pandas 新手指引
# 10 Minutes to pandas pandas入门教程,面向新手,如需高级教程,移步[pandas cookbook](http://pandas.pydata.org/pandas-docs/stable/cookbook.html#cookbook) 按照约定,一般按照如下形式对pandas进行导入
## 数据的选择 ### 获取数据
### 数据的设置 通过索引匹配插入新的一列
## 处理缺失数据 pandas使用np.nan来表征缺失数据,这些数据在计算时默认不会被使用
## 数据操作 数据操作默认不会使用缺失值 ### 状态操作
### 函数应用 将函数应用到数据上
### 数据SQL风格的连接 merge
### Append 在Dateframe对象尾部添加数据
### 分组聚合 groupby 分组聚合一般而言经历一下步骤: - 按约束条件将数据分组 - 使用某个函数处理分好组的数据 - 将处理好的数据合并在一起
## 重塑和轴向旋转 ### 轴向旋转
### 透视表
## 时间序列 pandas提供了简单有效的处理时间频率的函数。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 使用ipython notebook绘图,加入如下命令
%matplotlib inline# Series 自动生成索引
s = pd.Series([1,2,3,np.nan, 4,5])
sdates = pd.date_range('20160101', periods=6)
datesdf = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
df| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-01 | -0.808397 | -1.548973 | 1.013311 | 1.981536 |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 |
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | -0.088892 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 |
或者,可以通过传递字典来创建Dataframe对象
df2 = pd.DataFrame({
'A': pd.Timestamp('20160701'),
'B': pd.Series(1, index=list(range(4)), dtype='float32'),
'C': np.array([3] * 4, dtype='int32'),
'D': pd.Categorical(['Test', 'Train', 'Test', 'Train']),
'E': 1,
'F': 'foo'
})
df2| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 0 | 2016-07-01 | 1.0 | 3 | Test | 1 | foo |
| 1 | 2016-07-01 | 1.0 | 3 | Train | 1 | foo |
| 2 | 2016-07-01 | 1.0 | 3 | Test | 1 | foo |
| 3 | 2016-07-01 | 1.0 | 3 | Train | 1 | foo |
df2的每一列都拥有不同的类型,可以通过dtypes属性查看
df2.dtypes# head(n) 方法查看前n行
df.head(3)| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-01 | -0.808397 | -1.548973 | 1.013311 | 1.981536 |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 |
# tail(n) 方法查看后n行
df.tail(2)| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | -0.088892 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 |
查看DataFrame的行列信息和数据信息
df.index
df.columnsdf.valuesdf.describe()| A | B | C | D | |
|---|---|---|---|---|
| count | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| mean | -0.178788 | -0.185264 | -0.574532 | 0.527620 |
| std | 1.372179 | 0.846927 | 1.629433 | 1.278357 |
| min | -1.430586 | -1.548973 | -2.775289 | -1.474018 |
| 25% | -1.183440 | -0.626893 | -1.857869 | -0.012595 |
| 50% | -0.664072 | 0.037867 | 0.066804 | 0.494649 |
| 75% | 0.640996 | 0.447926 | 0.527155 | 1.511598 |
| max | 1.966543 | 0.625522 | 1.013311 | 1.981536 |
矩阵的转置
df.T| 2016-01-01 00:00:00 | 2016-01-02 00:00:00 | 2016-01-03 00:00:00 | 2016-01-04 00:00:00 | 2016-01-05 00:00:00 | 2016-01-06 00:00:00 | |
|---|---|---|---|---|---|---|
| A | -0.808397 | 1.966543 | -1.308454 | -1.430586 | -0.519748 | 1.027911 |
| B | -1.548973 | 0.468294 | 0.625522 | -0.732160 | 0.386824 | -0.311089 |
| C | 1.013311 | 0.168445 | -2.465547 | -0.034836 | -2.775289 | 0.646725 |
| D | 1.981536 | -1.474018 | 1.757797 | 0.216295 | -0.088892 | 0.773003 |
索引排序
df.sort_index(axis=1, ascending=False)| D | C | B | A | |
|---|---|---|---|---|
| 2016-01-01 | 1.981536 | 1.013311 | -1.548973 | -0.808397 |
