Redis 集群之Redis+Codis方案
【转载请注明出处】:https://blog.csdn.net/huahao1989/article/details/106485654
Redis 集群解决方案有哪些
Redis 的集群解决方案有社区的,也有官方的,社区的解决方案有 Codis 和Twemproxy,Codis是由我国的豌豆荚团队开源的,Twemproxy是Twitter团队的开源的;官方的集群解决方案就是 Redis Cluster,这是由 Redis 官方团队来实现的。下面的列表可以很明显地表达出三者的不同点。
| Codis | Twemproxy | Redis Cluster | |
|---|---|---|---|
| resharding without restarting cluster | Yes | No | Yes |
| pipeline | Yes | Yes | No |
| hash tags for multi-key operations | Yes | Yes | Yes |
| multi-key operations while resharding | Yes | - | No(details) |
| Redis clients supporting | Any clients | Any clients | Clients have to support cluster protocol |
codis和twemproxy最大的区别有两个:
- codis支持动态水平扩展,对client完全透明不影响服务的情况下可以完成增减redis实例的操作;
- codis是用go语言写的并支持多线程,twemproxy用C并只用单线程。 后者又意味着:codis在多核机器上的性能会好于twemproxy;codis的最坏响应时间可能会因为GC的STW而变大,不过go1.5发布后会显著降低STW的时间;如果只用一个CPU的话go语言的性能不如C,因此在一些短连接而非长连接的场景中,整个系统的瓶颈可能变成accept新tcp连接的速度,这时codis的性能可能会差于twemproxy。
codis和redis cluster的区别:
- redis cluster基于smart client和无中心的设计,client必须按key的哈希将请求直接发送到对应的节点。这意味着:使用官方cluster必须要等对应语言的redis driver对cluster支持的开发和不断成熟;client不能直接像单机一样使用pipeline来提高效率,想同时执行多个请求来提速必须在client端自行实现异步逻辑。 而codis因其有中心节点、基于proxy的设计,对client来说可以像对单机redis一样去操作proxy(除了一些命令不支持),还可以继续使用pipeline并且如果后台redis有多个的话速度会显著快于单redis的pipeline。
- codis使用zookeeper来作为辅助,这意味着单纯对于redis集群来说需要额外的机器搭zk。
Codis介绍
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有显著区别 (不支持的命令列表), 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务。

Codis 3.x 由以下组件组成:
-
Codis Server:基于 redis-3.2.8 分支开发。增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。具体的修改可以参考文档 redis 的修改。
-
Codis Proxy:客户端连接的 Redis 代理服务, 实现了 Redis 协议。 除部分命令不支持以外(不支持的命令列表),表现的和原生的 Redis 没有区别(就像 Twemproxy)。
- 对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例;
- 不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
-
