分布式系统技术点汇总
一个网站就是一个应用,当系统压力较大时,只能横向扩展,增加多个服务器或者多个容器去做负载均衡,避免单点故障而影响到整个系统。
集中式最明显的优点就是开发,测试,运维会比较方便,不用考虑复杂的分布式环境。
弊端也很明显,系统大而复杂、不易扩展、难于维护,每次更新都必须更新所有的应用。
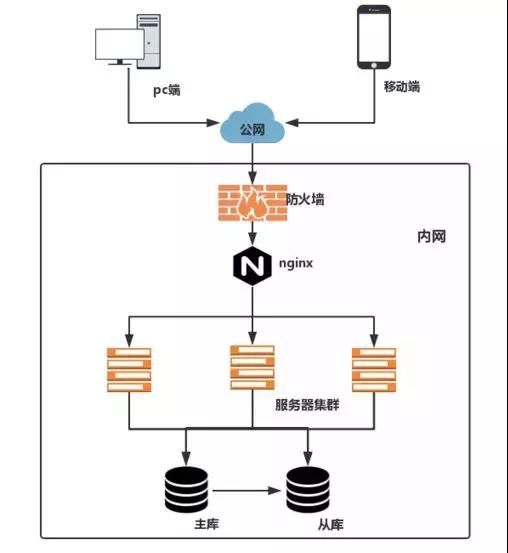
集中式系统拓扑图
鉴于集中式系统的种种弊端,促成了分布式系统的形成,分布式系统背后是由一系列的计算机组成,但用户感知不到背后的逻辑,就像访问单个计算机一样,天然的避免了单机故障的问题。
应用可以按业务类型拆分成多个应用或服务,再按结构分成接口层、服务层。
我们也可以按访问入口分,如移动端、PC 端等定义不同的接口应用。数据库可以按业务类型拆分成多个实例,还可以对单表进行分库分表。同时增加分布式缓存、消息队列、非关系型数据库、搜索等中间件。
分布式系统虽好,但是增加了系统的复杂性,如分布式事务、分布式锁、分布式 Session、数据一致性等都是现在分布式系统中需要解决的难题。
分布式系统也增加了开发测试运维的成本,工作量增加,其管理不好反而会变成一种负担。
分布式系统拓扑图
分布式系统最为核心的要属分布式服务框架,有了分布式服务框架,我们只需关注各自的业务,而无需去关注那些复杂的服务之间调用的过程。
分布式服务框架
目前业界比较流行的分布式服务框架有:阿里的 Dubbo、Spring Cloud。
这里不对这些分布式服务框架做对比,简单的说说他们都做了些什么,能使我们用远程服务就像调用本地服务那么简单高效。
服务
服务是对使用用户有功能输出的模块,以技术框架作为基础,能实现用户的需求。
比如日志记录服务、权限管理服务、后台服务、配置服务、缓存服务、存储服务、消息服务等,这些服务可以灵活的组合在一起,也可以独立运行。
服务需要有接口,与系统进行对接。面向服务的开发,应该是把服务拆分开发,把服务组合运行。
更加直接的例子如:历史详情、留言板、评论、评级服务等。他们之间能独立运行,也要能组合在一起作为一个整体。
注册中心
注册中心对整个分布式系统起着最为核心的整合作用,支持对等集群,需要提供 CRUD 接口,支持订阅发布机制且可靠性要求非常之高,一般拿 Zookeeper 集群来做为注册中心。
分布式环境中服务提供方的服务会在多台服务器上部署,每台服务器会向注册中心提供服务方标识、服务列表、地址、对应端口、序列化协议等信息。
注册中心记录下服务和服务地址的映射关系,一般一个服务会对应多个地址,这个过程我们称之为服务发布或服务注册。
服务调用方会根据服务方标识、服务列表从注册中心获取所需服务的信息(地址端口信息、序列化协议等),这些信息会缓存至本地。
当服务需要调用其他服务时,直接在这里找到服务的地址,进行调用,这个过程我们称之为服务发现。
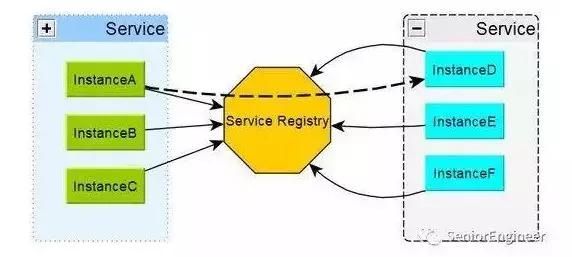
注册中心
下面是以 Zookeeper 作为注册中心的简单实现:
- /**
- * 创建node节点
- * @param node
- * @param data
- */
- public boolean createNode(String node, String data) {
- try {
- byte[] bytes = data.getBytes();
- //同步创建临时顺序节点
- String path = zk.create(ZkConstant.ZK_RPC_DATA_PATH+"/"+node+"-", bytes, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
- log.info("create zookeeper node ({} => {})", path, data);
- }catch (KeeperException e) {
- log.error("", e);
- return false;
- }catch (InterruptedException ex){
- log.error("", ex);
- return false;
- }
- return true;
- }
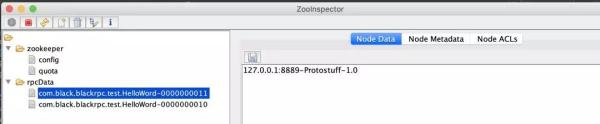
子节点 1

子节点 2
如下面 Zookeeper 中写入的临时顺序节点信息:
- com.black.blackrpc.test.HelloWord:发布服务时对外的名称。
- 00000000010,00000000011:ZK 顺序节点 ID。
- 127.0.0.1:8888,127.0.0.1:8889:服务地址端口。
- Protostuff:序列化方式。
- 1.0:权值,负载均衡策略使用。
这里使用的是 Zookeeper 的临时顺序节点,为什么使用临时顺序节点,主要是考虑以下两点:
- 当服务提供者异常下线时,与 Zookeeper 的连接会中断,Zookeeper 服务器会主动删除临时节点,同步给服务消费者。
这样就能避免服务消费者去请求异常的服务器。校稿注: 一般消费方也会在实际发起请求前,对当前获取到的服务提供方节点进行心跳,避免请求连接有问题的节点。
- Zookeeper 下面是不允许创建 2 个名称相同的 ZK 子节点的,通过顺序节点就能避免创建相同的名称。
当然也可以不用顺序节点的方式,直接以 com.black.blackrpc.test.HelloWord 创建节点,在该节点下创建数据节点。
下面是 ZK 的数据同步过程:
- /**
- * 同步节点 (通知模式)
- * syncNodes会通过级联方式,在每次watcher被触发后,就会再挂上新的watcher。完成了类似链式触发的功能
- */
- public boolean syncNodes() {
- try {
- List
nodeList = zk.getChildren(ZkConstant.ZK_RPC_DATA_PATH, new Watcher() { - @Override
- public void process(WatchedEvent event) {
- if (event.getType() == Event.EventType.NodeChildrenChanged) {
- syncNodes();
- }
- }
- });
- Map
- for (String node : nodeList) {
- byte[] bytes = zk.getData(ZkConstant.ZK_RPC_DATA_PATH + "/" + node, false, null);