| 2016-01-02 | -1.474018 | 0.168445 | 0.468294 | 1.966543 |
| 2016-01-03 | 1.757797 | -2.465547 | 0.625522 | -1.308454 |
| 2016-01-04 | 0.216295 | -0.034836 | -0.732160 | -1.430586 |
| 2016-01-05 | -0.088892 | -2.775289 | 0.386824 | -0.519748 |
| 2016-01-06 | 0.773003 | 0.646725 | -0.311089 | 1.027911 |
通过某一列值进行排序
df.sort_values(by='C')| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | -0.088892 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 |
| 2016-01-01 | -0.808397 | -1.548973 | 1.013311 | 1.981536 |
# 选取单独一列数据,获取到的数据是Series对象,
# df['A'] 等价与 df.A
df['A']df[0:3]| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-01 | -0.808397 | -1.548973 | 1.013311 | 1.981536 |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 |
df['20160102': '20160104']| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 |
通过标签选择数据。 ps:使用 .at, .iat, .loc, .iloc, .ix属性来实现
df.loc['20160101']df.loc[:, ['A','B']]| A | B | |
|---|---|---|
| 2016-01-01 | -0.808397 | -1.548973 |
| 2016-01-02 | 1.966543 | 0.468294 |
| 2016-01-03 | -1.308454 | 0.625522 |
| 2016-01-04 | -1.430586 | -0.732160 |
| 2016-01-05 | -0.519748 | 0.386824 |
| 2016-01-06 | 1.027911 | -0.311089 |
通过标签来切片
df.loc['20160102':'20160103', ['B','C']]| B | C | |
|---|---|---|
| 2016-01-02 | 0.468294 | 0.168445 |
| 2016-01-03 | 0.625522 | -2.465547 |
df.loc['20160103',['A', 'B']]print(df.loc['20160101', 'A'])
# 或者使用.at属性
print(df.at[dates[0], 'A'])df.iloc[3]df.iloc[3:5, 0:2]| A | B | |
|---|---|---|
| 2016-01-04 | -1.430586 | -0.732160 |
| 2016-01-05 | -0.519748 | 0.386824 |
df.iloc[[1,2,4],[0,2]]| A | C | |
|---|---|---|
| 2016-01-02 | 1.966543 | 0.168445 |
| 2016-01-03 | -1.308454 | -2.465547 |
| 2016-01-05 | -0.519748 | -2.775289 |
df.iloc[1:3]| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 |
df.iloc[:,1:3]| B | C | |
|---|---|---|
| 2016-01-01 | -1.548973 | 1.013311 |
| 2016-01-02 | 0.468294 | 0.168445 |
| 2016-01-03 | 0.625522 | -2.465547 |
| 2016-01-04 | -0.732160 | -0.034836 |
| 2016-01-05 | 0.386824 | -2.775289 |
| 2016-01-06 | -0.311089 | 0.646725 |
df.iloc[1,1] # 等价与 df.iat{1,1}df[df.A > 0]| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 |
df[df >0]| A | B | C | D | |
|---|---|---|---|---|
| 2016-01-01 | NaN | NaN | 1.013311 | 1.981536 |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | NaN |
| 2016-01-03 | NaN | 0.625522 | NaN | 1.757797 |
| 2016-01-04 | NaN | NaN | NaN | 0.216295 |
| 2016-01-05 | NaN | 0.386824 | NaN | NaN |
| 2016-01-06 | 1.027911 | NaN | 0.646725 | 0.773003 |
使用 isin 方法来筛选数据
df2 = df.copy()
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
df2| A | B | C | D | E | |
|---|---|---|---|---|---|
| 2016-01-01 | -0.808397 | -1.548973 | 1.013311 | 1.981536 | one |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 | one |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 | two |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 | three |
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | -0.088892 | four |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 | three |
