Python爬取百度地图智慧交通-城市拥堵指数
第一次写文章
分享一下我的大数据处理课程的一次作业,爬取百度地图智慧交通的城市拥堵指数内容,链接(以长春市为例):http://jiaotong.baidu.com/top/report/?citycode=53
首先,鼠标右键查看网页源代码

有没有发现一些问题,在body标签里没有div的内容,只有script标签内容。但是用鼠标右键,检查元素(F12)中是可以看到内容的,我想到了用Python中selenium的解析库来做。
新的问题随着新办法的产生而产生,页面中有些数据不是文字格式,而是通过数据可视化形成的绘图对象,如图:
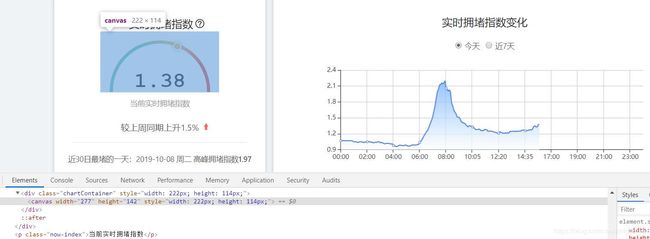
请教了我们实验室的师兄,在网页源码里体现不到的数据,一般是通过json文件发送的。
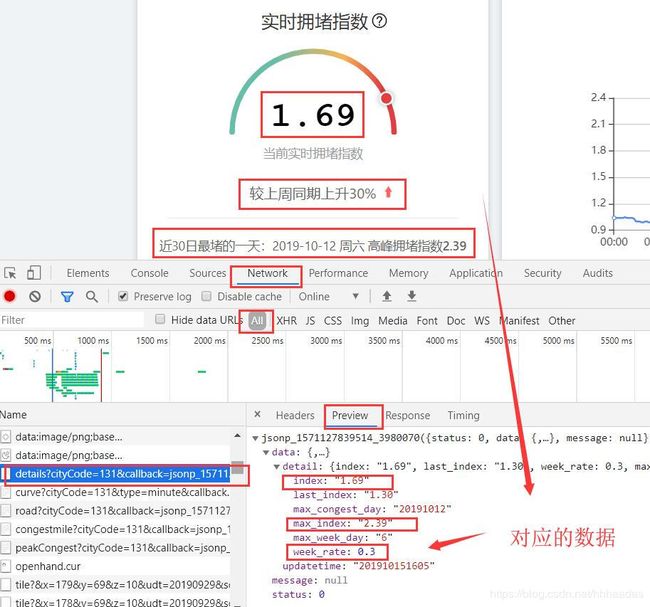
右键检查元素(F12)找到Network,左侧的Name栏是页面发送的相关请求,右侧有Headers、Preview、Response等属性,我们单击Preview会出现一些json数据,经过对比我发现正是我在源码里获取不到的绘图对象的数据。
那么这个数据我们怎么爬取呢?