- String key =node.substring(0, node.lastIndexOf(ZkConstant.DELIMITED_MARKER));
- String value=new String(bytes);
- Object object =map.get(key);
- if(object!=null){
- ((List
)object).add(value); - }else {
- List
dataList = new ArrayList (); - dataList.add(value);
- map.put(key,dataList);
- }
- log.info("node: [{}] data: [{}]",node,new String(bytes));
- }
- /**修改连接的地址缓存*/
- if(MapUtil.isNotEmpty(map)){
- log.debug("invoking service cache updateing....");
- InvokingServiceCache.updataInvokingServiceMap(map);
- }
- return true;
- } catch (KeeperException | InterruptedException e) {
- log.error(e.toString());
- return false;
- }
- }
当数据同步到本地时,一般会写入到本地文件中,防止因 Zookeeper 集群异常下线而无法获取服务提供者信息。
通讯与协议
服务消费者无论是与注册中心还是与服务提供者,都需要存在网络连接传输数据,而这就涉及到通讯。
笔者之前也做过这方面的工作,当时使用的是 java BIO 简单的写了一个通讯包,使用场景没有多大的并发,阻塞式的 BIO 也未暴露太多问题。
java BIO 因其建立连接之后会阻塞线程等待数据,这种方式必须以一连接一线程的方式,即客户端有连接请求时服务器端就需要启动一个线程进行处理。当连接数过大时,会建立相当多的线程,性能直线下降。
Java NIO:同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 I/O 请求时才启动一个线程进行处理。
Java AIO:异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的 I/O 请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理。
BIO、NIO、AIO 适用场景分析:
- BIO:用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,但程序直观简单易理解。
- NIO:适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂。
目前主流的通讯框架 Netty、Apache Mina、Grizzl、NIO Framework 都是基于其实现的。
- AIO:用于连接数目多且连接比较长(重操作)的架构,比如图片服务器,文件传输等,充分调用 OS 参与并发操作,编程比较复杂。
作为基石的通讯,其实要考虑很多东西。如:丢包粘包的情况,心跳机制,断连重连,消息缓存重发,资源的优雅释放,长连接还是短连接等。
下面是 Netty 建立服务端,客户端的简单实现:
- import io.netty.bootstrap.ServerBootstrap;
- import io.netty.channel.ChannelInitializer;
- import io.netty.channel.ChannelPipeline;
- import io.netty.channel.EventLoopGroup;
- import io.netty.channel.nio.NioEventLoopGroup;
- import io.netty.channel.socket.SocketChannel;
- import io.netty.channel.socket.nio.NioServerSocketChannel;
- import io.netty.handler.codec.LengthFieldBasedFrameDecoder;
- import io.netty.handler.codec.LengthFieldPrepender;
- import io.netty.handler.codec.bytes.ByteArrayDecoder;
- import io.netty.handler.codec.bytes.ByteArrayEncoder;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- /***
- * netty tcp 服务端
- * @author v_wangshiyu
- *
- */
- public class NettyTcpService {
- private static final Logger log = LoggerFactory.getLogger(NettyTcpService.class);
- private String host;
- private int port;
- public NettyTcpService(String address) throws Exception{
- String str[] = address.split(":");
- this.host=str[0];
- this.port=Integer.valueOf(str[1]);
- }
- public NettyTcpService(String host,int port) throws Exception{
- this.host=host;
- this.port=port;
- }
- /**用于分配处理业务线程的线程组个数 */
- private static final int BIZGROUPSIZE = Runtime.getRuntime().availableProcessors()*2; //默认
- /** 业务出现线程大小*/
- private static final int BIZTHREADSIZE = 4;
- /*
- * NioEventLoopGroup实际上就是个线程,
- * NioEventLoopGroup在后台启动了n个NioEventLoop来处理Channel事件,
- * 每一个NioEventLoop负责处理m个Channel,