df2[df2['E'].isin(['one','three'])]| A | B | C | D | E | |
|---|---|---|---|---|---|
| 2016-01-01 | -0.808397 | -1.548973 | 1.013311 | 1.981536 | one |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 | one |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 | three |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 | three |
s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20160102', periods=6))
df['F'] = s1
df| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | 1.013311 | 1.981536 | NaN |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 | 1.0 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 | 2.0 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 | 3.0 |
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | -0.088892 | 4.0 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 | 5.0 |
也可以通过标签来赋值
df.at[dates[0], 'A'] = 0
df| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | 1.013311 | 1.981536 | NaN |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 | 1.0 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 | 2.0 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 | 3.0 |
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | -0.088892 | 4.0 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 | 5.0 |
通过位来赋值
df.iat[0, 1] = 0
df| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | 1.013311 | 1.981536 | NaN |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | -1.474018 | 1.0 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 1.757797 | 2.0 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 0.216295 | 3.0 |
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | -0.088892 | 4.0 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 0.773003 | 5.0 |
将numpy数组赋值给某列
df.loc[:, 'D'] = np.array([5] * len(df))
df| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | 1.013311 | 5 | NaN |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | 5 | 1.0 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 5 | 2.0 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 5 | 3.0 |
| 2016-01-05 | -0.519748 | 0.386824 | -2.775289 | 5 | 4.0 |
| 2016-01-06 | 1.027911 | -0.311089 | 0.646725 | 5 | 5.0 |
df2 = df.copy()
df2[df2>0] = -df2
df2| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | -1.013311 | -5 | NaN |
| 2016-01-02 | -1.966543 | -0.468294 | -0.168445 | -5 | -1.0 |
| 2016-01-03 | -1.308454 | -0.625522 | -2.465547 | -5 | -2.0 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | -5 | -3.0 |
| 2016-01-05 | -0.519748 | -0.386824 | -2.775289 | -5 | -4.0 |
| 2016-01-06 | -1.027911 | -0.311089 | -0.646725 | -5 | -5.0 |
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])
df1.loc[dates[0]:dates[1], 'E'] = 1
df1| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | 1.013311 | 5 | NaN | 1.0 |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | 5 | 1.0 | 1.0 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 5 | 2.0 | NaN |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 5 | 3.0 | NaN |
方案一、丢弃所有数据缺失的行
df1.dropna(how='any')| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | 5 | 1.0 | 1.0 |
