吴恩达Coursera深度学习课程 deeplearning.ai (2-3) TensorFlow Tutorial--编程作业
可执行源码:https://download.csdn.net/download/haoyutiangang/10496503
TensorFlow Tutorial
1. 探索TensorFlow lib库
导包
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.python.framework import ops
from tf_utils import load_dataset, random_mini_batches, convert_to_one_hot, predict
%matplotlib inline
np.random.seed(1)有用的方法
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[1] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((Y.shape[0],m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:, k * mini_batch_size : k * mini_batch_size + mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size : k * mini_batch_size + mini_batch_size]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size : m]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches * mini_batch_size : m]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)].T
return Y
def predict(X, parameters):
W1 = tf.convert_to_tensor(parameters["W1"])
b1 = tf.convert_to_tensor(parameters["b1"])
W2 = tf.convert_to_tensor(parameters["W2"])
b2 = tf.convert_to_tensor(parameters["b2"])
W3 = tf.convert_to_tensor(parameters["W3"])
b3 = tf.convert_to_tensor(parameters["b3"])
params = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
x = tf.placeholder("float", [12288, 1])
z3 = forward_propagation_for_predict(x, params)
p = tf.argmax(z3)
sess = tf.Session()
prediction = sess.run(p, feed_dict = {x: X})
return prediction简单的小例子
y_hat = tf.constant(36, name='y_hat') # Define y_hat constant. Set to 36.
y = tf.constant(39, name='y') # Define y. Set to 39
loss = tf.Variable((y - y_hat)**2, name='loss') # Create a variable for the loss
init = tf.global_variables_initializer() # When init is run later (session.run(init)),
# the loss variable will be initialized and ready to be computed
with tf.Session() as session: # Create a session and print the output
session.run(init) # Initializes the variables
print(session.run(loss)) # Prints the loss
# 9开发TensorFlow程序的步骤
- 创建待计算的变量(Tensors) : 定义变量的类型和名称(定义占位符)
- 编写变量(Tensors)之间转换的方法: 编写运算结构(运用占位符)
- 初始化变量(Tensors):定义占位符字典feed_dict
- 创建session: 传入结构和占位符字典
- 执行session: 执行上述编写的各项操作
通常,我们计算loss时,先将其定义为一个方法,然后用初始化函数该方法的参数,最后再执行计算,这样我们可以在不改变loss方法的情况下,通过不同的初始化方法计算不同的loss
- session : 创建和执行
a = tf.constant(2)
b = tf.constant(10)
c = tf.multiply(a,b)
print(c)
# Tensor("Mul:0", shape=(), dtype=int32)以上代码报错是因为我们仅仅定义和传入了数据,但是没有执行,想要看到执行的结果,需要用session执行
sess = tf.Session()
print(sess.run(c))
# 20谨记: 占位符,定结构,初始化,建session,执行session
- 占位符的运用 : placeholders and feed_dict
- placeholders: 占位符,定义占位符的类型和名称
- 定运算表达式的结构
- feed_dict: 初始化占位符的字典,键值对
# Change the value of x in the feed_dict
x = tf.placeholder(tf.int64, name = 'x')
print(sess.run(2 * x, feed_dict = {x: 3}))
sess.close()
# 6定结构的时候是告诉tensorflow如何建立一张图,在 session.run() 时再把结构连同填充结构占位符的feed_dict传过去。
1.1 线性函数
练习:实现 Y = WX + b,其中 W, X 为随机矩阵,b为随机向量
W:(4,3) X:(3,1) b(4,1)
定义 X 常量的方法:
X = tf.constant(np.random.randn(3,1), name = "X")可能有用的函数
- tf.matmal(…, …) 矩阵相乘
- tf.add(…, …) 加法
- np.random.randn(…) 随机初始化
# GRADED FUNCTION: linear_function
def linear_function():
"""
Implements a linear function:
Initializes W to be a random tensor of shape (4,3)
Initializes X to be a random tensor of shape (3,1)
Initializes b to be a random tensor of shape (4,1)
Returns:
