batch size和模型宽度对训练结果的影响
在进行网络学习时对于有的网络大小和batch size 总会出现梯度消失,好奇就进行了以下实验,想要探明什么情况易于出现梯度消失,顺便探究一下准确率与超参数的关系。
此实验室用的是VGG11网络,比较在不同的网络宽度和不同的batch size下的训练结果。
VGG11的网络结构有5个卷积块,前2块使用单卷积层,而后3块使用双卷积层。第一块的输入输出通道分别是3和64,之后每次对输出通道数翻倍,直到变为512。因为这个网络使用了8个卷积层和3个全连接层,所以经常被称为VGG-11。

实验中设置了一个参数ratio,将网络宽度(特征图数量)变为ratio分之一。
| batch size & ratio | 1 | 2 | 4 | 8 |
|---|---|---|---|---|
| 16 | 梯度消失 | 梯度消失 | 梯度消失 | 梯度消失 |
| 32 | 梯度消失 | 梯度消失 | 收敛1 | 收敛、梯度消失2 |
| 64 | 收敛、梯度消失3 | 梯度消失、偶尔收敛4 | 收敛、梯度消失5 | |
| 128 | 收敛6 | 收敛7 |
实验结果说明:
- 模型大小固定时
- 对于1/8大小的模型:batch size大的最后收敛所达到的准确率越高
- 对于1/4大小的模型:batch size 64和128的准确率相近,都明显高于batch size 32
- batch size 固定时
- 对于64的batch size :大模型明显要比小模型准确率高
- 对于128的batch size : 1/8和1/4大小的模型准确率相近,更大的模型由于显存不够无法进行实验
- batch size 较小时易出现梯度消失,原因是?
结论为:大模型、较大的batch size 准确率较高
注:实验中并未出现令test acc下降的过拟合现象,train acc虽然一直在增加,test acc趋于恒定,并未下降。
batch size : 32,模型大小1/4

epoch 1, loss 1.7925, train acc 0.330, test acc 0.458, time 63.9 sec
epoch 2, loss 1.4208, train acc 0.483, test acc 0.543, time 63.2 sec
epoch 3, loss 1.2504, train acc 0.552, test acc 0.587, time 63.2 sec
epoch 4, loss 1.1322, train acc 0.597, test acc 0.627, time 63.2 sec
epoch 5, loss 1.0195, train acc 0.637, test acc 0.651, time 63.2 sec
epoch 6, loss 0.9380, train acc 0.671, test acc 0.659, time 63.1 sec
epoch 7, loss 0.8710, train acc 0.695, test acc 0.668, time 63.3 sec
epoch 8, loss 0.8077, train acc 0.716, test acc 0.688, time 63.3 sec
epoch 9, loss 0.7488, train acc 0.738, test acc 0.683, time 63.3 sec
epoch 10, loss 0.7070, train acc 0.754, test acc 0.690, time 63.4 sec
epoch 11, loss 0.6591, train acc 0.770, test acc 0.692, time 63.4 sec
epoch 12, loss 0.6129, train acc 0.787, test acc 0.694, time 63.3 sec
epoch 13, loss 0.5844, train acc 0.797, test acc 0.697, time 63.3 sec
epoch 14, loss 0.5515, train acc 0.809, test acc 0.709, time 63.3 sec
epoch 15, loss 0.5278, train acc 0.817, test acc 0.704, time 63.3 sec
epoch 16, loss 0.5001, train acc 0.827, test acc 0.702, time 63.3 sec
epoch 17, loss 0.4771, train acc 0.836, test acc 0.704, time 63.4 sec
epoch 18, loss 0.4582, train acc 0.842, test acc 0.699, time 63.3 sec
