吴恩达机器学习:神经网络 | 反向传播算法
上一周我们学习了 神经网络 | 多分类问题。我们分别使用 逻辑回归 和 神经网络 来解决多分类问题,并了解到在特征数非常多的情况下,神经网络是更为有效的方法。这周的课程会给出训练 神经网络 所使用的 代价函数,并使用 反向传播 算法来计算梯度。笔者会给出 反向传播 算法中重要的思路和推导,但不会包含所有的计算步骤。
点击 课程视频 你就能不间断地学习 Ng 的课程,关于课程作业的 Python 代码已经放到了 Github 上,点击 课程代码 就能去 Github 查看( 无法访问 Github 的话可以点击 Coding 查看 ),代码中的错误和改进欢迎大家指出。
以下是 Ng 机器学习课程第四周的笔记。
代价函数
假设我们的多分类问题有 K K 个分类,神经网络共有 L L 层,每一层的神经元个数为 sl s l ,那么神经网络的 代价函数 为:
其中的第二项为 正则化 项,是网络中所有权值的平方和。第一项与逻辑回归中的 代价函数 类似,但这里我们需要累加所有输出神经元的误差。
梯度计算
为了能够使用 梯度下降 算法来训练网络,我们需要计算代价函数的梯度。一种很直观的方法就是使用数值计算,对于某个 Θij Θ i j ,给它加上减去一个很小的量 ϵ ϵ 来计算梯度:
但稍微分析一下算法的复杂度就能知道,这样的方法十分缓慢。对于每一组数据,我们需要计算所有权值的梯度,总的计算次数 = 训练数据个数 x 网络权值个数 x 前向传播计算次数 。在通常情况下这样的复杂度是无法接受的,所以我们仅使用这个方法来验证 反向传播 算法计算的梯度是否正确。
链式法则
为了能够理解之后对于 反向传播 公式的推导,我们首先要了解一个关于多元复合函数求导的 链式法则。对于多元函数 z=f(u,v) z = f ( u , v ) ,其中 u=h(x,y) u = h ( x , y ) , v=g(x,y) v = g ( x , y ) ,那么:
链式法则 告诉我们有多个层次的多元复合函数,下一层次的导数可以由上一层次推得。
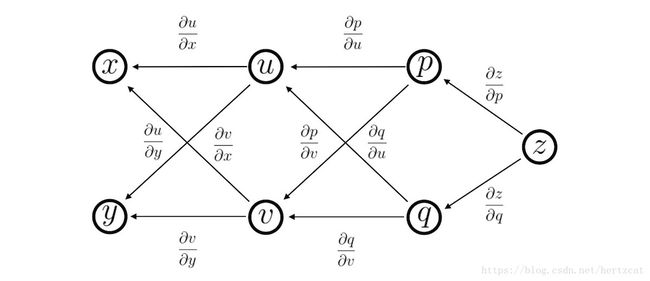
上图中笔者有意多加了一层,这里 p p 是 u,v u , v 的函数, q q 是 u,v u , v 的函数, z z 是 p,q p , q 的函数。对于要计算的 ∂z∂x ∂ z ∂ x 与 ∂z∂y ∂ z ∂ y ,上式仍成立,原因是我们可以把 z z 看作 u,v u , v 的函数。这相当于我们把:
简化为了只与上一层相关,利用上一层计算完成的结果 ∂z∂u ∂ z ∂ u 和 ∂z∂v ∂ z ∂ v 而不用从头算起:
一般的,对于函数 y y ,如果它能看做 z1,z2⋯,zn z 1 , z 2 ⋯ , z n 的函数,而 zi z i 为 t t 的函数,则:
神经网络就是一个层次很多的多元函数,我们可以隐约从 链式法则 中感觉到反向传播的意味。
公式推导
为了施展 反向传播 的魔法,我们首要要引入一个中间变量 δ δ ,定义为:
其中 l l 为第几层, j j 表示第 l l 层的第几个神经元, z z 为上次课程提到的中间变量( 为了让式子看上去更清晰,反向传播 中的公式上标不使用括号 )。 δ δ 被称为第 l l 层第 j j 个神经元的误差。反向传播 就是先计算每一层每个神经元的误差,然后通过误差来得到梯度的。
首先来看输出层的误差:
对它使用 链式法则 得到:
而只有当 k==j k == j 时,右边部分才不为 0 0 ,所以:
对于其它层的误差:
使用 链式法则:
而其中:
求偏导得:
所以:
最后同样使用 链式法则 来计算:
由于:
只有当 k=i k = i , p=j p = j 时留下一项:
反向传播
有了 (1) (2) (3) 式,就可以来完成 反向传播 算法了( 需要注意的是刚才所推导的式子都是针对一组训练数据而言的 )。
- 对于所有的 l,i,j l , i , j 初始化 Δlij=0 Δ i j l = 0
- 对于 m m 组训练数据, k k 从 1 1 取到 m m :
- 令 a1=x(k) a 1 = x ( k )
- 前向传播,计算各层激活向量 al a l
- 使用 (1) 式,计算输出层误差 δL δ L
- 使用 (2) 式,计算其它层误差 δL−1,δL−2,...,δ2 δ L − 1 , δ L − 2 , . . . , δ 2
- 使用 (3) 式,累加 Δlij Δ i j l , Δlij:=Δlij+aljδl+1i Δ i j l := Δ i j l + a j l δ i l + 1
- 计算梯度矩阵:
Dlij=⎧⎩⎨⎪⎪1mΔlij+λmΘlij1mΔ(l)ijif j≠0if j=0 D i j l = { 1 m Δ i j l + λ m Θ i j l if j ≠ 0 1 m Δ i j ( l ) if j = 0- 更新权值 Θl:=Θl+αDl Θ l := Θ l + α D l
权值初始化
最后提一下权值的初始化。对于神经网络,不能像之前那样使用相同的 0 值来初始化,这会导致每层的 逻辑单元 都相同。因此我们使用随机化的初始化方法,使得 −δ≤Θlij≤δ − δ ≤ Θ i j l ≤ δ 。
So~,这周学完了 神经网络 和它的学习算法,大家有没有觉得很神奇呢?