文章目录
- 简介
- GPU调度示意图
- 数据结构组织图
- CS管理数据结构
- amdgpu_cs_chunk
- amdgpu_cs_parser
- amdgpu_ib
- GPU调度数据结构
- drm_sched_job
- amdgpu_job
- drm_sched_entity
- drm_sched_rq
- drm_gpu_scheduler
- 流程
- 流程图
- 整体流程
- 保存渲染命令
- 初始化job
- 填充IB
- 初始化entity
- 提交任务
- 内核线程初始化
- 内核线程任务调度
- 执行任务
简介
- 内核态的GPU驱动需要处理用户态驱动下发的渲染命令,对于每个用户态的进程,在提交渲染命令前首先通过mesa驱动创建属于自己的上下文,然后往上下文关联的cmdbuf中填入渲染命令然后下发。渲染命令并不是一条一条下发给内核,而是批量统一放到一个内存chunk中,这个chunk内存空间是用户态已经向内核申请好的,由内核DRM框架管理,因此用户态下发的实际动作就是下发ioctl命令字然后把chunk的指针告诉内核,内核只要获取到这个地址将其放到内核的IB对象中就可以了。
GPU调度示意图

- 每个应用程序下发渲染命令前先创建自己的渲染上下文,然后下发渲染命令,渲染命令到达mesa驱动层后,mesa会对应地找到该命令所属的GPU硬件模块,然后下发ioctl命令将渲染命令提交到对应IP的Ring Buffer上。在上图中,渲染命令在下发到内核之后会被封装成一个job,然后找到其所属的渲染上下文,更具体地,找到该job所属的GPU IP的Ring Buffer,获取该job应该加入的调度实体,然后加入调度实体上的调度队列。一个job代表一个应用程序下发的渲染命令,不同job可能来自不同的应用程序。
数据结构组织图
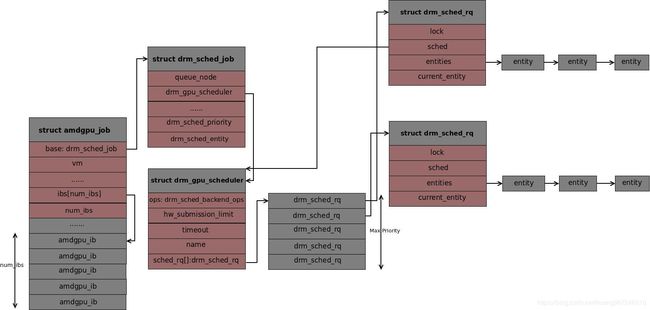
CS管理数据结构
amdgpu_cs_chunk
- 对应用户态的
drm_amdgpu_cs_chunk结构,内核在接收用户态渲染命令后,会将用户态下发的chunk对应保存在内核态的chunk中
struct amdgpu_cs_chunk {
uint32_t chunk_id; /* 1 */
uint32_t length_dw; /* 2 */
void *kdata; /* 3 */
};
1. chunk类型,用户态和内核态共同约定的chunk类型,不同chunk类型chunk组成不同,对应的解析方式不同
2. chunk空间的大小
3. chunk存放的渲染命令
amdgpu_cs_parser
- parser用户存放用户态下发的渲染命令相关的信息,并关联对应的GPU设备,文件设备,渲染命令提交上下文等。当用户态驱动下发命令字时,它的所有信息都放在parser中,之后内核态的所有操作都携带parser对象,从parser中取需要的数据
struct amdgpu_cs_parser {
struct amdgpu_device *adev; /* 1 */
struct drm_file *filp; /* 2 */
struct amdgpu_ctx *ctx; /* 3 */
/* chunks */
unsigned nchunks; /* 4 */
struct amdgpu_cs_chunk *chunks;
/* scheduler job object */
struct amdgpu_job *job; /* 5 */
struct drm_sched_entity *entity; /* 6 */
......