epoch 19, loss 0.4376, train acc 0.849, test acc 0.700, time 63.3 sec
epoch 20, loss 0.4279, train acc 0.853, test acc 0.705, time 63.4 sec
epoch 21, loss 0.4034, train acc 0.861, test acc 0.701, time 64.5 sec
epoch 22, loss 0.3893, train acc 0.868, test acc 0.703, time 64.4 sec
epoch 23, loss 0.3833, train acc 0.871, test acc 0.706, time 67.2 sec
epoch 24, loss 0.3701, train acc 0.876, test acc 0.701, time 66.4 sec
epoch 25, loss 0.3732, train acc 0.872, test acc 0.698, time 65.4 sec
epoch 26, loss 0.3426, train acc 0.884, test acc 0.704, time 65.2 sec
epoch 27, loss 0.3457, train acc 0.884, test acc 0.702, time 65.2 sec
epoch 28, loss 0.3378, train acc 0.887, test acc 0.704, time 63.7 sec
epoch 29, loss 0.3206, train acc 0.893, test acc 0.706, time 63.5 sec
epoch 30, loss 0.3172, train acc 0.895, test acc 0.702, time 63.4 sec
epoch 31, loss 0.3092, train acc 0.895, test acc 0.700, time 64.1 sec
epoch 32, loss 0.3032, train acc 0.898, test acc 0.702, time 64.1 sec
epoch 33, loss 0.3039, train acc 0.897, test acc 0.691, time 64.9 sec
epoch 34, loss 0.3003, train acc 0.901, test acc 0.700, time 65.1 sec
epoch 35, loss 0.2957, train acc 0.903, test acc 0.702, time 64.6 sec
epoch 36, loss 0.2913, train acc 0.904, test acc 0.697, time 63.8 sec
epoch 37, loss 0.2784, train acc 0.909, test acc 0.703, time 63.5 sec
epoch 38, loss 0.2751, train acc 0.910, test acc 0.703, time 63.4 sec
epoch 39, loss 0.2674, train acc 0.913, test acc 0.699, time 63.5 sec
epoch 40, loss 0.2620, train acc 0.915, test acc 0.703, time 63.4 sec ↩︎batch size : 32,模型大小1/8
train1:梯度消失
train2:

epoch 1, loss 1.8837, train acc 0.292, test acc 0.415, time 40.7 sec
epoch 2, loss 1.5228, train acc 0.448, test acc 0.510, time 40.0 sec
epoch 3, loss 1.3549, train acc 0.514, test acc 0.566, time 39.9 sec
epoch 4, loss 1.2319, train acc 0.561, test acc 0.572, time 40.0 sec
epoch 5, loss 1.1395, train acc 0.596, test acc 0.621, time 40.0 sec
epoch 6, loss 1.0590, train acc 0.626, test acc 0.643, time 40.0 sec
epoch 7, loss 1.0031, train acc 0.647, test acc 0.654, time 39.9 sec
epoch 8, loss 0.9479, train acc 0.666, test acc 0.649, time 40.0 sec