方案二、填充缺失值
df1.fillna(value=5)| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | 1.013311 | 5 | 5.0 | 1.0 |
| 2016-01-02 | 1.966543 | 0.468294 | 0.168445 | 5 | 1.0 | 1.0 |
| 2016-01-03 | -1.308454 | 0.625522 | -2.465547 | 5 | 2.0 | 5.0 |
| 2016-01-04 | -1.430586 | -0.732160 | -0.034836 | 5 | 3.0 | 5.0 |
可以获取到缺失数据的掩码
df.isnull()
# 值为True的位置即是数据缺失的位置| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | False | False | False | False | True |
| 2016-01-02 | False | False | False | False | False |
| 2016-01-03 | False | False | False | False | False |
| 2016-01-04 | False | False | False | False | False |
| 2016-01-05 | False | False | False | False | False |
| 2016-01-06 | False | False | False | False | False |
df.mean()# 行内统计
df.mean(1)s = pd.Series([1,3,5,np.nan, 6, 8], index=dates).shift(2)
sdf.sub(s, axis='index')| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | NaN | NaN | NaN | NaN | NaN |
| 2016-01-02 | NaN | NaN | NaN | NaN | NaN |
| 2016-01-03 | -2.308454 | -0.374478 | -3.465547 | 4.0 | 1.0 |
| 2016-01-04 | -4.430586 | -3.732160 | -3.034836 | 2.0 | 0.0 |
| 2016-01-05 | -5.519748 | -4.613176 | -7.775289 | 0.0 | -1.0 |
| 2016-01-06 | NaN | NaN | NaN | NaN | NaN |
df.apply(np.cumsum, axis=0)| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2016-01-01 | 0.000000 | 0.000000 | 1.013311 | 5 | NaN |
| 2016-01-02 | 1.966543 | 0.468294 | 1.181756 | 10 | 1.0 |
| 2016-01-03 | 0.658089 | 1.093815 | -1.283791 | 15 | 3.0 |
| 2016-01-04 | -0.772497 | 0.361655 | -1.318627 | 20 | 6.0 |
| 2016-01-05 | -1.292245 | 0.748479 | -4.093916 | 25 | 10.0 |
| 2016-01-06 | -0.264334 | 0.437390 | -3.447191 | 30 | 15.0 |
df.apply(lambda x: x.max() - x.min())s = pd.Series(np.random.randint(0,7,size=10))
ss.value_counts()s = pd.Series(['A', 'B', 'C', 'Aaba', 'BAcd', np.nan, 'CBA', 'dog', 'CAT'])
s.str.lower()# concat 函数将对象连接在一起
df = pd.DataFrame(np.random.randn(10,4))
df| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -0.859307 | -0.723708 | -1.121663 | 1.438285 |
| 1 | -0.168126 | -0.343567 | 0.678940 | 0.394126 |
| 2 | -0.541090 | 1.908998 | -0.543378 | -0.109371 |
| 3 | -1.108110 | 0.332687 | -1.320752 | 1.022476 |
| 4 | 0.591171 | -1.259859 | 0.930266 | 0.688108 |
| 5 | -0.065470 | -0.957394 | 1.423691 | -0.295647 |
| 6 | 1.728151 | 0.162709 | 0.836916 | -0.573260 |
| 7 | -0.025487 | 0.307945 | -0.414787 | -0.045495 |
| 8 | -0.601439 | -0.167967 | -1.198304 | 0.242739 |
| 9 | 0.495473 | -0.348495 | 1.599757 | 0.184015 |
pieces = [df[:3], df[5:]]
pd.concat(pieces)| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -0.859307 | -0.723708 | -1.121663 | 1.438285 |
| 1 | -0.168126 | -0.343567 | 0.678940 | 0.394126 |
| 2 | -0.541090 | 1.908998 | -0.543378 | -0.109371 |
| 5 | -0.065470 | -0.957394 | 1.423691 | -0.295647 |
| 6 | 1.728151 | 0.162709 | 0.836916 | -0.573260 |
| 7 | -0.025487 | 0.307945 | -0.414787 | -0.045495 |
| 8 | -0.601439 | -0.167967 | -1.198304 | 0.242739 |
| 9 | 0.495473 | -0.348495 | 1.599757 | 0.184015 |
left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1,2]})