首先,点击对应请求的Headers,我们可以看到页面请求的地址Request URL

这个Request URL就是我们要爬取的目标链接,这个地址里的json数据对应的是“实时拥堵指数”的数据,对于其他的数据,我们一一寻找即可。
了解了如何获取目标链接和要爬取哪些数据后,我们开始代码环节。
- 导入要使用的库
import requests
import re
import json
- 获取页面
def get_page(url):
try:
response = requests.get(url)
if response.content: # 返回成功
return response
except requests.ConnectionError as e:
print('url出错', e.args)
我们运行一下程序,输出get_page(url)的返回值和返回值类型。
url = 'https://jiaotong.baidu.com/trafficindex/city/details?cityCode=53&callback=jsonp_1570959868686_520859'
print(type(get_page(url)))
print(get_page(url))
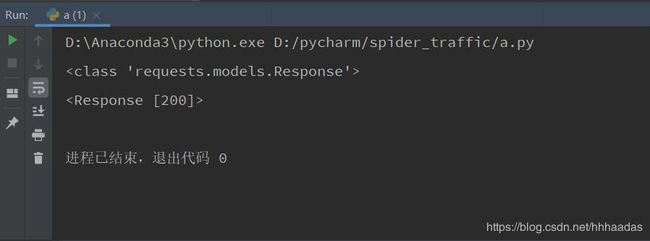
并没有输出我们看到的json数据,是因为没有将get_page(url)的返回值转为文本格式。
url = 'https://jiaotong.baidu.com/trafficindex/city/details?cityCode=53&callback=jsonp_1570959868686_520859'
print(type(get_page(url)))
print(get_page(url).text)
获取文本格式后的输出:

- 解析页面
获取到文本格式的页面信息后,我们要对页面进行解析,和解析网页源码类似,我们要找一下,获取到的页面信息有哪些是我们需要的。
def get_detail(page):
transformData = json.loads(page.text)
print(transformData)
在测试运行上面的代码时出错了,错误类型:json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
查了一下这个错误,json.loads()这个函数里传的值必须是json格式,重新打印了一下返回的页面文本,我发现返回的是这个:jsonp_1570959868686_520859({“status”:0,“data”:{“detail”:{“index”:“1.49”,“last_index”:“1.51”,“week_rate”:-0.013,“max_congest_day”:“20191008”,“max_week_day”:“2”,“max_index”:“1.97”},“updatetime”:“201910151635”},“message”:null})
json格式的数据类似与Python中的字典:{key : value},显然返回的页面文本有一些其他数据,我们要对这些数据进行一下筛选,找出我们需要的那一部分。
# 获取实时拥堵指数内容
def get_detail(page):
transformData = json.loads(re.findall(r'[(](.*?)[)]', page.text)[0])
detail = transformData['data']['detail']
print('实时拥堵指数数据:')
for i in detail:
print(str(i)+':'+str(detail[i]))
用正则表达式获取页面返回文本中括号里的内容,这里用到了re.findall()函数,re.findall(pattern,string)可以将传入的字符串以列表的形式返回,因此,这里取re.findall(pattern, page.text)[0](返回只有一串json文本,只取列表中的第一个即可)。用json.loads()读取处理过的数据,加载成Python中的字典格式。
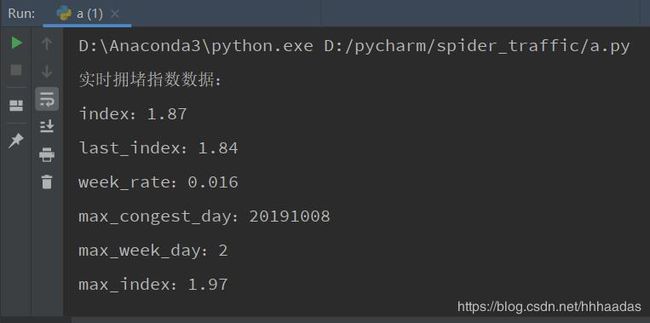
页面中获取不到的实时交通指数数据,已经被我们成功获取到了,再将获取到的数据写入txt文件中即可。
对于其他的数据,我们也可以用这种方法进行获取,下面是我爬取百度地图智慧交通-城市拥堵指数页面的全部代码,供大家参考学习。
import requests
import re
import json
def get_page(url):
try:
response = requests.get(url)
if response.content: # 返回成功
return response
except requests.ConnectionError as e:
print('url出错', e.args)
def write_to_file(content):
with open('长春市交通情况数据爬取.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False)+'\n')
# f.close()
# 获取实时拥堵指数内容
def get_detail(page):
transformData = json.loads(re.findall(r'[(](.*?)[)]', page.text)[0])
detail = transformData['data']['detail']
for i in detail:
write_to_file(str(i)+':'+str(detail[i]))
print(str(i)+':'+str(detail[i]))
# 获取实时拥堵指数变化内容
def get_curve(page):
transformData = json.loads(re.findall(r'[(](.*?)[)]', page.text)[0])
curve_detail = transformData['data']['list']
k = 0
for roadrank_list in curve_detail:
print('---------------分割线---------------')
print(k)
write_to_file(str(k)+str(roadrank_list))
k += 1
print(roadrank_list)