- * NioEventLoopGroup从NioEventLoop数组里挨个取出NioEventLoop来处理Channel
- */
- private static final EventLoopGroup bossGroup = new NioEventLoopGroup(BIZGROUPSIZE);
- private static final EventLoopGroup workerGroup = new NioEventLoopGroup(BIZTHREADSIZE);
- public void start() throws Exception {
- log.info("Netty Tcp Service Run...");
- ServerBootstrap b = new ServerBootstrap();
- b.group(bossGroup, workerGroup);
- b.channel(NioServerSocketChannel.class);
- b.childHandler(new ChannelInitializer
() { - @Override
- public void initChannel(SocketChannel ch) throws Exception {
- ChannelPipeline pipeline = ch.pipeline();
- pipeline.addLast("frameDecoder", new LengthFieldBasedFrameDecoder(Integer.MAX_VALUE, 0, 4, 0, 4));
- pipeline.addLast("frameEncoder", new LengthFieldPrepender(4));
- pipeline.addLast("decoder", new ByteArrayDecoder());
- pipeline.addLast("encoder", new ByteArrayEncoder());
- // pipeline.addLast(new Encoder());
- // pipeline.addLast(new Decoder());
- pipeline.addLast(new TcpServerHandler());
- }
- });
- b.bind(host, port).sync();
- log.info("Netty Tcp Service Success!");
- }
- /**
- * 停止服务并释放资源
- */
- public void shutdown() {
- workerGroup.shutdownGracefully();
- bossGroup.shutdownGracefully();
- }
- }
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import io.netty.channel.ChannelHandlerContext;
- import io.netty.channel.SimpleChannelInboundHandler;
- /**
- * 服务端处理器
- */
- public class TcpServerHandler extends SimpleChannelInboundHandler
- private static final Logger log = LoggerFactory.getLogger(TcpServerHandler.class);
- @Override
- protected void channelRead0(ChannelHandlerContext ctx, Object msg) throws Exception {
- byte[] data=(byte[])msg;
- }
- }
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import io.netty.bootstrap.Bootstrap;
- import io.netty.channel.Channel;
- import io.netty.channel.ChannelInitializer;
- import io.netty.channel.ChannelOption;
- import io.netty.channel.ChannelPipeline;
- import io.netty.channel.EventLoopGroup;
- import io.netty.channel.nio.NioEventLoopGroup;
- import io.netty.channel.socket.nio.NioSocketChannel;
- import io.netty.handler.codec.LengthFieldBasedFrameDecoder;
- import io.netty.handler.codec.LengthFieldPrepender;
- import io.netty.handler.codec.bytes.ByteArrayDecoder;
- import io.netty.handler.codec.bytes.ByteArrayEncoder;
- import io.netty.util.concurrent.Future;
- /**
- * netty tcp 客户端
- * @author v_wangshiyu
- *
- */
- public class NettyTcpClient {
- private static final Logger log = LoggerFactory.getLogger(NettyTcpClient.class);
- private String host;
- private int port;
- private Bootstrap bootstrap;
- private Channel channel;
- private EventLoopGroup group;
- public NettyTcpClient(String host,int port){
- bootstrap=getBootstrap();
- channel= getChannel(host,port);
- this.host=host;
- this.port=port;
- }
- public String getHost() {
- return host;
- }