epoch 9, loss 0.8981, train acc 0.684, test acc 0.670, time 40.0 sec
epoch 10, loss 0.8641, train acc 0.695, test acc 0.672, time 40.0 sec
epoch 11, loss 0.8309, train acc 0.707, test acc 0.682, time 40.0 sec
epoch 12, loss 0.7916, train acc 0.722, test acc 0.677, time 39.9 sec
epoch 13, loss 0.7635, train acc 0.732, test acc 0.683, time 40.0 sec
epoch 14, loss 0.7435, train acc 0.739, test acc 0.695, time 40.0 sec
epoch 15, loss 0.7093, train acc 0.752, test acc 0.685, time 40.0 sec
epoch 16, loss 0.6877, train acc 0.757, test acc 0.693, time 40.0 sec
epoch 17, loss 0.6642, train acc 0.767, test acc 0.702, time 40.0 sec
epoch 18, loss 0.6494, train acc 0.773, test acc 0.690, time 40.0 sec
epoch 19, loss 0.6234, train acc 0.782, test acc 0.686, time 40.0 sec
epoch 20, loss 0.6063, train acc 0.788, test acc 0.700, time 40.0 sec
epoch 21, loss 0.5931, train acc 0.792, test acc 0.691, time 39.9 sec
epoch 22, loss 0.5681, train acc 0.802, test acc 0.684, time 40.0 sec
epoch 23, loss 0.5670, train acc 0.800, test acc 0.698, time 40.0 sec
epoch 24, loss 0.5504, train acc 0.808, test acc 0.691, time 40.0 sec
epoch 25, loss 0.5258, train acc 0.818, test acc 0.703, time 40.0 sec
epoch 26, loss 0.5213, train acc 0.819, test acc 0.692, time 40.0 sec
epoch 27, loss 0.5106, train acc 0.823, test acc 0.698, time 40.0 sec
epoch 28, loss 0.4997, train acc 0.827, test acc 0.696, time 40.0 sec
epoch 29, loss 0.4905, train acc 0.828, test acc 0.695, time 40.0 sec
epoch 30, loss 0.4738, train acc 0.835, test acc 0.699, time 40.0 sec
epoch 31, loss 0.4750, train acc 0.838, test acc 0.697, time 40.0 sec
epoch 32, loss 0.4640, train acc 0.840, test acc 0.702, time 40.0 sec
epoch 33, loss 0.4556, train acc 0.842, test acc 0.701, time 40.1 sec
epoch 34, loss 0.4423, train acc 0.848, test acc 0.699, time 40.0 sec
epoch 35, loss 0.4395, train acc 0.849, test acc 0.699, time 40.0 sec
epoch 36, loss 0.4313, train acc 0.852, test acc 0.702, time 39.9 sec
epoch 37, loss 0.4144, train acc 0.858, test acc 0.695, time 40.1 sec
epoch 38, loss 0.4172, train acc 0.857, test acc 0.695, time 40.1 sec
epoch 39, loss 0.4025, train acc 0.862, test acc 0.706, time 40.0 sec
