Facebook AI何恺明又一新作 | 研究MoCo(动量对比学习),超越Hinton的SimCLR,刷新SOTA准确率...
点击蓝字关注我们


扫码关注我们
公众号 : 计算机视觉战队
扫码回复:无监督,获取下载链接

经常闲逛何老师主页,应该有所察觉,Facebook AI的何凯明老师有来一个新作,这次更加猛烈,远远比Hinton老师的SimCLR还要优秀,今天“计算机视觉研究院”一起和大家来分享,一起来学习!
简述
Contrastive unsupervised learning(对比式无监督学习)在近几年里取得了较快的进展,也被很多研究者所接受所认可。例如何凯明老师的MoCo(动量对比)和Hinton老师的SimCLR。
今天分享中,是何老师MoCo的第二版本,其通过在MoCo框架中实现SimCLR的两个设计改进来验证它们的有效性。通过对MoCo的简单调整,作者使用一个MLP投影头和更多的数据增强操作。最终,建立了比SimCLR更强的基准,并且不需要大量的训练,何老师希望更容易获得最先进的无监督学习研究,代码已经被公开。

后续我们“计算机视觉协会”会在线给大家分享实践过程,有兴趣的可以加入我们!
温习无监督
2013年Bengio等人发表了关于表示学习( representation learning)的综述,将表示学习定义为“学习数据的表征,以便在构建分类器或其他预测器时更容易提取有用的信息”,并将无监督特征学习和深度学习的诸多进展纳入表示学习的范畴。
DeepMind在最新论文Representation Learning with Contrastive Predictive Coding中,提出一种新的表示学习方法——对比预测编码(Contrastive Predictive Coding, CPC),将其应用于各种不同的数据模态、图像、语音、自然语言和强化学习,证明了相同的机制能够在所有这些领域中学习到有意义的高级信息,并且优于其他方法。
后来,DeepMind基于最先进的BigGAN模型构建了BigBiGAN模型,通过添加编码器和修改鉴别器将其扩展到表示学习。BigBiGAN表明,“图像生成质量的进步转化为了表示学习性能的显著提高”。研究人员广泛评估了BigBiGAN模型的表示学习和生成性能,证明这些基于生成的模型在ImageNet上的无监督表示学习和无条件图像生成方面都达到了state of the art的水平。
这篇论文在Twitter上引发很大反响。GAN发明人Ian Goodfellow说:“很有趣,又回到了表示学习。我读PhD期间,我和大多数合作者都对作为样本生成的副产品的表示学习很感兴趣,而不是样本生成本身。”

背景
通过该领域有身份的研究领头人对此深入研究,无监督表示学习得到更多研究员的研究,取得了令人鼓舞的进展。,目前从图像中进行无监督表示学习的研究大都集中在一个中心概念上:对比学习。
今天分享的是在MoCo框架内建立了更强的基线,SimCLR中使用的两个设计改进:
MLP投影头
更强的数据增强
与MoCo和SimCLR框架是正交的,当与MoCo一起使用时,它们会带来更好的图像分类和目标检测迁移学习结果。此外,MoCo框架可以处理大量的负样本,而不需要大量的训练批。与需要TPU支持的SimCLR的4k∼8kbatches相比,“MoCo v2”基线可以在典型的8-GPU机器上运行,并且获得比SimCLR更好的结果。
Contrastive learning
对比学习方解释:“Contrastive learning is a framework that learns similar/dissimilar representations fromdata that are organized into similar/dissimilar pairs”这可以表述为字典查找问题,一种有效的对比损失函数,称为InfoN CE,如下:
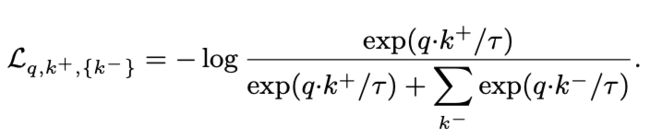
对比损失可以通过不同的机制来最小化,这些机制是key如何被维护。在端到端的机制中(下图a)。negative keys来自同一批,并通过反向传播进行端到端的更新。SimCLR是基于这一机制,需要大批量提供一大组negatives。在MoCo机制中(下图b), 在队列中维护negative keys,每个训练批中只编码queriesand positive keys。采用动量编码器来提高当前和早期keys之间的表示一致性。MoCo将从negatives的数量减少批大小。