right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4,5]})
left| key | lval | |
|---|---|---|
| 0 | foo | 1 |
| 1 | foo | 2 |
right| key | rval | |
|---|---|---|
| 0 | foo | 4 |
| 1 | foo | 5 |
pd.merge(left, right, on='key')| key | lval | rval | |
|---|---|---|---|
| 0 | foo | 1 | 4 |
| 1 | foo | 1 | 5 |
| 2 | foo | 2 | 4 |
| 3 | foo | 2 | 5 |
df = pd.DataFrame(np.random.randn(8, 4), columns=['A','B','C','D'])
df| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.535803 | -0.319896 | -0.313776 | -0.401106 |
| 1 | -0.231405 | 2.058233 | 0.771222 | 0.170204 |
| 2 | -1.699222 | -0.098205 | 0.465100 | 0.295165 |
| 3 | -0.273538 | -0.902247 | -0.328348 | 0.771312 |
| 4 | 0.080118 | 0.796800 | 0.564468 | 0.526290 |
| 5 | 0.485221 | 0.478245 | -0.943854 | -0.097568 |
| 6 | -0.440915 | 0.134749 | -0.840602 | -0.836712 |
| 7 | -0.283432 | -0.029233 | 1.725972 | -0.878117 |
s = df.iloc[3]
df.append(s, ignore_index=True)| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.535803 | -0.319896 | -0.313776 | -0.401106 |
| 1 | -0.231405 | 2.058233 | 0.771222 | 0.170204 |
| 2 | -1.699222 | -0.098205 | 0.465100 | 0.295165 |
| 3 | -0.273538 | -0.902247 | -0.328348 | 0.771312 |
| 4 | 0.080118 | 0.796800 | 0.564468 | 0.526290 |
| 5 | 0.485221 | 0.478245 | -0.943854 | -0.097568 |
| 6 | -0.440915 | 0.134749 | -0.840602 | -0.836712 |
| 7 | -0.283432 | -0.029233 | 1.725972 | -0.878117 |
| 8 | -0.273538 | -0.902247 | -0.328348 | 0.771312 |
df = pd.DataFrame({
'A': ['foo','bar','foo','bar','foo','bar','foo','foo'],
'B': ['one','one','two','three', 'two', 'two', 'one', 'three'],
'C': np.random.randn(8),
'D': np.random.randn(8)
})
df| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | 0.996471 | 0.659993 |
| 1 | bar | one | 0.990690 | -1.102114 |
| 2 | foo | two | -0.138965 | 0.236194 |
| 3 | bar | three | 0.033469 | 0.253152 |
| 4 | foo | two | -0.574320 | 0.081216 |
| 5 | bar | two | 1.992456 | 0.939238 |
| 6 | foo | one | -0.514013 | -1.610422 |
| 7 | foo | three | -0.640462 | -1.606399 |
分组聚合后将sum函数应用到分组数据上
df.groupby('A').sum()| C | D | |
|---|---|---|
| A | ||
| bar | 3.016615 | 0.090276 |
| foo | -0.871289 | -2.239418 |
多重分组聚合之后,应用sum函数
df.groupby(['A', 'B']).sum()| C | D | ||
|---|---|---|---|
| A | B | ||
| bar | one | 0.990690 | -1.102114 |
| three | 0.033469 | 0.253152 | |
| two | 1.992456 | 0.939238 | |
| foo | one | 0.482458 | -0.950429 |
| three | -0.640462 | -1.606399 | |
| two | -0.713285 | 0.317410 |
tuples = list(zip(*[
['bar','bar', 'baz', 'baz', 'foo','foo', 'qux', 'qux'],
['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two' ]
]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A','B'])
df2 = df[:4]
df2| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | -0.084595 | 1.495368 |
| two | -0.801703 | -0.663997 | |
| baz | one | -0.108681 | -0.986022 |
| two | -0.524829 | 0.983664 |
# stack方法将列转换为行
stacked = df2.stack()
stacked# unstack方法将行转为列
stacked.unstack()| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | -0.084595 | 1.495368 |
| two | -0.801703 | -0.663997 | |
| baz | one | -0.108681 | -0.986022 |
