深度学习在推荐系统中的应用及代码集锦(4)
[19] Neural Factorization Machines for Sparse Predictive Analytics
Xiangnan He, Tat-Seng Chua
SIGIR 2017
https://www.comp.nus.edu.sg/~xiangnan/papers/sigir17-nfm.pdf
多种类别型变量利用one-hot编码之后构成的特征会比较稀疏,针对这种问题,这篇文章提出一种新的模型,神经分解机模型(Neural Factorization Machine ,NFM),该模型可以应对稀疏数据。该模型不仅可以对特征之间的二阶关联进行建模,而且可以利用神经网络对更高阶的特征关联进行建模。这样可以使得神经分解机模型相对FM表达能力更强,FM可以看做不含隐含层的神经分解机模型。
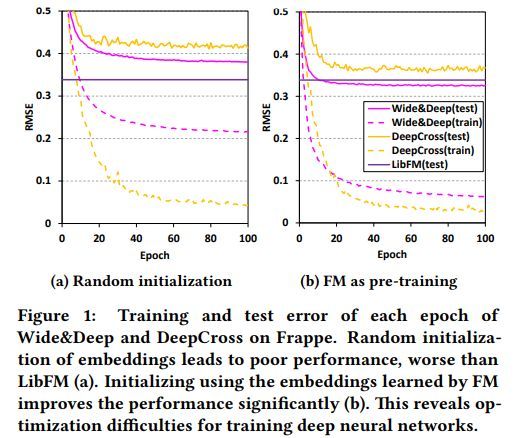
各方法初始化效果对比如下
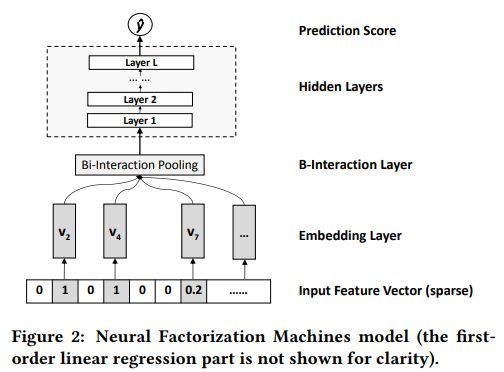
神经分解机模型示例如下
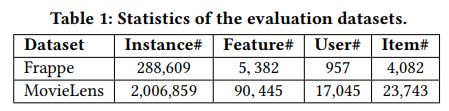
下面是数据集统计信息
各方法效果对比如下

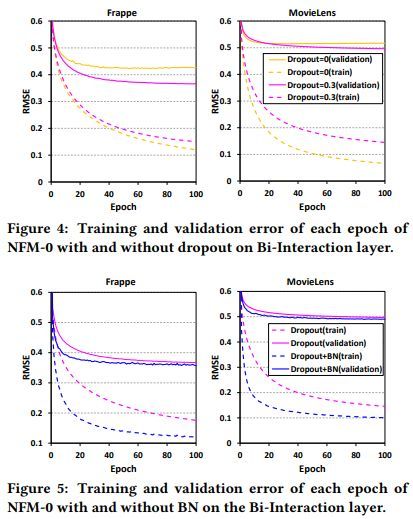
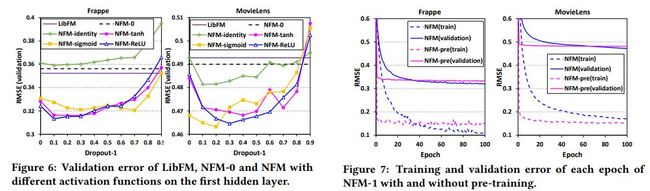
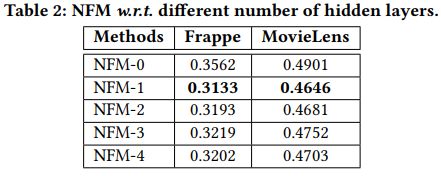
层数的影响如下
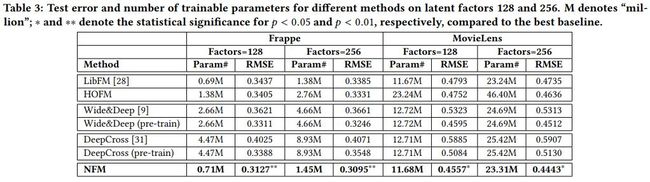
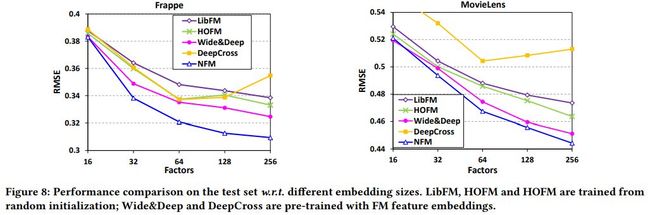
下面是多种方法在多个数据集上不同参数下的对比
代码地址
https://github.com/hexiangnan/neural_factorization_machine
该代码利用Python和Tensorflow实现
 我是分割线
我是分割线
[20] On Sampling Strategies for Neural Network-based Collaborative Filtering
Ting Chen et al.
KDD 2017
http://web.cs.ucla.edu/~yzsun/papers/2017_kdd_sampling.pdf
这篇文章提出一种基于神经网络的推荐框架,并且通过在随机梯度下降中加入采样策略来提高效率。具体方案为将损失函数和用户商品二部图联系起来,其中损失函数是定义在连接上的,而主要的计算负荷在节点上。这种损失函数是基于图的损失函数,小批采样策略不同计算复杂度也不同。作者提出三种新的采样策略,这些采样策略可以显著提升训练效率(可以提升30倍)。
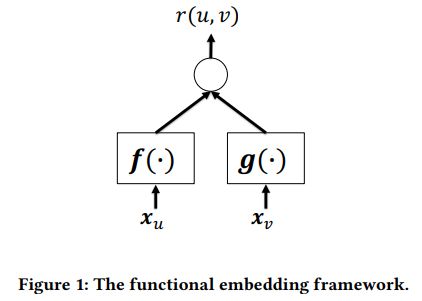
函数嵌入框架如下
用于推荐系统中的损失函数示例如下