Improved designs
SimCLR在三个方面改进了实例识别的端到端变体:
能够提供更多负样本的更大的批处理(4k或8k);
将输出的fc投影头[16]替换为MLP头;
数据扩充能力增强。
在MoCo框架中,大量的负样本是现成的;MLP头和数据扩充与对比学习的实例化方式是正交的。
实验对比
首先是作者在本次实验的参数设置:

大概意思就是:在ImageNet数据集上进行无监督学习。首先ImageNet线性分类——对特征进行冻结,训练监督线性分类器;然后迁移到VOC目标检测:Faster R-CNN在VOC 07+12训练集上进行端到端微调,在VOC 07测试集上使用MSCOCO的标准进行评估。所有结果使用标准尺寸的ResNet-50网络。
MLP head
在【Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learningof visual representations. arXiv:2002.05709, 2020】之后,将MoCo中的FC Head替换为2层的MLP head。这只影响到非监督训练阶段;线性分类或迁移阶段不使用这个MLP head。【A simple framework for contrastive learning of visual representations】之后寻找一个最佳的τ关于ImageNet线性分类准确率。

Augmentation
通过在【A simple framework for contrastive learning of visual representations】中加入模糊增强来扩展【Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and RossGirshick. Momentum contrast for unsupervised visual representation learning. arXiv:1911.05722, 2019】中的原始增强处理。单独的额外增加(即(no MLP)将ImageNet上的MoCo基线提高了2.8%,达到63.4%,见下表(b)。
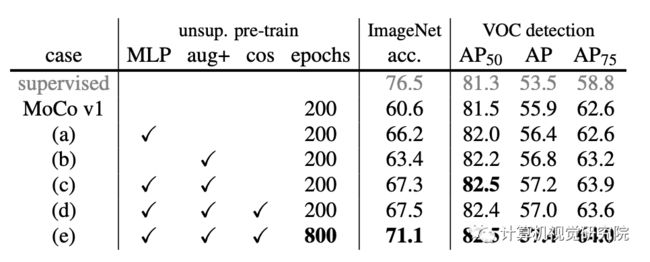
更有趣的是,它的检测准确率比单独使用MLP要高,上表(b) VS (a),尽管线性分类准确度要低得多(63.4%比66.2%)。这说明线性分类精度与检测中的迁移性能不是单调相关的。对于MLP,额外的增强将ImageNet的精度提高到67.3%,见上表(c)。
Comparison with SimCLR
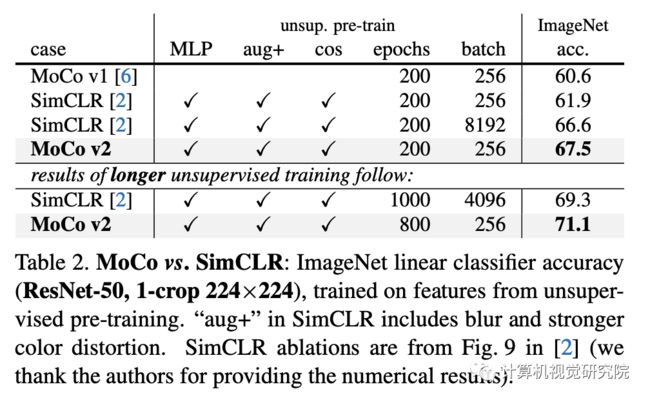
Computational cost
最后还给出了实现的内存和时间成本。端到端案例反映了GPU中的SimCLR成本。
即使在高端的8-GPU机器上,4k的批处理大小也是难以处理的。而且,在相同的批处理大小为256的情况下,端到端变体在内存和时间上仍然更昂贵,因为它向后传播到q和k编码器,而MoCo只向后传播到q编码器。

如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码加入我们