| two | -0.524829 | 0.983664 |
# 默认unstack操作的是最内层的数据,可以指定层数
stacked.unstack(1)| second | one | two | |
|---|---|---|---|
| first | |||
| bar | A | -0.084595 | -0.801703 |
| B | 1.495368 | -0.663997 | |
| baz | A | -0.108681 | -0.524829 |
| B | -0.986022 | 0.983664 |
stacked.unstack(0)| first | bar | baz | |
|---|---|---|---|
| second | |||
| one | A | -0.084595 | -0.108681 |
| B | 1.495368 | -0.986022 | |
| two | A | -0.801703 | -0.524829 |
| B | -0.663997 | 0.983664 |
df = pd.DataFrame({
'A': ['one', 'two', 'three', 'four'] * 3,
'B': ['A', 'B', 'C'] * 4,
'C': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D': np.random.randn(12),
'E': np.random.randn(12)
})
df| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | one | A | foo | 0.319799 | -1.264188 |
| 1 | two | B | foo | 0.929552 | -0.092799 |
| 2 | three | C | foo | -2.510099 | 0.979121 |
| 3 | four | A | bar | 1.727211 | 0.083378 |
| 4 | one | B | bar | 0.636672 | -0.167700 |
| 5 | two | C | bar | 0.337749 | 0.782511 |
| 6 | three | A | foo | 0.429180 | -2.415025 |
| 7 | four | B | foo | 0.334974 | -1.997174 |
| 8 | one | C | foo | 0.248257 | -1.003121 |
| 9 | two | A | bar | 0.465319 | 1.133168 |
| 10 | three | B | bar | 0.111670 | -0.730784 |
| 11 | four | C | bar | -1.903981 | -0.089501 |
pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])| C | bar | foo | |
|---|---|---|---|
| A | B | ||
| four | A | 1.727211 | NaN |
| B | NaN | 0.334974 | |
| C | -1.903981 | NaN | |
| one | A | NaN | 0.319799 |
| B | 0.636672 | NaN | |
| C | NaN | 0.248257 | |
| three | A | NaN | 0.429180 |
| B | 0.111670 | NaN | |
| C | NaN | -2.510099 | |
| two | A | 0.465319 | NaN |
| B | NaN | 0.929552 | |
| C | 0.337749 | NaN |
rng = pd.date_range('1/1/2016', periods=100, freq='S')
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
ts.resample('10S').sum()rng = pd.date_range('2/2/2016 00:00', periods=5 , freq='D')
ts = pd.Series(np.random.randn(len(rng)), rng)
tsts_utc = ts.tz_localize('UTC')
ts_utcts_utc.tz_convert('Asia/Shanghai')ran = pd.date_range('1/1/2016', periods=5, freq='M')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
tsps = ts.to_period()
psps.to_timestamp()df = pd.DataFrame({
"id": [1,2,3,4,5,6],
"raw_grade": ['a','b','b','a','a','e']
})
df['grade'] = df['raw_grade'].astype('category')
df['grade']df.grade.cat.categories = ['very good', 'good', 'bad']
df.gradedf.grade = df.grade.cat.set_categories(['very bad', 'bad', 'medium', 'good', 'very good'])
df.gradedf.sort_values(by='grade')| id | raw_grade | grade | |
|---|---|---|---|
| 5 | 6 | e | bad |
| 1 | 2 | b | good |
| 2 | 3 | b | good |
| 0 | 1 | a | very good |
| 3 | 4 | a | very good |
| 4 | 5 | a | very good |
df.groupby('grade').size()grade
very bad 0
bad 1
medium 0
good 2
very good 3
dtype: int64
绘图
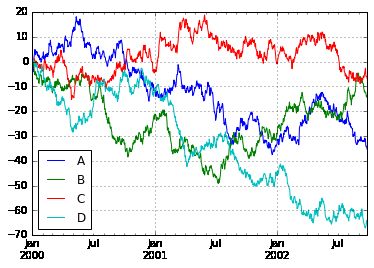
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot(grid=True)
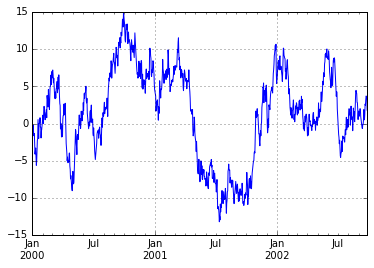
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list('ABCD'))
df = df.cumsum()
plt.figure()
df.plot(grid=True)
plt.legend(loc='best')