标准模型训练流程如下

不同方法训练时间对比如下

损失函数所对应的关联示例如下

负采样算法流程如下

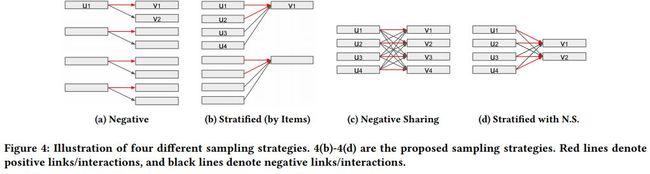
不同的采样策略图示如下
分层抽样流程示例如下

负共享算法如下

负共享用于分层采样算法示例如下

不同采样策略计算复杂度对比如下

不同采样策略的加速效果对比如下

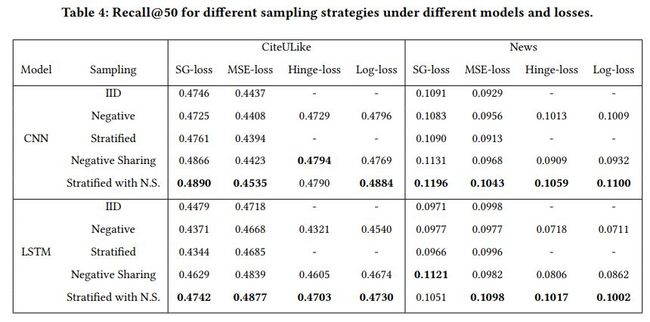
不同采样策略,模型,损失函数组合效果对比如下
代码地址
https://github.com/chentingpc/NNCF
该代码主要基于Python,Keras以及Tensorflow实现
我是分割线
[21] Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention
Jingyuan Chen et al.
SIGIR 2017
https://www.comp.nus.edu.sg/~xiangnan/papers/sigir17-AttentiveCF.pdf
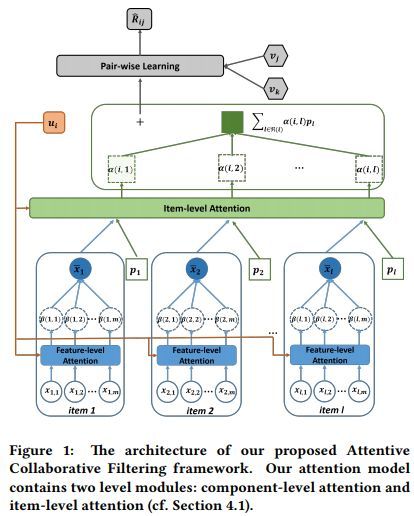
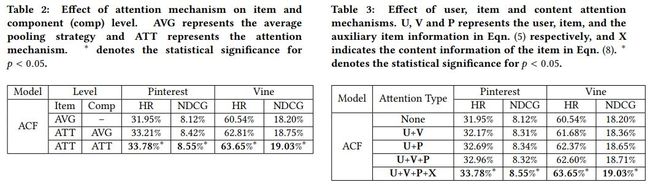
这篇文章在协同过滤中引入了注意力机制,用于解决多媒体推荐中的商品以及元素层级的隐式反馈所带来的挑战。该模型简称ACF,attentive collaborative filtering。该注意力模型是一种神经网络,由两个注意力模块构成,元素层面的注意力模块,该模块用于提取内容特征,比如用卷积神经网络提取图像或视频中的特征;还包含一个商品层面的注意力模块,用于学习对商品偏好的打分。ACF可以很容易融入传统带隐式反馈的协同过滤模型,比如BPR,SVD++,尤其是里利用SGD训练的模型。
ACF框架示例如下
ACF 伪代码如下