};
1. amdgpu设备在内核drm框架的下的抽象,每个GPU设备关联一个
2. amdgpu字符设备关联的文件抽象,用户态驱动通过打开/dev/dri/card0字符设备下发ioctl命令字,该成员是内核file结构在drm框架下的封
装,drm_file结构是基于struct file实现的,因此它内部会指向一个struct file的成员
3. GPU渲染命令提交上下文,它包含所有GPU硬件IP核的调度实体
4. 具体的渲染命令以chunk的形式存放在amdgpu_cs_chunk对象中,每个chunk可以存放数个渲染命令,任务提交的时候
5. GPU IP核ring buffer上的调度器job,每个渲染命令上下文的提交需要关联一个job,这个job会指向存放渲染命令的内存空间
6. GPU IP核ring buffer上的调度实体,
amdgpu_ib
- IB是内核存放渲染命令的基本单位,应用程序下发的chunk,最终会被内核放到ib中,每个chunk了对应一个ib
struct amdgpu_ib {
struct amdgpu_sa_bo *sa_bo;
uint32_t length_dw; /* 1 */
uint64_t gpu_addr; /* 2 */
......
};
1. ib空间的大小,4字节为单位
2. ib空间的起始地址,这个地址属于GTT,是用户态通过GEM的API申请的GPU虚拟地址,GPU可访问
GPU调度数据结构
drm_sched_job
- 该job是调度实体管理其上job队列的元素,一个调度实体可以通过job queue管理多个job。
struct drm_sched_job {
struct spsc_node queue_node; /* 1 */
struct drm_gpu_scheduler *sched; /* 2 */
enum drm_sched_priority s_priority; /* 3 */
struct drm_sched_entity *entity; /* 4 */
};
1. 用于链入调度实体队列的元素
2. job所在的调度器
3. job优先级,待分析
4. job所在的调度实体
amdgpu_job
- amdgpu_job更接近上层,上层驱动下发的渲染命令被存放在ib中,amdgpu_job就是ib的封装,它的内部有一个调度job,会指向调度实体。
struct amdgpu_job {
struct drm_sched_job base; /* 1 */
struct amdgpu_ib *ibs; /* 2 */
uint32_t num_ibs;
......
};
1. 调度实体的job队列管理的job
2. 渲染命令存放的IB空间起始地址以及IB个数
drm_sched_entity
struct drm_sched_entity {
struct list_head list; /* 1 */
struct drm_sched_rq *rq; /* 2 */
struct drm_gpu_scheduler **sched_list; /* 3 */
enum drm_sched_priority priority; /* 4 */
struct spsc_queue job_queue; /* 5 */
bool stopped; /* 6 */
};
1. 一个运行队列可以管理多个调度实体,该成员用于链入调度队列
2. 调度实体所在的运行队列
3. 调度实体所在的ring buffer上的调度器
4. 调度实体的优先级,每个优先级上都有一个运行队列,管理属于该优先级的调度实体
5. 调度实例的job队列,管理多个job
6. 标记该调度实体禁止任务入队,在flush队列任务或者删除调度时,会用到这个字段,将其设置为true
drm_sched_rq
struct drm_sched_rq {
struct drm_gpu_scheduler *sched; /* 1 */
struct list_head entities; /* 2 */
struct drm_sched_entity *current_entity; /* 3 */
};
1. 运行队列所属的调度器
2. 运行队列管理的调度实体链表投
3. 当前正在处理的调度实体
drm_gpu_scheduler
struct drm_gpu_scheduler {
const struct drm_sched_backend_ops *ops; /* 1 */
uint32_t hw_submission_limit; /* 2 */
long timeout; /* 3 */
struct delayed_work work_tdr; /* 4 */
const char *name; /* 5 */
struct drm_sched_rq sched_rq[DRM_SCHED_PRIORITY_MAX]; /* 5 */
wait_queue_head_t wake_up_worker; /* 6 */
wait_queue_head_t job_scheduled; /* 7 */
atomic_t hw_rq_count; /* 8 */
struct task_struct *thread; /* 9 */
};
1. 调度器执行任务的回调,核心成员就是run_job,每个IP核上的ring buffer处理job的方式可能不一样,调度器真正执行job的时候就调用ops的run_job函数