epoch 40, loss 0.4126, train acc 0.858, test acc 0.692, time 40.0 sec ↩︎batch size : 64,模型大小1/2
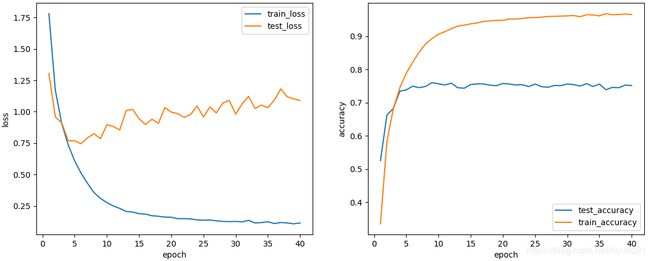
数据:
training on cuda
epoch 1, loss 1.7808, train acc 0.335, test acc 0.525, time 100.1 sec
epoch 2, loss 1.1704, train acc 0.583, test acc 0.663, time 99.4 sec
epoch 3, loss 0.9040, train acc 0.682, test acc 0.683, time 99.4 sec
epoch 4, loss 0.7361, train acc 0.744, test acc 0.734, time 99.3 sec
epoch 5, loss 0.6085, train acc 0.788, test acc 0.738, time 99.2 sec
epoch 6, loss 0.5105, train acc 0.822, test acc 0.749, time 99.3 sec
epoch 7, loss 0.4298, train acc 0.852, test acc 0.745, time 99.3 sec
epoch 8, loss 0.3569, train acc 0.877, test acc 0.749, time 99.2 sec
epoch 9, loss 0.3107, train acc 0.893, test acc 0.760, time 99.3 sec
epoch 10, loss 0.2765, train acc 0.906, test acc 0.757, time 99.2 sec
epoch 11, loss 0.2504, train acc 0.913, test acc 0.753, time 99.2 sec
epoch 12, loss 0.2305, train acc 0.922, test acc 0.758, time 99.5 sec
epoch 13, loss 0.2066, train acc 0.930, test acc 0.745, time 99.2 sec
epoch 14, loss 0.2012, train acc 0.933, test acc 0.743, time 99.2 sec
epoch 15, loss 0.1887, train acc 0.937, test acc 0.754, time 99.1 sec
epoch 16, loss 0.1849, train acc 0.940, test acc 0.756, time 99.2 sec
epoch 17, loss 0.1721, train acc 0.944, test acc 0.756, time 99.2 sec
epoch 18, loss 0.1679, train acc 0.946, test acc 0.752, time 99.2 sec
epoch 19, loss 0.1615, train acc 0.948, test acc 0.751, time 99.1 sec
epoch 20, loss 0.1601, train acc 0.947, test acc 0.758, time 99.2 sec
epoch 21, loss 0.1488, train acc 0.952, test acc 0.756, time 99.2 sec
epoch 22, loss 0.1491, train acc 0.952, test acc 0.753, time 99.2 sec
epoch 23, loss 0.1468, train acc 0.953, test acc 0.754, time 99.1 sec
epoch 24, loss 0.1391, train acc 0.955, test acc 0.748, time 99.2 sec
epoch 25, loss 0.1364, train acc 0.956, test acc 0.756, time 99.2 sec
epoch 26, loss 0.1385, train acc 0.957, test acc 0.748, time 99.2 sec
epoch 27, loss 0.1320, train acc 0.959, test acc 0.746, time 99.2 sec
epoch 28, loss 0.1267, train acc 0.960, test acc 0.752, time 99.2 sec