- public int getPort() {
- return port;
- }
- /**
- * 初始化Bootstrap
- * @return
- */
- public final Bootstrap getBootstrap(){
- group = new NioEventLoopGroup();
- Bootstrap b = new Bootstrap();
- b.group(group).channel(NioSocketChannel.class);
- b.handler(new ChannelInitializer
() { - @Override
- protected void initChannel(Channel ch) throws Exception {
- ChannelPipeline pipeline = ch.pipeline();
- // pipeline.addLast(new Encoder());
- // pipeline.addLast(new Decoder());
- pipeline.addLast("frameDecoder", new LengthFieldBasedFrameDecoder(Integer.MAX_VALUE, 0, 4, 0, 4));
- pipeline.addLast("frameEncoder", new LengthFieldPrepender(4));
- pipeline.addLast("decoder", new ByteArrayDecoder());
- pipeline.addLast("encoder", new ByteArrayEncoder());
- pipeline.addLast("handler", new TcpClientHandler());
- }
- });
- b.option(ChannelOption.SO_KEEPALIVE, true);
- return b;
- }
- /**
- * 连接,获取Channel
- * @param host
- * @param port
- * @return
- */
- public final Channel getChannel(String host,int port){
- Channel channel = null;
- try {
- channel = bootstrap.connect(host, port).sync().channel();
- return channel;
- } catch (Exception e) {
- log.info(String.format("connect Server(IP[%s],PORT[%s]) fail!", host,port));
- return null;
- }
- }
- /**
- * 发送消息
- * @param msg
- * @throws Exception
- */
- public boolean sendMsg(Object msg) throws Exception {
- if(channel!=null){
- channel.writeAndFlush(msg).sync();
- log.debug("msg flush success");
- return true;
- }else{
- log.debug("msg flush fail,connect is null");
- return false;
- }
- }
- /**
- * 连接断开
- * 并且释放资源
- * @return
- */
- public boolean disconnectConnect(){
- //channel.close().awaitUninterruptibly();
- Future future =group.shutdownGracefully();//shutdownGracefully释放所有资源,并且关闭所有当前正在使用的channel
- future.syncUninterruptibly();
- return true;
- }
- }
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import io.netty.channel.ChannelHandlerContext;
- import io.netty.channel.SimpleChannelInboundHandler;
- /**
- * 客户端处理器
- */
- public class TcpClientHandler extends SimpleChannelInboundHandler
- private static final Logger log = LoggerFactory.getLogger(TcpClientHandler.class);
- @Override
- protected void channelRead0(ChannelHandlerContext ctx, Object msg) throws Exception {
- byte[] data=(byte[])msg;
- }
- }
说到通讯就不能不说协议,通信时所遵守的规则,访问什么,传输的格式等都属于协议。
作为一个开发人员,应该都了解 TCP/IP 协议,它是一个网络通信模型,以及一整套网络传输协议家族,是互联网的基础通信架构。
也都应该用过 Http(超文本传输协议),Web 服务器传输超文本到本地浏览器的传送协议,该协议建立在 TCP/IP 协议之上。分布式服务框架服务间的调用也会规定协议。
为了支持不同场景,分布式服务框架会存在多种协议,如 Dubbo 就支持 7 种协议:Dubbo 协议(默认),RMI 协议,Hessian协议,HTTP 协议,WebService 协议,Thrift 协议,Memcached 协议,Redis 协议每种协议应对的场景不尽相同,具体场景具体对待。
服务路由
分布式服务上线时都是集群组网部署,集群中会存在某个服务的多实例,消费者如何从服务列表中选择合适的服务提供者进行调用,这就涉及到服务路由。分布式服务框架需要能够满足用户灵活的路由需求。
透明化路由
很多开源的 RPC 框架调用者需要配置服务提供者的地址信息,尽管可以通过读取数据库的服务地址列表等方式避免硬编码地址信息,但是消费者依然要感知服务提供者的地址信息,这违反了透明化路由原则。
基于服务注册中心的服务订阅发布,消费者通过主动查询和被动通知的方式获取服务提供者的地址信息,而不再需要通过硬编码方式得到提供者的地址信息。