2. 允许调度器同时执行job任务的上限,只有当前调度器执行的任务小于这个值是,才能取出job执行
3. 允许调度执行任务的最长时间,如果任务执行时间超时,内核会调用超时回调处理函数drm_sched_job_timedout。这个功能通过内核的延时工作队列实现,其初始化在内核线程初始化中完成
4. timeout超时工作队列
5. 调度器管理的运行队列,每个运行队列有一个或者多个调度实体,每个实体有一个或者多个调度job
6. 当调度队列是一个内核线程,没有任务处理时它进入睡眠状态,调度队列通过该等待队列成员休眠,当驱动有job到达时,通过此运行队列唤醒调度队列内核线程
7. 当其它线程想要flush一个调度实体,让它上面的所有任务都执行完并且禁止新的任务入队,会等待在这个队列上。调度器每次从调度实体的任
务队列中取出任务执行之后,队列中就少了一个任务,出现一个队列清空的可能时机,这时调度器会唤醒等待在job_scheduled上面的线程。
8. 当前调度器处理的job个数,开始执行job时计数加1,完成时减1
9. 调度队列是个内核线程,thread指向线程的结构体
流程
- GPU处理任务的调度流程从ioctl回调函数
amdgpu_cs_ioctl开始介绍,当用户态驱动打开/dev/dri/cardX下发DRM_IOCTL_AMDGPU_CS命令字时,会触发该函数,内核态ioctl命令字接口定义如下:
const struct drm_ioctl_desc amdgpu_ioctls_kms[] = {
......
DRM_IOCTL_DEF_DRV(AMDGPU_CS, amdgpu_cs_ioctl, DRM_AUTH|DRM_RENDER_ALLOW)
......
}
流程图
整体流程
amdgpu_cs_ioctl函数非常复杂,我们首先分析函数本身,提炼出几个重要的步骤,再进一步分析下去
int amdgpu_cs_ioctl(struct drm_device *dev, void *data, struct drm_file *filp)
{
struct amdgpu_device *adev = dev->dev_private;
union drm_amdgpu_cs *cs = data;
struct amdgpu_cs_parser parser = {};
parser.adev = adev;
parser.filp = filp;
amdgpu_cs_parser_init(&parser, data); /* 1 */
amdgpu_cs_ib_fill(adev, &parser); /* 2 */
amdgpu_cs_dependencies(adev, &parser); /* 3 */
amdgpu_cs_parser_bos(&parser, data);
amdgpu_cs_vm_handling(&parser);
amdgpu_cs_submit(&parser, cs); /* 4 */
}
1. 解析用户态下发的信息,主要是将下发渲染命令存放到内核态的chunk结构中,并初始化一个任务,用作之后提交
2. 从chunk中解析得到数据,将其填充到任务的ib中,当调度器执行一个任务时,可以找到该任务相关的渲染命令。除了填充任务,这里还会初始
化任务的调度实体,任务毕竟和具体业务相关,要把它放到调度队列上,需要一个调度队列可以识别的调度实体
3. 待分析
4. 将渲染命令封装成任务并且创建调度实体之后,就是把调度实体放到调度队列上,通知调度器工作了
保存渲染命令
static int amdgpu_cs_parser_init(struct amdgpu_cs_parser *p, union drm_amdgpu_cs *cs)
{
struct amdgpu_fpriv *fpriv = p->filp->driver_priv;
struct amdgpu_vm *vm = &fpriv->vm;
uint64_t *chunk_array_user;
uint64_t *chunk_array;
chunk_array = kmalloc_array(cs->in.num_chunks, sizeof(uint64_t), GFP_KERNEL); /* 1 */
p->ctx = amdgpu_ctx_get(fpriv, cs->in.ctx_id);
/* get chunks */
chunk_array_user = u64_to_user_ptr(cs->in.chunks);
copy_from_user(chunk_array, chunk_array_user, /* 2 */
sizeof(uint64_t)*cs->in.num_chunks)
p->nchunks = cs->in.num_chunks; /* 3 */
p->chunks = kmalloc_array(p->nchunks, sizeof(struct amdgpu_cs_chunk), /* 4 */
GFP_KERNEL);
for (i = 0; i < p->nchunks; i++) { /* 5 */
......
p->chunks[i].chunk_id = user_chunk.chunk_id;
p->chunks[i].length_dw = user_chunk.length_dw;
copy_from_user(p->chunks[i].kdata, cdata, size)
......