epoch 29, loss 0.1255, train acc 0.960, test acc 0.751, time 99.2 sec
epoch 30, loss 0.1270, train acc 0.961, test acc 0.756, time 99.2 sec
epoch 31, loss 0.1234, train acc 0.962, test acc 0.754, time 99.2 sec
epoch 32, loss 0.1352, train acc 0.958, test acc 0.750, time 99.2 sec
epoch 33, loss 0.1146, train acc 0.964, test acc 0.757, time 99.1 sec
epoch 34, loss 0.1179, train acc 0.964, test acc 0.749, time 99.2 sec
epoch 35, loss 0.1242, train acc 0.961, test acc 0.756, time 99.1 sec
epoch 36, loss 0.1101, train acc 0.968, test acc 0.739, time 99.1 sec
epoch 37, loss 0.1183, train acc 0.964, test acc 0.746, time 99.1 sec
epoch 38, loss 0.1150, train acc 0.965, test acc 0.745, time 99.1 sec
epoch 39, loss 0.1079, train acc 0.966, test acc 0.753, time 99.1 sec
epoch 40, loss 0.1144, train acc 0.965, test acc 0.751, time 99.1 sec
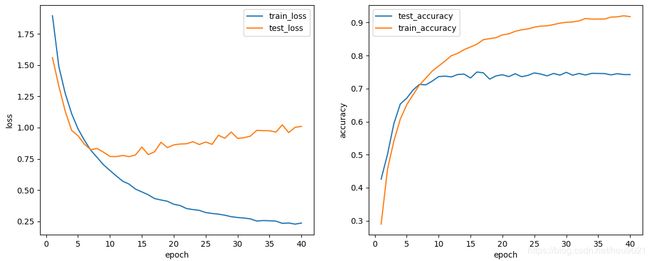
参数没初始化好也会出现梯度消失。 ↩︎batch size : 64,模型大小1/4
(1)此时只有第一个epoch会将初始参数优化一次,之后所有weight和bias都没有发生变化。梯度消失了
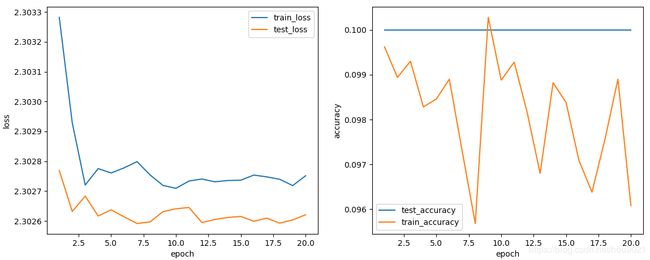
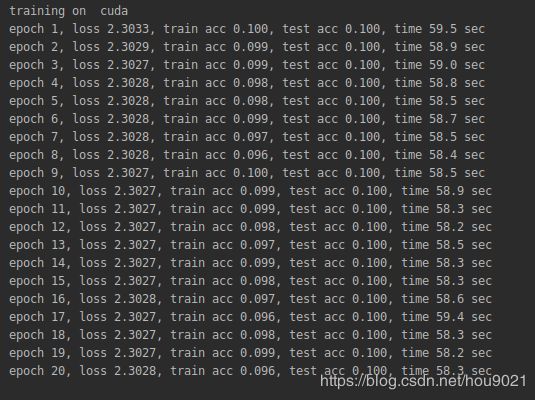
(2)对此网络进行训练时几乎每次梯度都会消失,只有一次成功收敛,可能是因为此大小、batch size的网络对初始化的参数要求较高,否则就不收敛,数据如下:
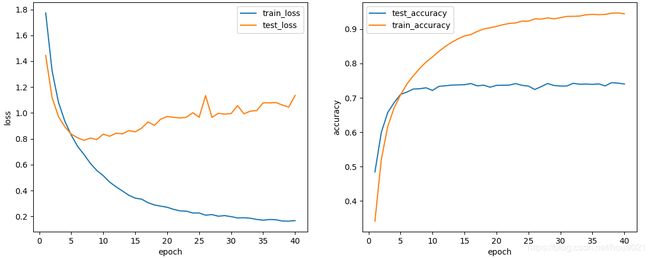
数据:
training on cuda
epoch 1, loss 1.7732, train acc 0.341, test acc 0.485, time 60.2 sec
epoch 2, loss 1.3249, train acc 0.521, test acc 0.600, time 59.5 sec
epoch 3, loss 1.0823, train acc 0.616, test acc 0.657, time 58.6 sec
epoch 4, loss 0.9351, train acc 0.671, test acc 0.686, time 58.3 sec
epoch 5, loss 0.8284, train acc 0.708, test acc 0.710, time 58.2 sec
epoch 6, loss 0.7410, train acc 0.740, test acc 0.717, time 58.2 sec
epoch 7, loss 0.6779, train acc 0.764, test acc 0.726, time 58.2 sec
epoch 8, loss 0.6092, train acc 0.785, test acc 0.726, time 58.3 sec
epoch 9, loss 0.5544, train acc 0.804, test acc 0.729, time 58.4 sec
epoch 10, loss 0.5150, train acc 0.819, test acc 0.721, time 58.3 sec
epoch 11, loss 0.4654, train acc 0.835, test acc 0.733, time 58.4 sec
epoch 12, loss 0.4288, train acc 0.849, test acc 0.735, time 58.3 sec
epoch 13, loss 0.3967, train acc 0.861, test acc 0.737, time 58.3 sec
epoch 14, loss 0.3635, train acc 0.872, test acc 0.738, time 58.3 sec