只需要知道当前系统发布了那些服务,而不需要知道服务具体存在于什么位置,这就是透明化路由。
负载均衡
负载均衡策略是服务的重要属性,分布式服务框架通常会提供多种负载均衡策略,同时支持用户扩展负载均衡策略。
随机
通常在对等集群组网中,采用随机算法进行负载均衡,随机路由算法消息分发还是比较均匀的,采用 JDK 提供的 java.util.Random 或者 java.security.SecureRandom 在指定服务提供者列表中生成随机地址。
消费者基于随机生成的服务提供者地址进行远程调用:
- /**
- * 随机
- */
- public class RandomStrategy implements ClusterStrategy {
- @Override
- public RemoteServiceBase select(List
list) { - int MAX_LEN = list.size();
- int index = RandomUtil.nextInt(MAX_LEN);
- return list.get(index);
- }
- }
随机还是存在缺点的,可能出现部分节点的碰撞的概率较高,另外硬件配置差异较大时,会导致各节点负载不均匀。
为避免这些问题,需要对服务列表加权,性能好的机器接收的请求的概率应该高于一般机器:
- /**
- * 加权随机
- */
- public class WeightingRandomStrategy implements ClusterStrategy {
- @Override
- public RemoteServiceBase select(List
list) { - //存放加权后的服务提供者列表
- List
weightingList = new ArrayList (); - for (RemoteServiceBase remoteServiceBase : list) {
- //扩大10倍
- int weight = (int) (remoteServiceBase.getWeight()*10);
- for (int i = 0; i < weight; i++) {
- weightingList.add(remoteServiceBase);
- }
- }
- int MAX_LEN = weightingList.size();
- int index = RandomUtil.nextInt(MAX_LEN);
- return weightingList.get(index);
- }
- }
轮询
逐个请求服务地址,到达边界之后,继续绕接。主要缺点:慢的提供者会累积请求。
例如第二台机器很慢,但没挂。当请求第二台机器时被卡在那。久而久之,所有请求都卡在第二台机器上。
轮询策略实现非常简单,顺序循环遍历服务提供者列表,达到边界之后重新归零开始,继续顺序循环:
- /**
- * 轮询
- */
- public class PollingStrategy implements ClusterStrategy {
- //计数器
- private int index = 0;
- private Lock lock = new ReentrantLock();
- @Override
- public RemoteServiceBase select(List
list) { - RemoteServiceBase service = null;
- try {
- lock.tryLock(10, TimeUnit.MILLISECONDS);
- //若计数大于服务提供者个数,将计数器归0
- if (index >= list.size()) {
- index = 0;
- }
- service = list.get(index);
- index++;
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- lock.unlock();
- }
- //兜底,保证程序健壮性,若未取到服务,则直接取第一个
- if (service == null) {
- service = list.get(0);
- }
- return service;
- }
- }
加权轮询的话,需要给服务地址添加权重:
- /**
- * 加权轮询
- */
- public class WeightingPollingStrategy implements ClusterStrategy {
- //计数器
- private int index = 0;
- //计数器锁
- private Lock lock = new ReentrantLock();
- @Override
- public RemoteServiceBase select(List
list) { - RemoteServiceBase service = null;
- try {
- lock.tryLock(10, TimeUnit.MILLISECONDS);
- //存放加权后的服务提供者列表
- List
weightingList = new ArrayList (); - for (RemoteServiceBase remoteServiceBase : list) {
- //扩大10倍
- int weight = (int) (remoteServiceBase.getWeight()*10);
- for (int i = 0; i < weight; i++) {
- weightingList.add(remoteServiceBase);
- }
- }
- //若计数大于服务提供者个数,将计数器归0
- if (index >= weightingList.size()) {
- index = 0;
- }
- service = weightingList.get(index);
- index++;
- return service;
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- lock.unlock();
- }
- //兜底,保证程序健壮性,若未取到服务,则直接取第一个
- return list.get(0);
- }
- }
服务调用时延
消费者缓存所有服务提供者的调用时延,周期性的计算服务调用平均时延。
然后计算每个服务提供者服务调用时延与平均时延的差值,根据差值大小动态调整权重,保证服务时延大的服务提供者接收更少的消息,防止消息堆积。
该策略的特点:保证处理能力强的服务接受更多的消息,通过动态的权重分配消除服务调用时延的震荡范围,使所有服务的调用时延接近平均值,实现负载均衡。