result -- runs the session for Y = WX + b
"""
np.random.seed(1)
### START CODE HERE ### (4 lines of code)
X = tf.constant(np.random.randn(3,1), name = "X")
W = tf.constant(np.random.randn(4,3), name = "W")
b = tf.constant(np.random.randn(4,1), name = "b")
Y = tf.add(tf.matmul(W, X), b)
### END CODE HERE ###
# Create the session using tf.Session() and run it with sess.run(...) on the variable you want to calculate
### START CODE HERE ###
sess = tf.Session()
result = sess.run(Y)
### END CODE HERE ###
# close the session
sess.close()
return result
#########################################################
print( "result = " + str(linear_function()))
# result = [[-2.15657382]
# [ 2.95891446]
# [-1.08926781]
# [-0.84538042]]1.2 计算 sigmoid
TensorFlow 框架提供了很多常用的函数,比如 tf.sigmoid 和 tf.softmax,下面我们自己实现以下sigmoid函数。
1. 定义占位符变量: tf.placeholder(tf.float32, name = “…”)
2. 定义运算结构: tf.sigmoid(…)
3. 执行session: sess.run(…, feed_dict = {x: z})
有两种典型的方式来实现session
- Method1
sess = tf.Session()
# Run the variables initialization (if needed), run the operations
result = sess.run(..., feed_dict = {...})
sess.close() # Close the session- Method2
with tf.Session() as sess:
# run the variables initialization (if needed), run the operations
result = sess.run(..., feed_dict = {...})
# This takes care of closing the session for you :)完成练习
# GRADED FUNCTION: sigmoid
def sigmoid(z):
"""
Computes the sigmoid of z
Arguments:
z -- input value, scalar or vector
Returns:
results -- the sigmoid of z
"""
### START CODE HERE ### ( approx. 4 lines of code)
# Create a placeholder for x. Name it 'x'.
x = tf.placeholder(tf.float32, name = "x")
# compute sigmoid(x)
sigmoid = tf.sigmoid(x)
# Create a session, and run it. Please use the method 2 explained above.
# You should use a feed_dict to pass z's value to x.
with tf.Session() as sess:
# Run session and call the output "result"
result = sess.run(sigmoid, feed_dict = {x:z})
### END CODE HERE ###
return result
#########################################################
print ("sigmoid(0) = " + str(sigmoid(0)))
print ("sigmoid(12) = " + str(sigmoid(12)))
# sigmoid(0) = 0.5
# sigmoid(12) = 0.999994总结
- 创建占位符
- 定义运算结构
- 初始化占位符字典
- 创建session并执行,传入结构和占位符字典
1.3 计算成本函数
计算交叉熵成本
for i = 1…m:
这个函数可以直接实现:tf.nn.sigmoid_cross_entropy_with_logits(logits = …, labels = …)
其中 logits = a, label = y
下面练习:
也就是logits = a = sigmoid(z)
# GRADED FUNCTION: cost
def cost(logits, labels):
"""
Computes the cost using the sigmoid cross entropy
Arguments:
logits -- vector containing z, output of the last linear unit (before the final sigmoid activation)
labels -- vector of labels y (1 or 0)
Note: What we've been calling "z" and "y" in this class are respectively called "logits" and "labels"
in the TensorFlow documentation. So logits will feed into z, and labels into y.
Returns:
cost -- runs the session of the cost (formula (2))
"""
### START CODE HERE ###
# Create the placeholders for "logits" (z) and "labels" (y) (approx. 2 lines)
z = tf.placeholder(tf.float32, name = "z")
y = tf.placeholder(tf.float32, name = "y")
# Use the loss function (approx. 1 line)
cost = tf.nn.sigmoid_cross_entropy_with_logits(logits = z, labels = y)
# Create a session (approx. 1 line). See method 1 above.
sess = tf.Session()
# Run the session (approx. 1 line).
cost = sess.run(cost, feed_dict = {z:logits, y:labels})