epoch 15, loss 0.3412, train acc 0.880, test acc 0.738, time 58.3 sec
epoch 16, loss 0.3333, train acc 0.884, test acc 0.742, time 58.3 sec
epoch 17, loss 0.3061, train acc 0.893, test acc 0.735, time 58.5 sec
epoch 18, loss 0.2887, train acc 0.900, test acc 0.737, time 59.2 sec
epoch 19, loss 0.2791, train acc 0.904, test acc 0.731, time 58.3 sec
epoch 20, loss 0.2706, train acc 0.908, test acc 0.736, time 58.4 sec
epoch 21, loss 0.2544, train acc 0.913, test acc 0.737, time 58.3 sec
epoch 22, loss 0.2430, train acc 0.916, test acc 0.737, time 58.3 sec
epoch 23, loss 0.2407, train acc 0.918, test acc 0.741, time 58.3 sec
epoch 24, loss 0.2263, train acc 0.923, test acc 0.736, time 58.3 sec
epoch 25, loss 0.2263, train acc 0.923, test acc 0.734, time 58.3 sec
epoch 26, loss 0.2095, train acc 0.930, test acc 0.724, time 58.7 sec
epoch 27, loss 0.2142, train acc 0.929, test acc 0.733, time 59.0 sec
epoch 28, loss 0.2016, train acc 0.932, test acc 0.742, time 58.5 sec
epoch 29, loss 0.2062, train acc 0.930, test acc 0.736, time 58.6 sec
epoch 30, loss 0.1980, train acc 0.933, test acc 0.734, time 59.4 sec
epoch 31, loss 0.1884, train acc 0.937, test acc 0.734, time 59.6 sec
epoch 32, loss 0.1898, train acc 0.937, test acc 0.742, time 59.6 sec
epoch 33, loss 0.1858, train acc 0.938, test acc 0.740, time 58.6 sec
epoch 34, loss 0.1767, train acc 0.941, test acc 0.740, time 58.5 sec
epoch 35, loss 0.1710, train acc 0.943, test acc 0.739, time 58.5 sec
epoch 36, loss 0.1761, train acc 0.942, test acc 0.741, time 58.5 sec
epoch 37, loss 0.1742, train acc 0.943, test acc 0.735, time 58.4 sec
epoch 38, loss 0.1644, train acc 0.946, test acc 0.744, time 58.4 sec
epoch 39, loss 0.1633, train acc 0.947, test acc 0.743, time 58.4 sec
epoch 40, loss 0.1674, train acc 0.944, test acc 0.740, time 58.4 sec ↩︎batch size : 64,模型大小1/8
对于相同的batch size来说缩小了模型,达到最高精度所需的epoch就会增加
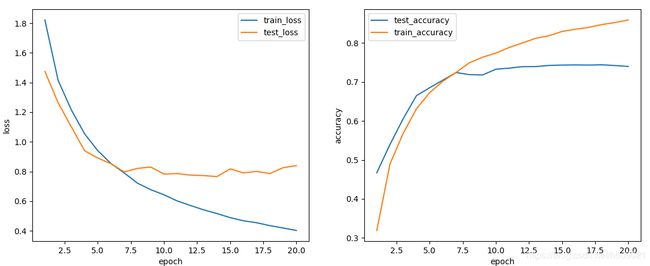
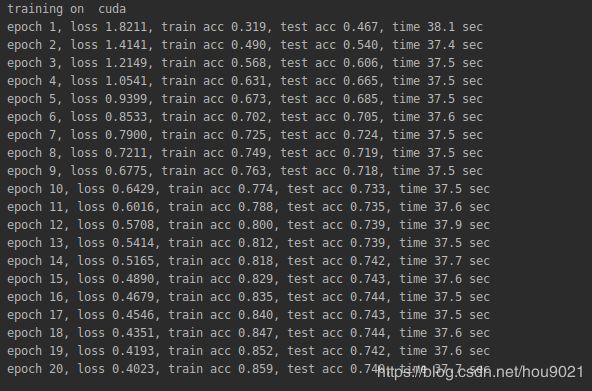
(2)不收敛

 ↩︎
↩︎batch size : 128,模型大小1/4
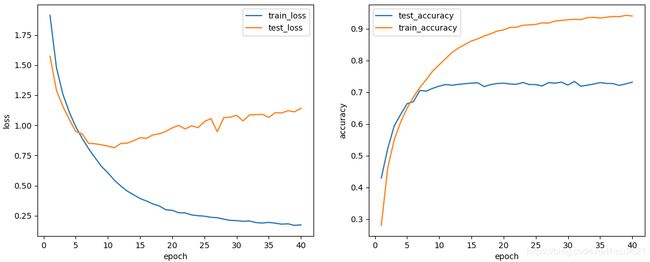
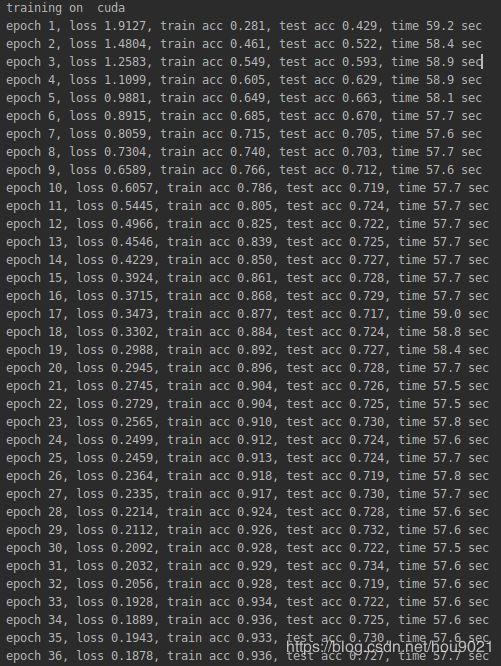 ↩︎
↩︎batch size : 128,模型大小1/8
 ↩︎
↩︎