Codis Dashboard:集群管理工具,支持 codis-proxy、codis-server 的添加、删除,以及据迁移等操作。在集群状态发生改变时,codis-dashboard 维护集群下所有 codis-proxy 的状态的一致性。
- 对于同一个业务集群而言,同一个时刻 codis-dashboard 只能有 0个或者1个;
- 所有对集群的修改都必须通过 codis-dashboard 完成。
-
Codis Admin:集群管理的命令行工具。
- 可用于控制 codis-proxy、codis-dashboard 状态以及访问外部存储。
-
Codis FE:集群管理界面。
- 多个集群实例共享可以共享同一个前端展示页面;
- 通过配置文件管理后端 codis-dashboard 列表,配置文件可自动更新。
-
Storage:为集群状态提供外部存储。
- 提供 Namespace 概念,不同集群的会按照不同 product name 进行组织;
- 目前仅提供了 Zookeeper、Etcd、Fs 三种实现,但是提供了抽象的 interface 可自行扩展。
Codis 分片原理
在Codis中,Codis会把所有的key分成1024个槽,这1024个槽对应着的就是Redis的集群,这个在Codis中是会在内存中维护着这1024个槽与Redis实例的映射关系。这个槽是可以配置,可以设置成 2048 或者是4096个。看你的Redis的节点数量有多少,偏多的话,可以设置槽多一些。
Codis中key的分配算法,先是把key进行CRC32 后,得到一个32位的数字,然后再hash%1024后得到一个余数,这个值就是这个key对应着的槽,这槽后面对应着的就是redis的实例。
CRC32:CRC本身是“冗余校验码”的意思,CRC32则表示会产生一个32bit(8位十六进制数)的校验值。由于CRC32产生校验值时源数据块的每一个bit(位)都参与了计算,所以数据块中即使只有一位发生了变化,也会得到不同的CRC32值。
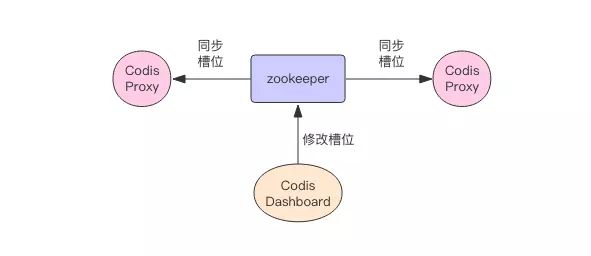
Codis之间的槽位同步
Codis把槽位信息同步的工作交给了ZooKeeper来管理,当Codis的Codis Dashbord 改变槽位的信息的时候,其他的Codis节点会监听到ZooKeeper的槽位变化,会及时同步过来。如图:
Codis中的扩容
因为Codis是一个代理中间件,所以这个当需要扩容Redis实例的时候,可以直接增加redis节点。在槽位分配的时候,可以手动指定Codis Dashbord来为新增的节点来分配特定的槽位。
在Codis中实现了自定义的扫描指令SLOTSSCAN,可以扫描指定的slot下的所有的key,将这些key迁移到新的Redis的节点中(话外语:这个是Codis定制化的其中一个好处)。
首先,在迁移的时候,会在原来的Redis节点和新的Redis里都保存着迁移的槽位信息,在迁移的过程中,如果有key打进将要迁移或者正在迁移的旧槽位的时候,这个时候Codis的处理机制是,先是将这个key强制迁移到新的Redis节点中,然后再告诉Codis,下次如果有新的key的打在这个槽位中的话,那么转发到新的节点。
自动均衡策略
面对着上面讲的迁移策略,如果有成千上万个节点新增进来,都需要我们手动去迁移吗?那岂不是得累死啊。当然,Codis也是考虑到了这一点,所以提供了自动均衡策略。自动均衡策略是这样的,Codis 会在机器空闲的时候,观察Redis中的实例对应着的slot数,如果不平衡的话就会自动进行迁移。
Codis安装
依赖环境准备
下面这两个依赖环境的搭建这里不再介绍。
- 安装Zookeeper
- 安装Go
1. 下载Codis安装包
在官方的发布页找到最新的发布版本下载最新版3.2.2,如需要编译安装请参考官方的编译安装说明。
下载安装包之后解压并重命名目录,进入解压目录创建config文件夹用来放置配置文件地址,创建logs文件夹将来放日志文件。
2.安装codis-dashboard(集群管理工具)
在config文件夹中创建配置文件dashboard.toml(这些配置文件模板在源码config目录中可以找到),文件内容:
##################################################
# #
# Codis-Dashboard #
# #
##################################################
# Set Coordinator, only accept "zookeeper" & "etcd" & "filesystem".
# for zookeeper/etcd, coorinator_auth accept "user:password"
# Quick Start
#coordinator_name = "filesystem"
#coordinator_addr = "/tmp/codis"
coordinator_name = "zookeeper"
coordinator_addr = "zk1:2181,zk2:2182,zk3:2183"
coordinator_auth = ""
# Set Codis Product Name/Auth.
product_name = "codis-demo"
product_auth = ""
# Set bind address for admin(rpc), tcp only.
admin_addr = "0.0.0.0:18080"
# Set arguments for data migration (only accept 'sync' & 'semi-async').
migration_method = "semi-async"
migration_parallel_slots = 100
migration_async_maxbulks = 200
migration_async_maxbytes = "32mb"
migration_async_numkeys = 500
migration_timeout = "30s"
# Set configs for redis sentinel.
sentinel_client_timeout = "10s"
sentinel_quorum = 2
sentinel_parallel_syncs = 1
sentinel_down_after = "30s"
sentinel_failover_timeout = "5m"
sentinel_notification_script = ""
sentinel_client_reconfig_script = ""
为了方便管理创建启动脚本start-dashboard.sh,脚本内容:
#!/bin/sh
#set -x
nohup ./codis-dashboard --ncpu=4 --config=./config/dashboard.toml --log=./logs/dashboard.log --log-level=WARN &>/dev/null &
执行启动脚本启动dashboard,然后浏览器访问18080端口已经可以返回当前集群信息。
启动参数说明:
$ ./codis-dashboard -h
Usage:
codis-dashboard [--ncpu=N] [--config=CONF] [--log=FILE] [--log-level=LEVEL] [--host-admin=ADDR]
codis-dashboard --default-config
codis-dashboard --version
Options:
--ncpu=N 最大使用 CPU 个数
-c CONF, --config=CONF 指定启动配置文件
-l FILE, --log=FILE 设置 log 输出文件
--log-level=LEVEL 设置 log 输出等级:INFO,WARN,DEBUG,ERROR;默认INFO,推荐WARN
默认配置文件:
$ ./codis-dashboard --default-config | tee dashboard.toml
##################################################
# #
# Codis-Dashboard #
# #
##################################################
# Set Coordinator, only accept "zookeeper" & "etcd"
coordinator_name = "zookeeper"
coordinator_addr = "127.0.0.1:2181"
# Set Codis Product {Name/Auth}.
product_name = "codis-demo"
product_auth = ""
# Set bind address for admin(rpc), tcp only.
admin_addr = "0.0.0.0:18080"
| 参数 | 说明 |
|---|---|
| coordinator_name | 外部存储类型,接受 zookeeper/etcd |
| coordinator_addr | 外部存储地址 |
| product_name | 集群名称,满足正则 \w[\w.-]* |
| product_auth | 集群密码,默认为空 |
| admin_addr | RESTful API 端口 |
3.安装codis-proxy(客户端连接的 Redis 代理服务)
在config文件夹中创建配置文件proxy.toml,文件内容:
##################################################
# #
# Codis-Proxy #
# #
##################################################
# Set Codis Product Name/Auth.
product_name = "codis-demo"
product_auth = ""
# Set auth for client session
# 1. product_auth is used for auth validation among codis-dashboard,
# codis-proxy and codis-server.
# 2. session_auth is different from product_auth, it requires clients
# to issue AUTH before processing any other commands.
session_auth = ""
# Set bind address for admin(rpc), tcp only.
admin_addr = "0.0.0.0:11080"
# Set bind address for proxy, proto_type can be "tcp", "tcp4", "tcp6", "unix" or "unixpacket".
proto_type = "tcp4"
proxy_addr = "0.0.0.0:19000"
