谷歌Hinton团队最新力作:让ImageNet无监督学习的指标提升了 7-10%,可媲美有监督学习的效果
如今,ImageNet上图像识别精度的性能提升通常一次只有零点几个百分点,而来自谷歌研究人员的最新研究,如图灵奖获得者杰弗里·辛顿(Geoffrey Hinton)已经将无监督学习的指数提高了7-10%,甚至可以与有监督学习的效果相媲美。

Geoffrey Hinton领导的研究小组最近提出的无监督SimCLR方法立即引起广泛关注:
Geoffrey Hinton表明SimCLR是一种简单明了的方法,它允许人工智能在没有类标记的情况下学习可视化表示,并能达到有监督学习的精度。本文作者指出,在ImageNet上对1%的图像标签进行微调后,SimCLR可以达到85.8%的前5位精度,仅用1%的AlexNet标签就优于后者。

介绍
了SimCLR:一种用于视觉表示的对比学习的简单框架。作者简化了最近提出的对比自我监督学习算法,而无需专门的架构或存储库。为了理解什么使对比预测任务能够学习有用的表示,我们系统地研究了框架的主要组成部分。
我们发现:
(1)数据扩充的组合在定义有效的预测任务中起着至关重要的作用
(2)在表示和对比损失之间引入可学习的非线性转换,实质上改善了学习表示的质量
(3)与监督学习相比,对比学习受益于更大的批量和更多的训练步骤。通过结合这些发现,我们能够轻松超过ImageNet上用于自我监督和半监督学习的方法。由Sim-CLR学习的经过自我监督表示训练的线性分类器达到了76.5%的top-1准确性,相对于以前的最新水平有7%的相对改进,与监督的ResNet-50的性能相匹配。当仅对1%的标签进行微调时,我们就可以达到85.8%的top-5精度,其性能要比AlexNet少100倍。
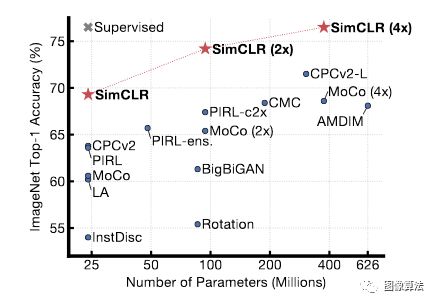
图1.使用不同的自我监督方法(在ImageNet上预先训练)学习的表示形式上训练的线性分类器的ImageNet top-1准确性 灰色十字表示受监管的ResNet-50。
方法
在最近的对比学习算法的启发下,SIMCLR通过在隐藏空间中通过对比度的损失最大化相同数据示例的不同增强视图之间的一致性来学习表示。具体来说,该框架包括四个主要部分:
-
随机数据增强模块,可以对任意给定的数据样本进行随机变换,得到同一个样本的两个相关视图,分别表示为x~i和x~j,我们将其视为正对
-
一个基本的神经网络编码器f(·),它从增强的数据中提取表示向量;
-
一个小的神经网络投影头g(·),它将表示映射到对比度损失空间;
-
为对比度预测任务定义的对比度损失函数。
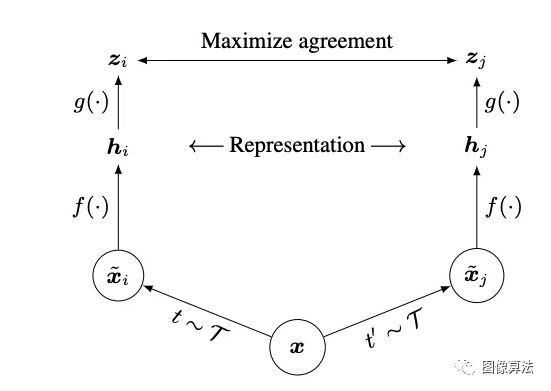
图2:用于视觉表示的对比学习的简单框架
SimCLR 学习算法如下:

算法原理总结如下:
-
随机抽取一小批
-
为每个示例绘制两个独立的增强函数
-
使用两个增强机制为每个示例生成两个相互关联的视图
-
在排除其他示例的同时,使相关视图相互吸引

更大批量训练
我们不使用存储库训练模型。取而代之的是,我们将训练批次的大小从N更改为256至8192.从两个扩充视图的8192批次的每个正对中,我们可以得到16382个负样本。使用标准SGD、动量和线性学习率缩放(Goyal)时,进行大批量训练可能会不稳定。为了稳定训练,我们对所有批次大小都使用LARS优化器(You et al。,2017)。我们使用Cloud TPU对模型进行训练,根据批次大小使用32至128个核。
数据增强
尽管数据增强在有监督和无监督的表征学习中得到了广泛的应用,但它并没有被视为定义对比学习任务的系统方法。许多现有的方法通过改变体系结构来定义对比度预测任务。
本文的研究人员证明,通过对目标图像执行简单的随机裁剪(调整大小),可以避免以前的复杂操作,从而创建一系列包含上述两个任务的预测任务,如图3所示。这种简单的设计选择使得将预测任务与其他组件(如神经网络体系结构)分离很容易。