# Close the session (approx. 1 line). See method 1 above.
sess.close()
### END CODE HERE ###
return cost
#########################################################
logits = sigmoid(np.array([0.2,0.4,0.7,0.9]))
cost = cost(logits, np.array([0,0,1,1]))
print ("cost = " + str(cost))
# cost = [ 1.00538719 1.03664088 0.41385433 0.39956614]1.4 使用 One Hot 编码
很多时候我们需要将一个数字向量(每个数字表示一个类别),转化为类别矩阵,其中向量的每一个值对应矩阵中的一个列向量,列向量中命中的类别为1,其他为0,这种表示方法称为“One Hot”。(1的位置就好像一个热点)

在tensorflow中实现:tf.one_hot(labels, depth, axis)
使用OneHot的一个小例子
# GRADED FUNCTION: one_hot_matrix
def one_hot_matrix(labels, C):
"""
Creates a matrix where the i-th row corresponds to the ith class number and the jth column
corresponds to the jth training example. So if example j had a label i. Then entry (i,j)
will be 1.
Arguments:
labels -- vector containing the labels
C -- number of classes, the depth of the one hot dimension
Returns:
one_hot -- one hot matrix
"""
### START CODE HERE ###
# Create a tf.constant equal to C (depth), name it 'C'. (approx. 1 line)
C = tf.constant(value = C, name = "C")
# Use tf.one_hot, be careful with the axis (approx. 1 line)
one_hot_matrix = tf.one_hot(labels, C, axis = 0)
# Create the session (approx. 1 line)
sess = tf.Session()
# Run the session (approx. 1 line)
one_hot = sess.run(one_hot_matrix)
# Close the session (approx. 1 line). See method 1 above.
sess.close()
### END CODE HERE ###
return one_hot
#########################################################
labels = np.array([1,2,3,0,2,1])
one_hot = one_hot_matrix(labels, C = 4)
print ("one_hot = " + str(one_hot))
# one_hot = [[ 0. 0. 0. 1. 0. 0.]
# [ 1. 0. 0. 0. 0. 1.]
# [ 0. 1. 0. 0. 1. 0.]
# [ 0. 0. 1. 0. 0. 0.]]1.5 0值初始化和1值初始化
Tensorflow中:tf.zeros(shape) tf.ones(shape) 返回一个数组
小例子
# GRADED FUNCTION: ones
def ones(shape):
"""
Creates an array of ones of dimension shape
Arguments:
shape -- shape of the array you want to create
Returns:
ones -- array containing only ones
"""
### START CODE HERE ###
# Create "ones" tensor using tf.ones(...). (approx. 1 line)
ones = tf.ones(shape)
# Create the session (approx. 1 line)
sess = tf.Session()
# Run the session to compute 'ones' (approx. 1 line)
ones = sess.run(ones)
# Close the session (approx. 1 line). See method 1 above.
sess.close()
### END CODE HERE ###
return ones
#########################################################
print ("ones = " + str(ones([3])))
# ones = [ 1. 1. 1.]2 使用 Tensorflow 构建你的第一个神经网络
2.0 问题陈述:手势数据集
我们利用一下午的时间玩了一个小游戏,给0-5的手势拍照,编写手势数字识别程序,非常好玩,你也来试试吧。
- 训练集: 1080张手势图片(64, 64),0-5每种手势图片180张
- 测试集: 120张图片(63, 64), 0-5每种手势图片20张
这是一个玩乐的小数据集,实际工作中数据集会大很多。
手势图片示意图

导入数据
# Loading the dataset
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()查看数据示例
# Example of a picture
index = 0
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[:, index])))
# y = 5数据预处理
- 图片向量化 (变成一维向量)
- 向量归一化 (除以255)
- 标记数据 Y 进行 one hot 转换
# Flatten the training and test images
X_train_flatten = X_train_orig.reshape(X_train_orig.shape[0], -1).T
X_test_flatten = X_test_orig.reshape(X_test_orig.shape[0], -1).T
# Normalize image vectors
X_train = X_train_flatten/255.
X_test = X_test_flatten/255.
# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6)
Y_test = convert_to_one_hot(Y_test_orig, 6)
#########################################################
print ("number of training examples = " + str(X_train.shape[1]))
print ("number of test examples = " + str(X_test.shape[1]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
# number of training examples = 1080
# number of test examples = 120
# X_train shape: (12288, 1080)
# Y_train shape: (6, 1080)
# X_test shape: (12288, 120)
# Y_test shape: (6, 120)
- 64*64*3 = 12288 其中 3 表示 RGB 三原色
- 模型:LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
- 二元分类用LINEAR, 多元分类用SOFTMAX
2.1 创建占位符
- 创建占位符 X, Y :
- X 表示输入向量, 这里是 64*64*3=12288
- Y 表示输出类的个数,这里0-5,所以是6
# GRADED FUNCTION: create_placeholders
def create_placeholders(n_x, n_y):
"""
Creates the placeholders for the tensorflow session.
Arguments:
n_x -- scalar, size of an image vector (num_px * num_px = 64 * 64 * 3 = 12288)
n_y -- scalar, number of classes (from 0 to 5, so -> 6)
Returns:
X -- placeholder for the data input, of shape [n_x, None] and dtype "float"
Y -- placeholder for the input labels, of shape [n_y, None] and dtype "float"
Tips:
- You will use None because it let's us be flexible on the number of examples you will for the placeholders.
In fact, the number of examples during test/train is different.
"""
### START CODE HERE ### (approx. 2 lines)
X = tf.placeholder(tf.float32, shape = [n_x, None])
Y = tf.placeholder(tf.float32, shape = [n_y, None])
### END CODE HERE ###
return X, Y
#########################################################
X, Y = create_placeholders(12288, 6)
print ("X = " + str(X))
print ("Y = " + str(Y))
# X = Tensor("Placeholder:0", shape=(12288, ?), dtype=float32)
# Y = Tensor("Placeholder_1:0", shape=(6, ?), dtype=float32)2.2 初始化参数
- 使用Xavier Initialization 为 W 进行初始化
- 使用Zero Initialization 为 b 进行初始化
提示
W1 = tf.get_variable("W1", [25,12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b1 = tf.get_variable("b1", [25,1], initializer = tf.zeros_initializer())程序中将随机数的seed设置为1,保证随机数的分布稳定性
# GRADED FUNCTION: initialize_parameters
def initialize_parameters():
"""
Initializes parameters to build a neural network with tensorflow. The shapes are:
W1 : [25, 12288]
b1 : [25, 1]
W2 : [12, 25]
b2 : [12, 1]
W3 : [6, 12]
b3 : [6, 1]
Returns:
parameters -- a dictionary of tensors containing W1, b1, W2, b2, W3, b3
"""
tf.set_random_seed(1) # so that your "random" numbers match ours
### START CODE HERE ### (approx. 6 lines of code)
W1 = tf.get_variable("W1", [25,12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b1 = tf.get_variable("b1", [25,1], initializer = tf.zeros_initializer())
W2 = tf.get_variable("W2", [12,25], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b2 = tf.get_variable("b2", [12,1], initializer = tf.zeros_initializer())
W3 = tf.get_variable("W3",[6,12], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b3 = tf.get_variable("b3", [6,1], initializer = tf.zeros_initializer())
### END CODE HERE ###
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return parameters
#########################################################
tf.reset_default_graph()
with tf.Session() as sess:
parameters = initialize_parameters()
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
# W1 = 和预期一样,参数还没有被计算
2.3 TensorFlow 中的前向传播
实现前向传播函数:利用 X 和 parameters
- tf.add(…,…) :加法
- tf.matmul(…,…) : 矩阵相乘
- tf.nn.relu(…) : relu 激活函数
注意: 方法结束语z3, 不需要计算a3, 因为在TensorFlow中,最后一层的线性计算被作为输入进入到计算loss函数中。
# GRADED FUNCTION: forward_propagation
def forward_propagation(X, parameters):
"""
Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
### START CODE HERE ### (approx. 5 lines) # Numpy Equivalents:
Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3
### END CODE HERE ###
return Z3
#########################################################
tf.reset_default_graph()
with tf.Session() as sess:
X, Y = create_placeholders(12288, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
print("Z3 = " + str(Z3))
# Z3 = Tensor("Add_2:0", shape=(6, ?), dtype=float32)注意到我们并没有cache任何中间变量,下面你就明白了。
2.4 计算成本函数
如前所述,可以利用下面方法很简单的计算cost。
tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = ..., labels = ...))其中:
- logits: Z3向量(样本数)
- labels: Y向量(分类数)
# GRADED FUNCTION: compute_cost
def compute_cost(Z3, Y):
"""
Computes the cost
Arguments:
Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)
Y -- "true" labels vector placeholder, same shape as Z3
Returns:
cost - Tensor of the cost function
"""