# Set jodis address & session timeout
# 1. jodis_name is short for jodis_coordinator_name, only accept "zookeeper" & "etcd".
# 2. jodis_addr is short for jodis_coordinator_addr
# 3. jodis_auth is short for jodis_coordinator_auth, for zookeeper/etcd, "user:password" is accepted.
# 4. proxy will be registered as node:
# if jodis_compatible = true (not suggested):
# /zk/codis/db_{PRODUCT_NAME}/proxy-{HASHID} (compatible with Codis2.0)
# or else
# /jodis/{PRODUCT_NAME}/proxy-{HASHID}
jodis_name = "zookeeper"
jodis_addr = "zk1:2181,zk2:2182,zk3:2183"
jodis_auth = ""
jodis_timeout = "20s"
jodis_compatible = false
# Set datacenter of proxy.
proxy_datacenter = ""
# Set max number of alive sessions.
proxy_max_clients = 1000
# Set max offheap memory size. (0 to disable)
proxy_max_offheap_size = "1024mb"
# Set heap placeholder to reduce GC frequency.
proxy_heap_placeholder = "256mb"
# Proxy will ping backend redis (and clear 'MASTERDOWN' state) in a predefined interval. (0 to disable)
backend_ping_period = "5s"
# Set backend recv buffer size & timeout.
backend_recv_bufsize = "128kb"
backend_recv_timeout = "30s"
# Set backend send buffer & timeout.
backend_send_bufsize = "128kb"
backend_send_timeout = "30s"
# Set backend pipeline buffer size.
backend_max_pipeline = 20480
# Set backend never read replica groups, default is false
backend_primary_only = false
# Set backend parallel connections per server
backend_primary_parallel = 1
backend_replica_parallel = 1
# Set backend tcp keepalive period. (0 to disable)
backend_keepalive_period = "75s"
# Set number of databases of backend.
backend_number_databases = 16
# If there is no request from client for a long time, the connection will be closed. (0 to disable)
# Set session recv buffer size & timeout.
session_recv_bufsize = "128kb"
session_recv_timeout = "30m"
# Set session send buffer size & timeout.
session_send_bufsize = "64kb"
session_send_timeout = "30s"
# Make sure this is higher than the max number of requests for each pipeline request, or your client may be blocked.
# Set session pipeline buffer size.
session_max_pipeline = 10000
# Set session tcp keepalive period. (0 to disable)
session_keepalive_period = "75s"
# Set session to be sensitive to failures. Default is false, instead of closing socket, proxy will send an error response to client.
session_break_on_failure = false
# Set metrics server (such as http://localhost:28000), proxy will report json formatted metrics to specified server in a predefined period.
metrics_report_server = ""
metrics_report_period = "1s"
# Set influxdb server (such as http://localhost:8086), proxy will report metrics to influxdb.
metrics_report_influxdb_server = ""
metrics_report_influxdb_period = "1s"
metrics_report_influxdb_username = ""
metrics_report_influxdb_password = ""
metrics_report_influxdb_database = ""
# Set statsd server (such as localhost:8125), proxy will report metrics to statsd.
metrics_report_statsd_server = ""
metrics_report_statsd_period = "1s"
metrics_report_statsd_prefix = ""
编写启动脚本start-proxy.sh,文件内容:
#!/bin/sh
#set -x
nohup ./codis-proxy --ncpu=4 --config=./config/proxy.toml --log=./logs/proxy.log --log-level=WARN &>/dev/null &
执行启动脚本,然后访问11080端口可以查看代理信息。
codis-proxy 启动后,处于 waiting 状态,监听 proxy_addr 地址,但是不会 accept 连接,添加到集群并完成集群状态的同步,才能改变状态为 online。添加的方法有以下两种:
- 通过 codis-fe 添加:通过 Add Proxy 按钮,将 admin_addr 加入到集群中;
- 通过 codis-admin 命令行工具添加,方法如下:
$ ./codis-admin --dashboard=127.0.0.1:18080 --create-proxy -x 127.0.0.1:11080
其中 127.0.0.1:18080 以及 127.0.0.1:11080 分别为 dashboard 和 proxy 的admin_addr地址;
添加过程中,dashboard 会完成如下一系列动作:
- 获取 proxy 信息,对集群 name 以及 auth 进行验证,并将其信息写入到外部存储中;
- 同步 slots 状态;
- 标记 proxy 状态为 online,此后 proxy 开始 accept 连接并开始提供服务;
启动参数说明:
$ ./codis-proxy -h
Usage:
codis-proxy [--ncpu=N] [--config=CONF] [--log=FILE] [--log-level=LEVEL] [--host-admin=ADDR] [--host-proxy=ADDR] [--ulimit=NLIMIT]
codis-proxy --default-config
codis-proxy --version
Options:
--ncpu=N 最大使用 CPU 个数
-c CONF, --config=CONF 指定启动配置文件
-l FILE, --log=FILE 设置 log 输出文件
--log-level=LEVEL 设置 log 输出等级:INFO,WARN,DEBUG,ERROR;默认INFO,推荐WARN
--ulimit=NLIMIT 检查 ulimit -n 的结果,确保运行时最大文件描述不少于 NLIMIT
默认配置文件:
$ ./codis-proxy --default-config | tee proxy.toml
##################################################
# #
# Codis-Proxy #
# #
##################################################
# Set Codis Product {Name/Auth}.
product_name = "codis-demo"
product_auth = ""
# Set bind address for admin(rpc), tcp only.
admin_addr = "0.0.0.0:11080"
# Set bind address for proxy, proto_type can be "tcp", "tcp4", "tcp6", "unix" or "unixpacket".
proto_type = "tcp4"
proxy_addr = "0.0.0.0:19000"
# Set jodis address & session timeout.
jodis_addr = ""
jodis_timeout = 10
jodis_compatible = false
# Proxy will ping-pong backend redis periodly to keep-alive
backend_ping_period = 5
# If there is no request from client for a long time, the connection will be droped. Set 0 to disable.
session_max_timeout = 1800
# Buffer size for each client connection.
session_max_bufsize = 131072
# Number of buffered requests for each client connection.
# Make sure this is higher than the max number of requests for each pipeline request, or your client may be blocked.
session_max_pipeline = 1024
# Set period between keep alives. Set 0 to disable.
session_keepalive_period = 60
| 参数 | 说明 |
|---|---|
| product_name | 集群名称,参考 dashboard 参数说明 |
| product_auth | 集群密码,默认为空 |
| admin_addr | RESTful API 端口 |
| proto_type | Redis 端口类型,接受 tcp/tcp4/tcp6/unix/unixpacket |
| proxy_addr | Redis 端口地址或者路径 |
| jodis_addr | Jodis 注册 zookeeper 地址 |
| jodis_timeout | Jodis 注册 session timeout 时间,单位 second |
| jodis_compatible | Jodis 注册 zookeeper 的路径 |
| backend_ping_period | 与 codis-server 探活周期,单位 second,0 表示禁止 |
| session_max_timeout | 与 client 连接最大读超时,单位 second,0 表示禁止 |
| session_max_bufsize | 与 client 连接读写缓冲区大小,单位 byte |
| session_max_pipeline | 与 client 连接最大的 pipeline 大小 |
| session_keepalive_period | 与 client 的 tcp keepalive 周期,仅 tcp 有效,0 表示禁止 |
注:Codis3 会将 jodis 节点注册在 /jodis/{PRODUCT_NAME} 下,这点与 Codis2 不太兼容,所以为了兼容性,可以考虑将 jodis_compatible 设置成 true。
4.安装codis-server(优化版的Redis)
codis-server的配置文件和redis一样,其本身就是在redis上改进而来。
创建配置文件config/codis-server/7001/redis.conf,文件内容:
bind 127.0.0.1
port 7001
daemonize no
pidfile /var/run/codis_7001.pid
logfile "./logs/codis-server/7001/redis.log"
save 900 1
save 300 10
save 60 10000
dir ./config/codis-server/7001
appendonly yes
appendfsync always
创建启动脚本start-server-7001.sh,脚本内容:
#!/bin/sh
#set -x
nohup ./codis-server ./config/codis-server/7001/redis.conf &>/dev/null &