一致性哈希
相同参数的请求总是发送到统一服务提供者,当某一台服务提供者宕机时,原本发往根提供者的请求,基于虚拟节点,平摊到其他提供者,不会引起剧烈变动,平台提供默认的虚拟节点数,可以通过配置文件修改虚拟节点个数。
一致性 Hash 环工作原理如下图所示:
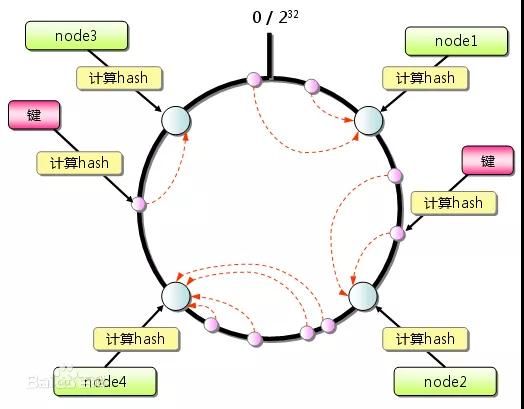
一致性哈希
路由规则
负载均衡只能保证服务提供者压力的平衡,但是在一些业务场景中需要设置一些过滤规则,比较常用的是基本表达式的条件路由。
通过 IP 条件表达式配置黑白名单访问控制:consumerIP != 192.168.1.1。
只暴露部分服务提供者,防止这个集群服务都被冲垮,导致其他服务也不可用。
- 例如providerIP = 192.168.3*。
- 读写分离:method=find*,list*,get*,query*=>providerIP=192.168.1.。
- 前后台分离:app=web=>providerIP=192.168.1.,app=java=>providerIP=192.168.2.。
- 灰度升级:将WEB前台应用理由到新的服务版本上:app=web=>provicerIP=192.168.1.*。
序列化与反序列化
把对象转换为字节序列的过程称为序列化,把字节序列恢复为对象的过程称为反序列化。
运程调用的时候,我们需要先将 Java 对象进行序列化,然后通过网络,IO 进行传输,当到达目的地之后,再进行反序列化获取到我们想要的结果对象。
分布式系统中,传输的对象会很多,这就要求序列化速度快,产生字节序列小的序列化技术。
序列化技术:Serializable,XML,Jackson,MessagePack,FastJson,Protocol Buffer,Thrift,Gson,Avro,Hessian 等。
Serializable 是 Java 自带的序列化技术,无法跨平台,序列化和反序列化的速度相对较慢。
XML 技术多平台支持好,常用于与银行交互的报文,但是其字节序列产生较大,不太适合用作分布式通讯框架。
FastJson 是 Java 语言编写的高性能的 JSON 处理器,由阿里巴巴公司开发,字节序列为 json 串,可读性好,序列化也速度非常的快。
Protocol Buffer 序列化速度非常快,字节序列较小,但是可读性较差。
一般分布式服务框架会内置多种序列化协议可供选择,如 Dubbo 支持的 7 种协议用到的序列化技术就不完全相同。
服务调用
本地环境下,使用某个接口很简单,直接调用就行。分布式环境下就不是那么简单了,消费者方只会存在接口的定义,没有具体的实现。
想要像本地环境下直接调用远程接口那就得耗费一些功夫了,需要用到远程代理。
下面是我盗的图:
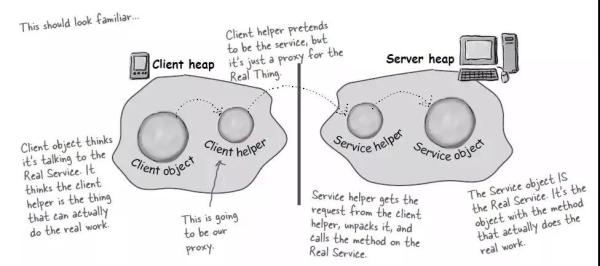
远程代理
通信时序如下:
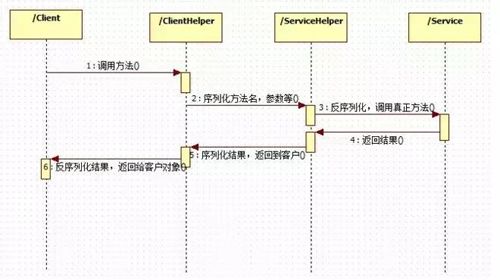
通信时序
消费者端没有具体的实现,需要调用接口时动态的去创建一个代理类。与 Spirng 集成的情况,那直接在 Bean 构建的时候注入代理类。
下面是构建代理类:
- import java.lang.reflect.Proxy;
- public class JdkProxy {
- public static Object getInstance(Class cls){
- JdkMethodProxy invocationHandler = new JdkMethodProxy();
- Object newProxyInstance = Proxy.newProxyInstance(
- cls.getClassLoader(),
- new Class[] { cls },
- invocationHandler);
- return (Object)newProxyInstance;
- }
- }
- import java.lang.reflect.InvocationHandler;
- import java.lang.reflect.Method;
- public class JdkMethodProxy implements InvocationHandler {
- @Override
- public Object invoke(Object proxy, Method method, Object[] parameters) throws Throwable {
- //如果传进来是一个已实现的具体类
- if (Object.class.equals(method.getDeclaringClass())) {
- try {
- return method.invoke(this, parameters);
- } catch (Throwable t) {
- t.printStackTrace();
- }
- //如果传进来的是一个接口
- } else {
- //实现接口的核心方法
- //return RemoteInvoking.invoking(serviceName, serializationType, //timeOut,loadBalanceStrategy,method, parameters);
- }
- return null;
- }
- }
代理会做很多事情,对请求服务的名称及参数信息的序列化、通过路由选择最为合适服务提供者、建立通讯连接发送请求信息(或者直接发起 Http 请求)、最后返回获取到的结果。
当然这里面需要考虑很多问题,如调用超时,请求异常,通讯连接的缓存,同步服务调用还是异步服务调用等等。
同步服务调用:客户端发起远程服务调用请求,用户线程完成消息序列化之后,将消息投递到通信框架,然后同步阻塞,等待通信线程发送请求并接收到应答之后,唤醒同步等待的用户线程,用户线程获取到应答之后返回。
异步服务调用:基于 Java 的 Future 机制,客户端发起远程服务调用请求,该请求会被标上 RequestId,同时建立一个与 RequestId 对应的 Future,客户端通过 Future 的 Get 方法获取结果时会被阻塞。
服务端收到请求应达会回传 RequestId,通过 RequestId 去解除对应 Future 的阻塞,同时 Set 对应结果,最后客户端获取到结果。
构建 Future,以 RequestId 为 Key,Put 到线程安全的 Map 中。Get 结果时需要写入 Time Out 超时时间,防止由于结果的未返回而导致的长时间的阻塞。
- SyncFuture