# to fit the tensorflow requirement for tf.nn.softmax_cross_entropy_with_logits(...,...)
logits = tf.transpose(Z3)
labels = tf.transpose(Y)
### START CODE HERE ### (1 line of code)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = labels))
### END CODE HERE ###
return cost
#########################################################
tf.reset_default_graph()
with tf.Session() as sess:
X, Y = create_placeholders(12288, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
print("cost = " + str(cost))
# cost = Tensor("Mean:0", shape=(), dtype=float32)2.5 反向传播 & 参数更新
这里你将会体验到框架的好处,反向传播和参数更新仅需一行代码就可以搞定。
在计算完cost后,你需要创建一个 optimizer 对象,当你运行sess.run的时候需要将cost和optimizer一起传进去,这时,框架会对cost和learning_rate进行优化处理。
梯度下降优化器的定义:
optimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost)执行优化
_ , c = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})这一步将会通过你给出的图形结构的反向来计算反向传播。
注意: 编程的时候,通常使用 “_” 来存储”throwaway”变量,也就是之后不会再用到的临时变量。
这里,_ 表示优化器的评估值,我们并不需要;c 表示cost的值
2.6 构建你的模型
集成上述方法,构建一个模型
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001,
num_epochs = 1500, minibatch_size = 32, print_cost = True):
"""
Implements a three-layer tensorflow neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SOFTMAX.
Arguments:
X_train -- training set, of shape (input size = 12288, number of training examples = 1080)
Y_train -- test set, of shape (output size = 6, number of training examples = 1080)
X_test -- training set, of shape (input size = 12288, number of training examples = 120)
Y_test -- test set, of shape (output size = 6, number of test examples = 120)
learning_rate -- learning rate of the optimization
num_epochs -- number of epochs of the optimization loop
minibatch_size -- size of a minibatch
print_cost -- True to print the cost every 100 epochs
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables
tf.set_random_seed(1) # to keep consistent results
seed = 3 # to keep consistent results
(n_x, m) = X_train.shape # (n_x: input size, m : number of examples in the train set)
n_y = Y_train.shape[0] # n_y : output size
costs = [] # To keep track of the cost
# Create Placeholders of shape (n_x, n_y)
### START CODE HERE ### (1 line)
X, Y = create_placeholders(n_x, n_y)
### END CODE HERE ###
# Initialize parameters
### START CODE HERE ### (1 line)
parameters = initialize_parameters()
### END CODE HERE ###
# Forward propagation: Build the forward propagation in the tensorflow graph
### START CODE HERE ### (1 line)
Z3 = forward_propagation(X, parameters)
### END CODE HERE ###
# Cost function: Add cost function to tensorflow graph
### START CODE HERE ### (1 line)
cost = compute_cost(Z3, Y)
### END CODE HERE ###
# Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer.
### START CODE HERE ### (1 line)
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
### END CODE HERE ###
# Initialize all the variables
init = tf.global_variables_initializer()
# Start the session to compute the tensorflow graph
with tf.Session() as sess:
# Run the initialization
sess.run(init)
# Do the training loop
for epoch in range(num_epochs):
epoch_cost = 0. # Defines a cost related to an epoch
num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
# Select a minibatch
(minibatch_X, minibatch_Y) = minibatch
# IMPORTANT: The line that runs the graph on a minibatch.
# Run the session to execute the "optimizer" and the "cost", the feedict should contain a minibatch for (X,Y).
### START CODE HERE ### (1 line)
_ , minibatch_cost = sess.run([optimizer, cost], feed_dict = {X: minibatch_X, Y: minibatch_Y})
### END CODE HERE ###
epoch_cost += minibatch_cost / num_minibatches
# Print the cost every epoch
if print_cost == True and epoch % 100 == 0:
print ("Cost after epoch %i: %f" % (epoch, epoch_cost))
if print_cost == True and epoch % 5 == 0:
costs.append(epoch_cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# lets save the parameters in a variable
parameters = sess.run(parameters)
print ("Parameters have been trained!")