}
}
amdgpu_job_alloc(p->adev, num_ibs, &p->job, vm); /* 6 */
......
}
1. 分配存放用户态数据地址的指针数组,空间大小由用户态下发的数据决定,这里是cs->in.num_chunks个
2. 拷贝用户态数据的指针到内核态的指针数组
3. 使用用户态数据初始化parser的部分结构
4. 分配真正的保存用户态数据的空间,大小是amdgpu_cs_chunk,个数是num_chunks个,为保存用户态数据做准备
5. 依次拷贝每个chunk的数据,这之后,用户态的chunk数据已经全部保存到内核parser的chunk中
6. 初始化本次提交的job
初始化job
- job初始化是在parser过程中完成的,它由一个调度实体的job_queue管理,一个调度实体中可以有多个job
int amdgpu_job_alloc(struct amdgpu_device *adev, unsigned num_ibs,
struct amdgpu_job **job, struct amdgpu_vm *vm)
{
size_t size = sizeof(struct amdgpu_job); /* 1 */
size += sizeof(struct amdgpu_ib) * num_ibs;
*job = kzalloc(size, GFP_KERNEL);
/*
* Initialize the scheduler to at least some ring so that we always
* have a pointer to adev.
*/
(*job)->base.sched = &adev->rings[0]->sched; /* 2 */
(*job)->ibs = (void *)&(*job)[1]; /* 3 */
(*job)->num_ibs = num_ibs;
......
}
1. 为job分配空间,分配的大小是job的大小和num_ibs个amdgpu_ib的大小,从这里可以看出,job结构体下面还挂着num_ibs,因此需要这么多空间
2. 初始化job所在的调度器,将其默认指向GPU IP设备上的第一个ring buffer调度队列
3. 设置ibs,将其指向amdgpu_job的尾部,这样内核多分出amdgpu_job的空间就可以用作存放ibs,之后,job的ibs会被填入渲染命令
填充IB
- 解析parser中从用户态拷贝的chunk数据,将它放到任务的ibs数组中,这样任务被调度的时候,可以访问这些ibs
static int amdgpu_cs_ib_fill(struct amdgpu_device *adev,
struct amdgpu_cs_parser *parser)
{
struct amdgpu_ring *ring;
for (i = 0, j = 0; i < parser->nchunks && j < parser->job->num_ibs; i++) { /* 1 */
struct amdgpu_cs_chunk *chunk;
struct amdgpu_ib *ib;
struct drm_amdgpu_cs_chunk_ib *chunk_ib;
struct drm_sched_entity *entity;
chunk = &parser->chunks[i]; /* 2 */
ib = &parser->job->ibs[j];
chunk_ib = (struct drm_amdgpu_cs_chunk_ib *)chunk->kdata; /* 3 */
amdgpu_ctx_get_entity(parser->ctx, chunk_ib->ip_type, /* 4 */
chunk_ib->ip_instance, chunk_ib->ring,&entity);
if (parser->entity && parser->entity != entity) /* 5 */
return -EINVAL;
/* Return if there is no run queue associated with this entity.
* Possibly because of disabled HW IP*/
if (entity->rq == NULL) /* 6 */
return -EINVAL;
parser->entity = entity; /* 7 */
ring = to_amdgpu_ring(entity->rq->sched);
r = amdgpu_ib_get(adev, vm, ring->funcs->parse_cs ?
chunk_ib->ib_bytes : 0, ib);
ib->gpu_addr = chunk_ib->va_start; /* 8 */
ib->length_dw = chunk_ib->ib_bytes / 4;
ib->flags = chunk_ib->flags;
j++;
}
......