# 获取实时道路拥堵指数内容
def get_road(page):
transformData = json.loads(re.findall(r'[(](.*?)[)]', page.text)[0])
detail = transformData['data']['detail']
for i in detail:
write_to_file(str(i)+':'+str(detail[i]))
print(str(i)+':'+str(detail[i]))
# 获取实时拥堵里程内容
def get_congestmile(page):
transformData = json.loads(re.findall(r'[(](.*?)[)]', page.text)[0])
congest = transformData['data']['congest']
for i in congest:
write_to_file(str(i)+':'+str(congest[i]))
print(str(i)+':'+str(congest[i]))
# 获取昨日早晚高峰内容
def get_peakCongest(page):
transformData = json.loads(re.findall(r'[(](.*?)[)]', page.text)[0])
peak_detail = transformData['data']['peak_detail']
for i in peak_detail:
write_to_file(str(i)+':'+str(peak_detail[i]))
print(str(i)+':'+str(peak_detail[i]))
# 获取全部道路拥堵情况
def get_roadrank(page):
transformData = json.loads(re.findall(r'[(](.*?)[)]', page.text)[0])
roadrank_detail = transformData['data']['list']
for roadrank_list in roadrank_detail:
write_to_file('---------------分割线---------------')
print('---------------分割线---------------')
for element in roadrank_list:
if str(element) != 'links' and str(element) != 'nameadd':
write_to_file(str(element)+':'+str(roadrank_list[element]))
print(str(element)+':'+str(roadrank_list[element]))
if __name__ == '__main__':
url_detail = 'https://jiaotong.baidu.com/trafficindex/city/details?cityCode=53&callback=jsonp_1570959868686_520859'
url_curve = 'https://jiaotong.baidu.com/trafficindex/city/curve?cityCode=53&type=minute&callback=jsonp_1571018819971_8078256'
url_road = 'https://jiaotong.baidu.com/trafficindex/city/road?cityCode=53&callback=jsonp_1571014746541_9598712'
url_congestmile = 'https://jiaotong.baidu.com/trafficindex/city/congestmile?cityCode=53&callback=jsonp_1571014746542_5952586'
url_peakCongest = 'https://jiaotong.baidu.com/trafficindex/city/peakCongest?cityCode=53&callback=jsonp_1571014746543_3489265'
url_roadrank = 'https://jiaotong.baidu.com/trafficindex/city/roadrank?cityCode=53&roadtype=0&callback=jsonp_1571016737139_1914397'
url_highroadrank = 'https://jiaotong.baidu.com/trafficindex/city/roadrank?cityCode=53&roadtype=1&callback=jsonp_1571018628002_9539211'
# 获取实时拥堵指数内容
print('获取实时拥堵指数内容')
write_to_file('获取实时拥堵指数内容')
get_detail(get_page(url_detail))
# 获取实时拥堵指数变化内容
print('获取实时拥堵指数变化内容')
write_to_file('获取实时拥堵指数变化内容')
get_curve(get_page(url_curve))
# 获取实时道路拥堵指数内容
print('获取实时道路拥堵指数内容')
write_to_file('获取实时道路拥堵指数内容')
get_road(get_page(url_road))
# 获取实时拥堵里程内容
print('获取实时拥堵里程内容')
write_to_file('获取实时拥堵里程内容')
get_congestmile(get_page(url_congestmile))
# 获取昨日早晚高峰内容
print('获取昨日早晚高峰内容')
write_to_file('获取昨日早晚高峰内容')
get_peakCongest(get_page(url_peakCongest))
# 获取全部道路拥堵情况
print('获取全部道路拥堵情况')
write_to_file('获取全部道路拥堵情况')
get_roadrank(get_page(url_roadrank))
# 获取高速/快速路拥堵情况
print('获取高速/快速路拥堵情况')
write_to_file('获取高速/快速路拥堵情况')
get_roadrank(get_page(url_highroadrank))