# Calculate the correct predictions
correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y))
# Calculate accuracy on the test set
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Train Accuracy:", accuracy.eval({X: X_train, Y: Y_train}))
print ("Test Accuracy:", accuracy.eval({X: X_test, Y: Y_test}))
return parameters
#########################################################
parameters = model(X_train, Y_train, X_test, Y_test)
# Cost after epoch 0: 1.855702
# Cost after epoch 100: 1.016458
# Cost after epoch 200: 0.733102
# Cost after epoch 300: 0.572940
# Cost after epoch 400: 0.468774
# Cost after epoch 500: 0.381021
# Cost after epoch 600: 0.313822
# Cost after epoch 700: 0.254158
# Cost after epoch 800: 0.203829
# Cost after epoch 900: 0.166421
# Cost after epoch 1000: 0.141486
# Cost after epoch 1100: 0.107580
# Cost after epoch 1200: 0.086270
# Cost after epoch 1300: 0.059371
# Cost after epoch 1400: 0.052228
# Parameters have been trained!
# Train Accuracy: 0.999074
# Test Accuracy: 0.716667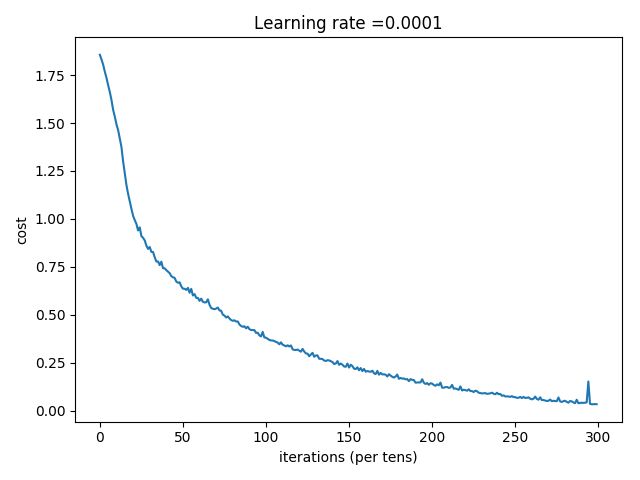
思考
- 从准确率来看,训练集准确率比较高,测试集准确率不足,可以采用L2或者dorpout的正则化方式来改进避免过拟合。
- 考虑将session作为一个代码块来训练模型。
2.7 测试你自己的图片
import scipy
from PIL import Image
from scipy import ndimage
## START CODE HERE ## (PUT YOUR IMAGE NAME)
my_image = "thumbs_up.jpg"
## END CODE HERE ##
# We preprocess your image to fit your algorithm.
fname = "images/" + my_image
image = np.array(ndimage.imread(fname, flatten=False))
my_image = scipy.misc.imresize(image, size=(64,64)).reshape((1, 64*64*3)).T
my_image_prediction = predict(my_image, parameters)
plt.imshow(image)
print("Your algorithm predicts: y = " + str(np.squeeze(my_image_prediction)))
# Your algorithm predicts: y = 3
经过试验可以发现,0-5识别的还不错,不过对于10(赞的手势)将会识别错误,这是亦可能为我们的训练集不包含这个手势,所以模型不认识。我们称之为”不匹配的数据分布”,下一课的”构造机器学习项目” 中会涉及到这些内容。
谨记
- TensorFlow 是一种用于深度学习的编程框架
- TensorFlow 中的两个主要类是 Tensors 和 Operators
- TensorFlow 编程需要遵循下列步骤:
- 创建图结构,包含 Tensors (Variables, Placeholders …) 和 Operations (tf.matmul, tf.add, …)
- 创建 session
- 初始化 session
- run session 来执行graph
- 可以多次运行图(多次迭代)
- 在optimizer上执行session时,反向传播和参数更新是自动完成的