syncFuture =new SyncFuture (); - SyncFutureCatch.syncFutureMap.put(rpcRequest.getRequestId(), syncFuture);
- try {
- RpcResponse rpcResponse= syncFuture.get(timeOut,TimeUnit.MILLISECONDS); return rpcResponse.getResult();
- }catch (Exception e){
- throw e;
- }finally {
- SyncFutureCatch.syncFutureMap.remove(rpcRequest.getRequestId());
- }
结果返回时通过回传的 RequestId 获取对应 Future 写入 Response,Future 线程解除阻塞:
- log.debug("Tcp Client receive head:"+headAnalysis+"Tcp Client receive data:" +rpcResponse);
- SyncFuture
syncFuture= SyncFutureCatch.syncFutureMap.get(rpcResponse.getRequestId()); - if(syncFuture!=null){
- syncFuture.setResponse(rpcResponse);
- }
- import java.util.concurrent.CountDownLatch;
- import java.util.concurrent.Future;
- import java.util.concurrent.TimeUnit;
- public class SyncFuture
implements Future { - // 因为请求和响应是一一对应的,因此初始化CountDownLatch值为1。
- private CountDownLatch latch = new CountDownLatch(1);
- // 需要响应线程设置的响应结果
- private T response;
- // Futrue的请求时间,用于计算Future是否超时
- private long beginTime = System.currentTimeMillis();
- public SyncFuture() {
- }
- @Override
- public boolean cancel(boolean mayInterruptIfRunning) {
- return false;
- }
- @Override
- public boolean isCancelled() {
- return false;
- }
- @Override
- public boolean isDone() {
- if (response != null) {
- return true;
- }
- return false;
- }
- // 获取响应结果,直到有结果才返回。
- @Override
- public T get() throws InterruptedException {
- latch.await();
- return this.response;
- }
- // 获取响应结果,直到有结果或者超过指定时间就返回。
- @Override
- public T get(long timeOut, TimeUnit unit) throws InterruptedException {
- if (latch.await(timeOut, unit)) {
- return this.response;
- }
- return null;
- }
- // 用于设置响应结果,并且做countDown操作,通知请求线程
- public void setResponse(T response) {
- this.response = response;
- latch.countDown();
- }
- public long getBeginTime() {
- return beginTime;
- }
- }
- SyncFuture
syncFuture =new SyncFuture (); - SyncFutureCatch.syncFutureMap.put(rpcRequest.getRequestId(), syncFuture);
- RpcResponse rpcResponse= syncFuture.get(timeOut,TimeUnit.MILLISECONDS);
- SyncFutureCatch.syncFutureMap.remove(rpcRequest.getRequestId());
除了同步服务调用,异步服务调用,还有并行服务调用,泛化调用等调用形式。
高可用
简单的介绍了下分布式服务框架,下面来说下分布式系统的高可用。一个系统设计开发出来,三天两晚就出个大问题,导致无法使用,那这个系统也不是什么好系统。
业界流传一句话:"我们系统支持 X 个 9 的可靠性"。这个 X 是代表一个数字,X 个 9 表示在系统 1 年时间的使用过程中,系统可以正常使用时间与总时间(1 年)之比。
3 个 9:(1-99.9%)*365*24=8.76 小时,表示该系统在连续运行 1 年时间里最多可能的业务中断时间是 8.76 小时,4 个 9 即 52.6 分钟,5 个 9 即 5.26 分钟。要做到如此高的可靠性,是非常大的挑战。
一个大型分布式项目可能是由几十上百个项目构成,涉及到的服务成千上万,主链上的一个流程就需要流转多个团队维护的项目。
拿 4 个 9 的可靠性来说,平摊到每个团队的时间可能不到 10 分钟。这 10 分钟内需要顶住压力,以最快的时间找到并解决问题,恢复系统的可用。
下面说说为了提高系统的可靠性都有哪些方案:
服务检测:某台服务器与注册中心的连接中断,其提供的服务也无响应时,系统应该能主动去重启该服务,使其能正常对外提供。
故障隔离:集群环境下,某台服务器能对外提供服务,但是因为其他原因,请求结果始终异常。
这时就需要主动将该节点从集群环境中剔除,避免继续对后面的请求造成影响,非高峰时期再尝试修复该问题。至于机房故障的情况,只能去屏蔽整个机房了。
目前饿了么做的是异地多活,即便单边机房挂了,流量也可以全量切换至另外一边机房,保证系统的可用。
监控:包含业务监控、服务异常监控、DB 中间件性能的监控等,系统出现异常的时候能及时的通知到开发人员。等到线下报上来的时候,可能影响已经很大了。