}
1. 针对每个chunk,依次读取它关联的数据,将其填充到job的ibs数组中
2. 分别获取chunk地址和job中存放ib的地址,我们的主要任务就是让ibs数组中的每个ib指向这里的每个chunk
3. 取出chunk中包含的数据所在地址
4. 一个chunk对应着一个ring buffer,一次提交的所有渲染命令,必须保证是往同一个ring buffer上提交的,这里根据chunk对应的IP类型核ring
buffer索引,可以确认这个chunk上的渲染命令是往哪个IP核的哪个ring buffer上提交。对于每个IP核上的ring buffer,每个上下文都有一个对应的
调度实体。这里会通过chunk所在ring buffer的类型取获取这个实体,如果没有,就会创建
5. 获取到调度实体之后,需要比较各个chunk的调度实体是否一样,如果不一样,说明多个chunk会提交渲染命令到不同的ring buffer,不允许这
样,同时也能看到,一个提交的上下文只对应唯一的ring buffer和调度实体
6. 如果调度实体上没有运行队列,返回出错
7. 将调度实体放到parser上,所有chunk都使用这个调度实体
8. 填写ib的地址,将其设置指向一个chunk_ib,这个本函数的核心动作
初始化entity
- 调度实体的初始化在
amdgpu_ctx_get_entity中实现,当不能获取entity时,就会创建一个
int amdgpu_ctx_get_entity(struct amdgpu_ctx *ctx, u32 hw_ip, u32 instance,
u32 ring, struct drm_sched_entity **entity)
{
if (hw_ip >= AMDGPU_HW_IP_NUM) { /* 1 */
DRM_ERROR("unknown HW IP type: %d\n", hw_ip);
return -EINVAL;
}
if (ring >= amdgpu_ctx_num_entities[hw_ip]) { /* 2 */
DRM_DEBUG("invalid ring: %d %d\n", hw_ip, ring);
return -EINVAL;
}
if (ctx->entities[hw_ip][ring] == NULL) { /* 3 */
amdgpu_ctx_init_entity(ctx, hw_ip, ring);
}
*entity = &ctx->entities[hw_ip][ring]->entity; /* 4 */
}
1. AMD GPU硬件IP模块只有AMDGPU_HW_IP_NUM个,如果超出这个范围,认为是无法识别的IP模块
2. 每个IP模块上的ring buffer只有amdgpu_ctx_num_entities[hw_ip]个,超出后也认为无法识别
3. 如果提交上下文中没有对应的调度实体,就创建一个,从这里可以看到,每个提交上下都可以拥有一个entity,这里说是创建,实际上在内部是
引用,因为每个IP核的ring buffer上有调度器,调度器管理了调度队列,我们只需要把调度器实体所在的运行队列指向调度器的运行队列就可以了
4. 将找到的调度实体返回给调用者
- 继续分析调度实体的初始化函数
amdgpu_ctx_init_entity
static int amdgpu_ctx_init_entity(struct amdgpu_ctx *ctx, const u32 hw_ip, const u32 ring)
{
struct amdgpu_ctx_entity *entity;
struct drm_gpu_scheduler **scheds = NULL, *sched = NULL;
unsigned num_scheds = 0;
entity = kcalloc(1, offsetof(typeof(*entity), fences[amdgpu_sched_jobs]), /* 1 */
GFP_KERNEL);
switch (hw_ip) { /* 2 */
case AMDGPU_HW_IP_GFX:
sched = &adev->gfx.gfx_ring[0].sched;
scheds = &sched;
num_scheds = 1;
break;
case AMDGPU_HW_IP_COMPUTE:
......