图3实心矩形是图像,虚线矩形是随机作物

图4研究的数据扩充运算符的插图 每次扩充都可以使用一些内部参数(例如旋转度,噪声水平)随机转换数据。请注意,我们仅对这些算子进行了消融测试,用于训练模型的增强策略仅包括随机裁剪(具有翻转和调整大小),颜色失真和高斯模糊。
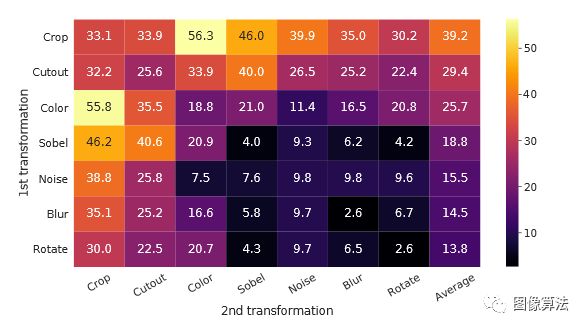
图5单个或组合的数据扩充下的线性评估(ImageNet top-1准确性),仅适用于一个分支。对于除最后一列以外的所有列,对角线条目对应于单个变换,非对角线条目对应于两个变换的组成(顺序应用), 最后一栏反映该行的平均值。
编码器和投射头的架构
-
大型模型的无监督对比学习优势
-
非线性投影头可改善之前的图层的表示质量
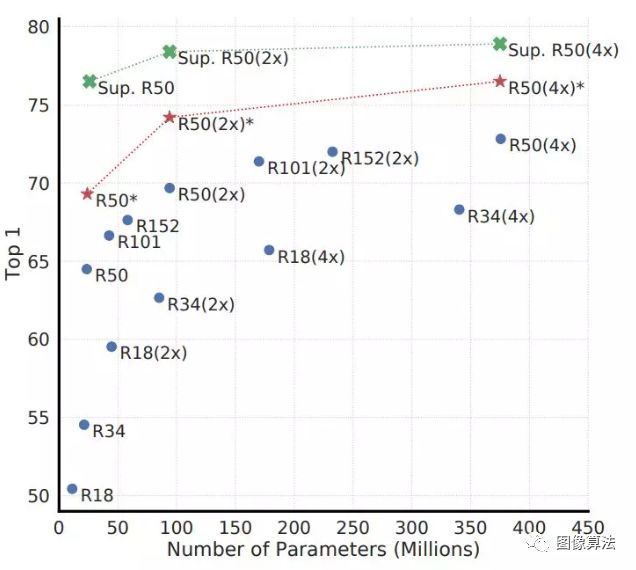
图7:深度和宽度各异的模型的线性评估蓝点模型训练了100个纪元,红星模型训练了1000个纪元,绿色十字形模型监督了ResNets训练了90个纪元.

图8:具有不同投影头g(·)和z = g(h)的各种尺寸的表示的线性评估。这里的表示h(投影之前)为2048维。
损失函数和批大小
温度调节的归一化交叉熵损失优于其他方法。研究人员比较了NT-Xent丢失和其他常用的对比丢失函数,如logistic丢失和边缘丢失。表1显示了目标和损失函数输入的梯度。

表1.负损耗函数及其梯度。
对比学习可以从更大的批量和更长的训练中获益更多。

图9线性评估模型ResNet-50,通过不同的批次大小和时期进行训练 每个栏都是从头开始的。
当前最佳模型的比较
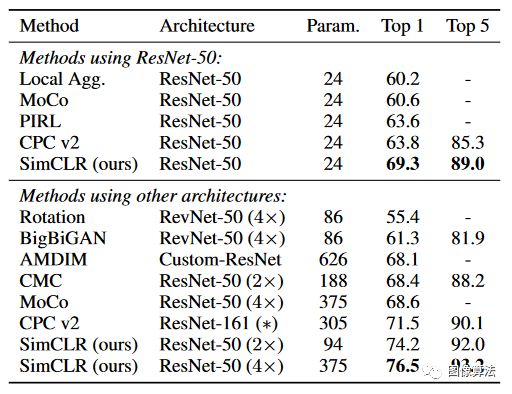
表2.使用不同的自我监督方法学习的表示形式训练的线性分类器的ImageNet精度
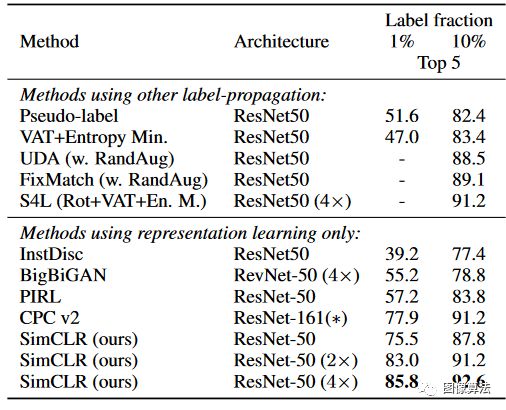
表3.用很少标签训练的模型的ImageNet准确性
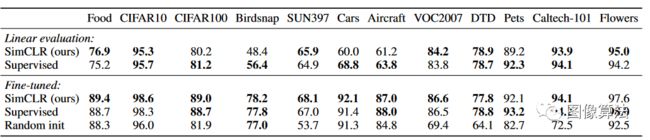
表4:对于在ImageNet上预训练的ResNet-50(4×)模型,我们的自监督方法与12个自然图像分类数据集的监督基线之间的转移学习性能比较。 结果以不显着差于最好的结果(p> 0.05,置换测试)显示为粗体。 有关实验细节和标准ResNet-50的结果.
结论
作者为对比视觉表示学习提供了一个简单的框架及其实例化,细研究了其组成部分,并展示了不同设计选择的影响。通过结合我们的发现,我们比以前的自我监督,半监督和转移学习方法有了很大的改进。我们的结果表明,先前一些自我监督方法的复杂性对于获得良好的表现不是必需的。我们的方法与ImageNet上的标准监督学习的不同之处仅在于数据增强的选择,网络末端使用非线性投射头以及损失函数。这种简单框架的优势表明,尽管最近兴趣激增,但自我监督学习仍被低估了。
论文地址:
https://arxiv.org/pdf/2002.05709.pdf
更多论文地址源码地址:关注“图像算法”微信公众号