压测:产线主链路的压测是必不可少的,单靠集成测试,有些高并发的场景是无法覆盖到的,压测能暴露平常情况无法出现的问题,也能直观的提现系统的吞吐能力。当业务激增时,可以考虑直接做系统扩容。
SOP 方案与演练:产线上随时都可能会发生问题,抱着出现问题时再想办法解决的态度是肯定不行的,时间根本来不及。
提前做好对应问题的 SOP 方案,能节省大量时间,尽快的恢复系统的正常。当然平常的演练也是不可少的,一旦产线故障可以做到从容不迫的去应对和处理。
除了上述方案外,还可以考虑服务策略的使用:
降级策略:业务高峰期,为了保证核心服务,需要停掉一些不太重要的业务。
如双十一期间不允许发起退款、只允许查看 3 个月之内的历史订单等业务的降级,调用服务接口时,直接返回的空结果或异常等服务的降级,都属于分布式系统的降级策略。
服务降级是可逆操作,当系统压力恢复到一定值不需要降级服务时,需要去除降级,将服务状态恢复正常。
服务降级主要包括屏蔽降级和容错降级:
- 屏蔽降级:分布式服务框架直接屏蔽对远程接口的请求,不发起对远程服务的调用,直接返回空结果、抛出指定异常、执行本地模拟接口实现等方式。
- 容错降级:非核心服务不可调用时,可以对故障服务做业务放通,保证主流程不受影响。如请求超时、消息解码异常、系统拥塞保护异常, 服务提供方系统异常等情况。
笔者之前就碰到过因双方没有做容错降级导致的系统故障的情况。午高峰时期,对方调用我们的一个非核心查询接口,我们系统因为 Bug 问题一直异常,导致对方调用这个接口的页面异常而无法跳转到主流程页面,影响了产线的生产。当时对方紧急发版才使系统恢复正常。
限流策略:说到限流,最先想到的就是秒杀活动了,一场秒杀活动的流量可能是正常流量的几百至几千倍,如此高的流量系统根本无法处理,只能通过限流来避免系统的崩溃。
服务的限流本质和秒杀活动的限流是一样的,都是限制请求的流入,防止服务提供方因大量的请求而崩溃。
限流算法:令牌桶、漏桶、计数器算法。上述算法适合单机的限流,但涉及到整个集群的限流时,得考虑使用缓存中间件了。
例如:某个服务 1 分钟内只允许请求 2 次,或者一天只允许使用 1000 次。
由于负载均衡存在,可能集群内每台机器都会收到请求,这种时候就需要缓存来记录调用方某段时间内的请求次数,再做限流处理。Redis 就很适合做此事。
熔断策略:熔断本质上是一种过载保护机制,这一概念来源于电子工程中的断路器,当电流过大时,保险丝会熔断,从而保护整个电路。
同样在分布式系统中,当被调用的远程服务无法使用时,如果没有过载保护,就会导致请求的资源阻塞在远程服务器上耗尽资源。
很多时候,刚开始可能只是出现了局部小规模的故障,然而由于种种原因,故障影响范围越来越大,最终导致全局性的后果。
当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护自己以及系统整体的可用性,可以暂时切断对下游服务的调用。
熔断器的设计思路:
- Closed:初始状态,熔断器关闭,正常提供服务。
- Open: 失败次数,失败百分比达到一定的阈值之后,熔断器打开,停止访问服务。
- Half-Open:熔断一定时间之后,小流量尝试调用服务,如果成功则恢复,熔断器变为 Closed 状态。
数据一致性
一个系统设计开发出来,必须保证其运行的数据准确和一致性。拿支付系统来说:用户银行卡已经扣款成功,系统里却显示失败,没有给用户的虚拟帐户充值上,这会引起客诉。
说的再严重点,用户发起提现,资金已经转到其银行账户,系统却没扣除对应虚拟帐号的余额,直接导致资金损失了。如果这时候用户一直发起提现,那就酸爽了。
CAP 原则
说到数据一致性,就不得不说到 CAP 原则。CAP 原则中指出任何一个分布式系统中,Consistency(一致性 C)、 Availability(可用性 A)、Partition tolerance(分区容错性 P),三者不可兼得。
传统单机数据库基于 ACID 特性(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)) ,放弃了分区容错性,能做到可用性和一致性。
对于一个分布式系统而言,分区容错性是一个最基本的要求。既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,会出现节点与节点之间的网络通讯。
而网络问题又是一定会出现的异常情况,分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。
系统架构师往往需要把精力花在如何根据业务特点在一致性和可用性之间寻求平衡。
集中式系统,通过数据库事务的控制,能做到数据的强一致性。但是分布式系统中,涉及多服务间的调用,通过分布式事务的方案:
- 两阶段提交(2PC)
- 三阶段提交(3PC)
- 补偿事务(TCC)
- ...
虽然能实现数据的强一致,但是都是通过牺牲可用性来实现。
BASE 理论
BASE 理论是对 CAP 原则中一致性和可用性权衡的结果:Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent(最终一致性)。
BASE 理论,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 原则逐步演化而来的。
其最核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
基本可用:是指分布式系统在出现不可预知故障的时候,允许损失部分可用性,这不等价于系统不可用。
软状态:指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
最终一致性:强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一致的状态。
因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
总的来说,BASE 理论面向的是大型高可用可扩展的分布式系统,和传统的事物 ACID 特性是相反的。
它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID 特性和 BASE 理论往往又会结合在一起。
结语
分布式系统涉及到的东西还有很多,如:分布式锁、定时调度、数据分片、性能问题、各种中间件的使用等,笔者分享只是了解到的那一小部分的知识而已。
之前本着学习的目的也写过一个非常简单的分布式服务框架 blackRpc,通过它了解了分布式服务框架内部的一些活动。
本文中所有代码都能在该项目中找到,有兴趣读者可以看看:
- https://github.com/wangshiyu/blackRpc