数据集统计如下
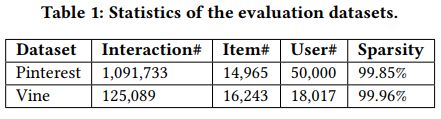
注意力机制对模型效果影响如下
代码地址
https://github.com/ChenJingyuan91/ACF
该代码基于Python和Theano实现
我是分割线
[22] Embedding Factorization Models for Jointly Recommending Items and User Generated Lists
Da Cao et al.SIGIR 2017
http://www.nextcenter.org/wp-content/uploads/2018/02/Embedding-Factorization-Models-for-Jointly-Recommending-User-Generated-Lists-and-Their-Contained-Items.pdf
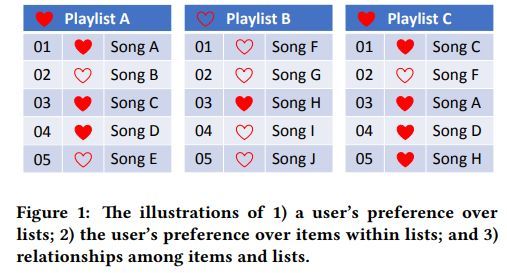
这篇文章提出嵌入分解机模型,该模型在传统分解机模型的基础上利用嵌入算法融入商品-商品的共现信息。利用分解机模型来学习用户对商品以及商品列表的偏好,同时利用嵌入算法来挖掘商品以及列表之间的共现信息。这两种模型共享隐含因子。该模型可以解决新商品的冷启动问题,这里的新商品即为没有被购买过,但是出现在用户生成列表中的商品。
用户偏好列表等图示如下
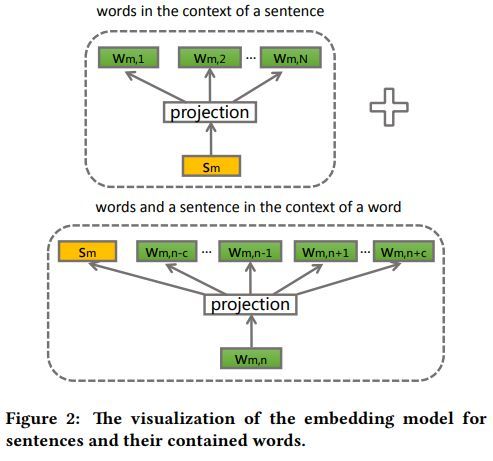
句子及单词的嵌入模型图示如下
新商品冷启动图示如下

EFM优化算法伪代码如下


数据集统计信息如下

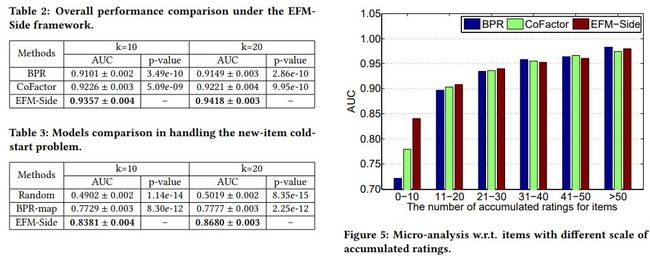
各算法效果对比如下

代码地址
https://listrec.wixsite.com/efms
该代码基于Python,numpy以及scipy实现
我是分割线
马上就要国庆了,提前祝大家国庆快乐
另外,为方便大家交流,已开通以下几个群
自然语言处理交流群
计算机视觉交流群
推荐系统交流群
广告算法交流群
自动驾驶交流群(暂未开通)
语音识别交流群
其他推荐的群(暂未开通)
欢迎感兴趣的朋友加入,入群方式:
关注公众号之后在后台发送"入群"或"加群",小编会把您拉进相应的群,谢谢
我是分割线
可以通过以下方式关注
(长按->识别图中二维码->关注)

本公众号(微信号:mlanddlanddm)专注于机器学习(主要包含但不限于深度学习)相关知识分享,其中涉及自然语言处理、推荐系统以及图像处理前沿论文等,欢迎大家关注交流
我是分割线
您可能感兴趣
本文是深度学习在推荐系统中的应用及代码集锦第四篇,上面链接是前三篇,本文的论文编号沿用前三篇的论文编号