drm_sched_entity_init(&entity->entity, priority, scheds, num_scheds,&ctx->guilty); /* 3 */
ctx->entities[hw_ip][ring] = entity; /* 4 */
1. 分配entity空间
2. 根据chunk所在的IP,找到对应ring buffer上所有调度器的基地址
3. 初始化entity
4. 将初始化好的entity放到GPU渲染上下文中amdgpu_ctx
- 分析
drm_sched_entity_init,它的核心操作就是设置entity的运行队列,将其指向对应ring buffer调度器上维护的队列中,注意,这里我们看到的是将entity上的运行队列指向了IP核上的第一个ring buffer的调度器,后面会根据调度器上的任务数,选择合适的运行队列
drm_sched_entity_init
entity->rq = &sched_list[0]->sched_rq[entity->priority];
提交任务
static int amdgpu_cs_submit(struct amdgpu_cs_parser *p, union drm_amdgpu_cs *cs)
{
struct drm_sched_entity *entity = p->entity; /* 1 */
struct amdgpu_job *job;
job = p->job;
drm_sched_job_init(&job->base, entity, &fpriv->vm); /* 2 */
drm_sched_entity_select_rq(entity)
sched = entity->rq->sched;
job->sched = sched;
job->entity = entity;
job->s_priority = entity->rq - sched->sched_rq;
drm_sched_entity_push_job(&job->base, entity); /* 3 */
......
}
1. 获取解析器中之前初始化的调度实体以及任务
2. 初始化调度器要用到的job,drm_sched_job,它的核心任务是设置任务的调度器,调度实体,以及任务优先机,同时还会重新为调度实体选择
合适的运行队列
3. 将调度job添加到调度实体的job队列中,之后job的选择和执行就交给调度器了
内核线程初始化
- GPU的调度器以内核线程的形式存在于GPU IP核的ring buffer上,因此内核线程的创建是在IP核初始化的时候,我们选取GPU的GFX IP分析,它的初始化函数是
gfx_v10_0_gfx_ring_init
gfx_v10_0_gfx_ring_init
sprintf(ring->name, "gfx_%d.%d.%d", ring->me, ring->pipe, ring->queue) /* 1 */
amdgpu_ring_init
amdgpu_fence_driver_init_ring
drm_sched_init(&ring->sched, &amdgpu_sched_ops, /* 2 */
num_hw_submission, amdgpu_job_hang_limit,
timeout, ring->name);
sched->ops = ops;
sched->hw_submission_limit = hw_submission;
sched->name = name;
sched->timeout = timeout;
sched->hang_limit = hang_limit;
INIT_DELAYED_WORK(&sched->work_tdr, drm_sched_job_timedout); /* 3 */
sched->thread = kthread_run(drm_sched_main, sched, sched->name) /* 4 */
const struct drm_sched_backend_ops amdgpu_sched_ops = {
.run_job = amdgpu_job_run, /* 5 */
.timedout_job = amdgpu_job_timedout, /* 6 */
};
1. 设置ring buffer名字,这个名字也是调度器内核线程的名字
2. 初始化内核调度器
3. 初始化内核工作队列,用户处理任务调度超时的情况
4. 启动调度器内核线程
5. 调度器运执行任务时调用的回调函数
6. 当调度器执行任务超时,调用的超时处理回调函数
内核线程任务调度
static int drm_sched_main(void *param)
{
struct sched_param sparam = {.sched_priority = 1}; /* 1 */
sched_setscheduler(current, SCHED_FIFO, &sparam);
while (!kthread_should_stop()) {
wait_event_interruptible(sched->wake_up_worker, /* 2 */
(cleanup_job = drm_sched_get_cleanup_job(sched)) ||
(!drm_sched_blocked(sched) &&
(entity = drm_sched_select_entity(sched))) ||
kthread_should_stop());
sched_job = drm_sched_entity_pop_job(entity); /* 3 */
atomic_inc(&sched->hw_rq_count); /* 4 */
fence = sched->ops->run_job(sched_job); /* 5 */
......