同样的方法可以配置多个codis-server。
启动完成后,可以通过 codis-fe 提供的界面或者 codis-admin 命令行工具添加到集群中。
5.启动codis-fe(集群管理界面)
这是个可选组件,也可以通过codis-admin命令行工具来管理集群。
编写启动脚本start-fe.sh,脚本内容:
#!/bin/sh
#set -x
nohup ./codis-fe --ncpu=1 --log=./logs/fe.log --log-level=WARN --zookeeper=zk1:2181,zk2:2182,zk3:2183 --listen=0.0.0.0:8090 &>/dev/null &
执行启动脚本,然后访问8090端口即可看到集群管理界面。
启动参数说明:
$ ./codis-fe -h
Usage:
codis-fe [--ncpu=N] [--log=FILE] [--log-level=LEVEL] [--assets-dir=PATH] (--dashboard-list=FILE|--zookeeper=ADDR|--etcd=ADDR|--filesystem=ROOT) --listen=ADDR
codis-fe --version
Options:
--ncpu=N 最大使用 CPU 个数
-d LIST, --dashboard-list=LIST 配置文件,能够自动刷新
-l FILE, --log=FILE 设置 log 输出文件
--log-level=LEVEL 设置 log 输出等级:INFO,WARN,DEBUG,ERROR;默认INFO,推荐WARN
--listen=ADDR HTTP 服务端口
配置文件 codis.json 可以手动编辑,也可以通过 codis-admin 从外部存储中拉取,例如:
$ ./codis-admin --dashboard-list --zookeeper=127.0.0.1:2181 | tee codis.json
[
{
"name": "codis-demo",
"dashboard": "127.0.0.1:18080"
},
{
"name": "codis-demo2",
"dashboard": "127.0.0.1:28080"
}
]
6.使用codis-admin(集群管理的命令行工具)
执行./codis-admin -h可以查看可执行的命令及参数。
-
dashboard服务和proxy服务的停用
./codis-admin --proxy=127.0.0.1:11080 --shutdown ./codis-admin --dashboard=127.0.0.1:18080 --shutdown -
codis-dashboard 异常退出的修复
当 codis-dashboard 启动时,会在外部存储上存放一条数据,用于存储 dashboard 信息,同时作为 LOCK 存在。当 codis-dashboard 安全退出时,会主动删除该数据。当 codis-dashboard 异常退出时,由于之前 LOCK 未安全删除,重启往往会失败。因此 codis-admin 提供了强制删除工具:- 确认 codis-dashboard 进程已经退出(很重要);
- 运行 codis-admin 删除 LOCK:
./codis-admin --remove-lock --product=codis-demo --zookeeper=zk1:2181,zk2:2182,zk3:2183 -
codis-proxy 异常退出的修复
通常 codis-proxy 都是通过 codis-dashboard 进行移除,移除过程中 codis-dashboard 为了安全会向 codis-proxy 发送offline指令,成功后才会将 proxy 信息从外部存储中移除。如果 codis-proxy 异常退出,该操作会失败。此时可以使用 codis-admin 工具进行移除:- 确认 codis-proxy 进程已经退出(很重要);
- 运行 codis-admin 删除 proxy:
$ ./codis-admin --dashboard=127.0.0.1:18080 --remove-proxy --addr=127.0.0.1:11080 --force选项
--force表示,无论offline操作是否成功,都从外部存储中将该节点删除。所以操作前,一定要确认该 codis-proxy 进程已经退出。
7.配置codis-ha
创建启动脚本start-ha.sh,脚本内容:
#!/bin/sh
#set -x
nohup ./codis-ha --log=./logs/ha.log --log-level=WARN --dashboard=127.0.0.1:18080 &>/dev/null &
因为 codis-proxy 是无状态的,可以比较容易的搭多个实例,达到高可用性和横向扩展。
对 Java 用户来说,可以使用基于 Jedis 的实现 Jodis ,来实现 proxy 层的 HA:
- 它会通过监控 zookeeper 上的注册信息来实时获得当前可用的 proxy 列表,既可以保证高可用性;
- 也可以通过轮流请求所有的proxy实现负载均衡。
如果需要异步请求,可以使用基于Netty开发的 Nedis。
