,在现今互联网已存在的网站中,除了极个别非常古老的网站,大部分的网站都会采用 API 接口进行数据的传输。那么为什么 API 接口这么受欢迎呢,那当然是其带来了很多的好处,最直观的便是极大地节省了开发的成本。
举个例子:一个团队想制作一个游戏,在这个游戏里有付费的功能,那么相应的就需要有一个提供支付服务的平台,众所周知,支付平台是需要有能力去保证资金交易安全且需要有资质的,普通的团队压根搞不起啊,所以对于这个团队来说花钱买现成的支付平台的服务是最好的选择,那么这个服务是以何种方式介入的呢,答案就是 API 接口,通过这个 API 接口实现交易功能及交易数据的传递。 所以网站中显示的数据也是可以通过 API 接口从数据库传递到网站中的。
那么如何利用好 API 接口获取数据,这便是我们本文要学习的内容。
二、API接口结构
API 接口长什么样子呢,请看示例:https://v.api.aa1.cn/api/api-qq-gj/index.php?qq=xxxxx&num=xx&vip=xxx
上方这个 URL 便是一个 API 接口,它是由请求地址和请求参数两部分构成的,请求地址和请求参数之间使用?连接,请求参数要写成key=value的形式(我们常说的键值对形式),如果同时有多个请求参数,请求参数之前使用&连接。
请求地址,顾名思义就是你请求的服务器的入口;
请求参数,就是按照设定你得告诉服务器你要做什么。
相信大家也尝试打开这个链接了,结果发现什么也没有,甚至还报错,那是因为这个 API 接口的请求参数设定不正确,使用 API 接口就需要保证请求参数的正确性。
上面的 API 接口其实是一个QQ价格评估接口,这是它需要的参数信息以及返回结果信息:
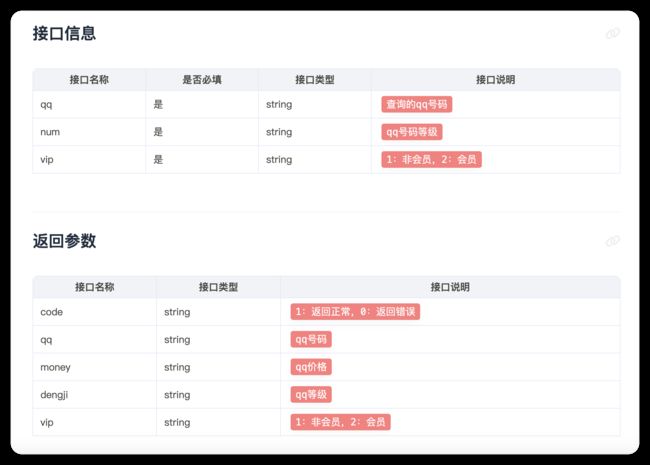
我们只需要按照上图的信息稍微修改下,便能得到一个正确的可访问的 API 接口:https://v.api.aa1.cn/api/api-qq-gj/index.php?qq=1766935706&num=68&vip=1,这是我用自己的 QQ 做的实例演示,结果如下,这就是此 API 接口实现的功能以及传递的数据。

那么 API 接口中的数据是如何被爬虫获取到呢?
三、Requests请求API
API 接口本质也是一个 URL,所以也是可以使用 Requests 进行请求的。
import requests
API_URL = 'https://v.api.aa1.cn/api/api-qq-gj/index.php?qq=1766935706&num=71&vip=1'
Headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url=API_URL, headers=Headers, verify=False)
result = response.text if response.status_code == 200 else '状态码异常'
print(result)
我们请求这个 API 接口的结果如下图所示。
注意:上述代码中有一个还未曾涉及到的知识点,我暂时先给大家做一个简单的解释:Requests 请求时,我在 get 方法中添加了一个 verify=False,表示移除 SSL 认证,因为我们请求的这个 API 接口没有 SSL 证书,不添加 verify=False 会报错,后续我们会出一篇文章单独进行说明。

至此,我们使用爬虫获取到了一个 API 接口中的数据,在下一篇文章中我将带大家学习如何在一个网页中寻找 API 接口从而将数据快速无误的抓取下来。