}
1. 设置内核线程的调度策略为先入先出,使用的是实时的调度类,比完全公平调度类的优先级要高,并且这个内核线程在一个调度周期内如果没有
执行完是不会被打断的,保证了其执行任务的连续性
2. 在没有任务的情况下,内核线程通常睡在等待队列wake_up_worker上,当有任务到达的时候会被唤醒或者条件满足的时候被唤醒
3. 从调度实体的job队列中取出一个job,准备执行
4. 执行之前将hw_rq_count计数器加1
5. 运行任务,对于amdgpu驱动,对应的回调函数是amdgpu_job_run
- 调度实体的选择在drm_sched_select_entity中实现,继续分析
drm_sched_select_entity
drm_sched_ready /* 6 */
return atomic_read(&sched->hw_rq_count) < sched->hw_submission_limit;
/* Kernel run queue has higher priority than normal run queue*/
for (i = DRM_SCHED_PRIORITY_MAX - 1; i >= DRM_SCHED_PRIORITY_MIN; i--) { /* 7 */
entity = drm_sched_rq_select_entity(&sched->sched_rq[i]);
}
static struct drm_sched_entity *
drm_sched_rq_select_entity(struct drm_sched_rq *rq)
{
struct drm_sched_entity *entity;
entity = rq->current_entity;
if (entity) {
list_for_each_entry_continue(entity, &rq->entities, list) { /* 8 */
if (drm_sched_entity_is_ready(entity)) {
rq->current_entity = entity;
reinit_completion(&entity->entity_idle);
spin_unlock(&rq->lock);
return entity;
}
}
}
list_for_each_entry(entity, &rq->entities, list) { /* 9 */
if (drm_sched_entity_is_ready(entity)) {
rq->current_entity = entity;
reinit_completion(&entity->entity_idle);
spin_unlock(&rq->lock);
return entity;
}
}
}
6. 在选择调度实体前判断是否满足条件,如果当前执行的任务小于允许执行的任务数上限,才满足条件,否则选取调度实体为空,不运行任务。这里的
ready只有一个判断条件,就是当前运行的Job数是否超过上限,如果超过则不满足条件。
7. 根据调度实体的优先级,从高到低,从优先级对应的运行队列中选取合适的调度实体,返回。从这里看,调度实体是按照优先级选择的。如果一个优
先级队列中有多个调度实体怎么办呢,分析drm_sched_rq_select_entity函数
8. 首先遍历运行队列上的调度实体,从当前运行的调度实体之后开始,往下遍历,查找合适的第一个调度实体
9. 如果没有找到从当前运行的调度实体之后找到,就从运行队列最开始往下遍历,查找第一个合适的调度实体,从这里可以看到,调度器对调度实体的
选择是通过轮转的方式进行的。依次调用一个运行队列中的每个调度实体。如果当前已经有job在执行并且没有超过上限,调度器仍然可以从运行队列中
选择一个job,然后执行。这个时候,GPU内部可能发生上下文切换,之前没有运行完的job对应的上下文可能会被切换出去,给当前job让路。
执行任务
- 调度器从运行队列中选择优先级最高的entity,以FIFO的顺序从entity的任务队列中取出job,调用调度器初始化时注册的任务执行回调函数,执行任务。对于amdgpu上的调度器,对应的回调操作之前已经之前已经介绍,如下:
const struct drm_sched_backend_ops amdgpu_sched_ops = {
.run_job = amdgpu_job_run,
.timedout_job = amdgpu_job_timedout,
};
amdgpu_job_run是执行任务的回调,amdgpu_job_timedout是执行任务超时的回调。分析amdgpu_job_run的实现,它主要调用amdgpu_ib_schedule函数提交存放渲染命令的IB,其核心步骤如下:
int amdgpu_ib_schedule(struct amdgpu_ring *ring, unsigned num_ibs,
struct amdgpu_ib *ibs, struct amdgpu_job *job,
struct dma_fence **f)
{
alloc_size = ring->funcs->emit_frame_size + num_ibs * /* 1 */
ring->funcs->emit_ib_size;
amdgpu_ring_alloc(ring, alloc_size); /* 2 */
amdgpu_ring_commit(ring); /* 3 */
}
1. 计算IB在Ring Buffer的总大小,为后面更新CPU在Ring Buffer上的写偏移做准备
2. 更新CPU的在Ring Buffer上的写偏移,之前我们已经将渲染命令放到IB上,但还没有更新写偏移,因此不会触发GPU的读偏移往前移动,这里
的分配动作是把IB的空间记录下来,并且保存原来的的写偏移方便之后出错的回退。
3. 更新CPU的写偏移指针,通知GPU执行新的渲染命令