对下层的 redis 实例来说,当一个 group 的 master 挂掉的时候,应该让管理员清楚,并手动的操作,因为这涉及到了数据一致性等问题(redis的主从同步是最终一致性的)。因此 codis 不会自动的将某个 slave 升级成 master。
关于外部 codis-ha 工具,这是一个通过 codis-dashboard 开放的 RESTful API 实现自动切换主从的工具。该工具会在检测到 master 挂掉的时候主动应用主从切换策略,提升单个 slave 成为新的 master。
需要注意,codis 将其中一个 slave 升级为 master 时,该组内其他 slave 实例是不会自动改变状态的,这些 slave 仍将试图从旧的 master 上同步数据,因而会导致组内新的 master 和其他 slave 之间的数据不一致。因此当出现主从切换时,需要管理员手动创建新的 sync action 来完成新 master 与 slave 之间的数据同步(codis-ha 不提供自动操作的工具,因为这样太不安全了)。
Codis使用
访问http://IP:8090打开集群管理,左侧的菜单显示了codis集群列表。
添加组和sever

可以看到添加的三个codis-sever中7002是master,7001和7003是slave,这里的主从关系不用在配置文件中来配置主从关系,codis会自己配置主从,可以使用redis客户端做个测试:
$ ./redis-cli -c -p 7002
127.0.0.1:7002> set k1 v1
OK
127.0.0.1:7002> set k2 v2
OK
127.0.0.1:7002> exit
$ ./redis-cli -c -p 7001
127.0.0.1:7001> get k1
"v1"
127.0.0.1:7001> get k2
"v2"
127.0.0.1:7001> set k3 v3
# (error) READONLY You can't write against a read only slave.
127.0.0.1:7001> exit
$ ./redis-cli -c -p 7003
127.0.0.1:7003> get k1
"v1"
127.0.0.1:7003> get k2
"v2"
127.0.0.1:7003> set k3 v3
# (error) READONLY You can't write against a read only slave.
127.0.0.1:7003> exit
可以看到只能在master写入,写入的数据也同步到了slave上。此时去看7003和7001的配置文件发现codis自动在配置文件上加了slaveof 127.0.0.1 7002,假设此时master挂掉了

可以看到codis-ha自动将7003当成master,然后将7001和7002都停止了(进程不在),好危险,因为redis是最终一致性,此时的数据一致性也无法保证,而且将其他节点直接停止,此时的7003压力将非常大。此时再将7001和7002重启,然后再次加入,发现codis会将这两个实例再次停止,原因很简单,因为原来7002是master,7001是7002的slave,配置并没有变,不允许有两个master,而且当前7003是master,因此需要手动更改配置文件才能加入这个组。
假设现在没有codis-ha,master 7003挂掉了会怎么样。

可以看到,并没有将其他节点当成master的操作,此时重启7003就可以恢复当前组的集群状态,也不需要手动更改配置文件和手动加入组。
添加proxy

设置Slots

使用redis客户端连接proxy测试:
$ ./redis-cli -c -p 19000
127.0.0.1:19000> get k1
"v1"
127.0.0.1:19000> set k001 v001
OK
127.0.0.1:19000> get k001
"v001"
127.0.0.1:19000> exit
此时假设master 7003挂了(没用codis-ha)会怎么样?
$ ./redis-cli -c -p 19000
127.0.0.1:19000> get k1
(error) ERR handle response, backend conn reset
127.0.0.1:19000> set k002 v002
(error) ERR handle response, backend conn reset
127.0.0.1:19000> exit
可以看到变成了既不可读也不可写了,这时启动codis-ha继续测试

codis-ha选择了7001作为master,使用redis客户端连接proxy测试:
$ ./redis-cli -c -p 19000
127.0.0.1:19000> get k1
"v1"
127.0.0.1:19000> get k001
"v001"
127.0.0.1:19000> set k0002 v0002
OK
127.0.0.1:19000> get k0002
"v0002"
127.0.0.1:19000> exit
可以看到当前是可以读也可以写的。
【转载请注明出处】:https://blog.csdn.net/huahao1989/article/details/106485654
